 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMx2M: Masked Cross-Modality Modeling in Domain Adaptation for 3D Semantic Segmentation
Jul 09, 2023Existing methods of cross-modal domain adaptation for 3D semantic segmentation predict results only via 2D-3D complementarity that is obtained by cross-modal feature matching. However, as lacking supervision in the target domain, the complementarity is not always reliable. The results are not ideal when the domain gap is large. To solve the problem of lacking supervision, we introduce masked modeling into this task and propose a method Mx2M, which utilizes masked cross-modality modeling to reduce the large domain gap. Our Mx2M contains two components. One is the core solution, cross-modal removal and prediction (xMRP), which makes the Mx2M adapt to various scenarios and provides cross-modal self-supervision. The other is a new way of cross-modal feature matching, the dynamic cross-modal filter (DxMF) that ensures the whole method dynamically uses more suitable 2D-3D complementarity. Evaluation of the Mx2M on three DA scenarios, including Day/Night, USA/Singapore, and A2D2/SemanticKITTI, brings large improvements over previous methods on many metrics.
Unsupervised Sentence Representation Learning with Frequency-induced Adversarial Tuning and Incomplete Sentence Filtering
May 15, 2023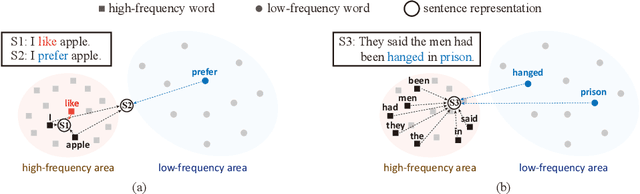
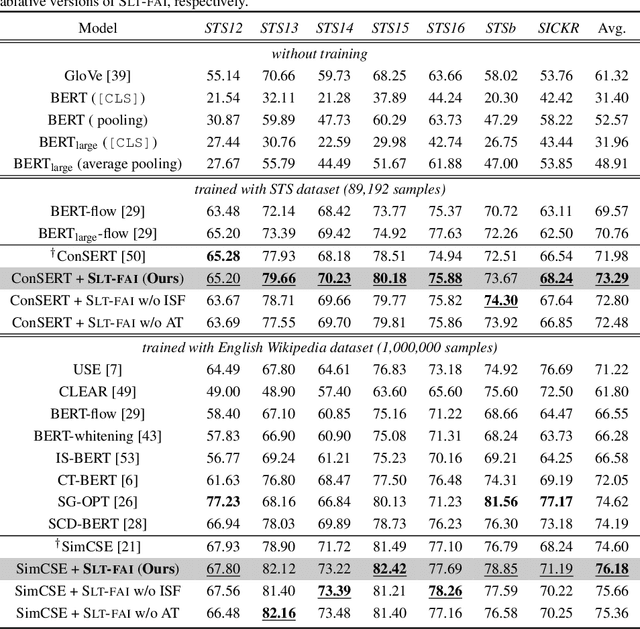

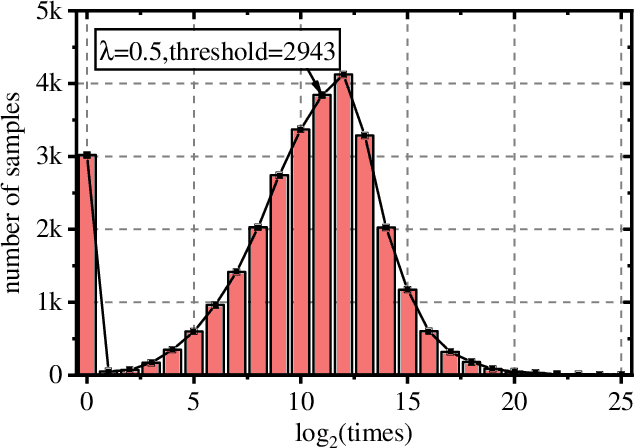
Pre-trained Language Model (PLM) is nowadays the mainstay of Unsupervised Sentence Representation Learning (USRL). However, PLMs are sensitive to the frequency information of words from their pre-training corpora, resulting in anisotropic embedding space, where the embeddings of high-frequency words are clustered but those of low-frequency words disperse sparsely. This anisotropic phenomenon results in two problems of similarity bias and information bias, lowering the quality of sentence embeddings. To solve the problems, we fine-tune PLMs by leveraging the frequency information of words and propose a novel USRL framework, namely Sentence Representation Learning with Frequency-induced Adversarial tuning and Incomplete sentence filtering (SLT-FAI). We calculate the word frequencies over the pre-training corpora of PLMs and assign words thresholding frequency labels. With them, (1) we incorporate a similarity discriminator used to distinguish the embeddings of high-frequency and low-frequency words, and adversarially tune the PLM with it, enabling to achieve uniformly frequency-invariant embedding space; and (2) we propose a novel incomplete sentence detection task, where we incorporate an information discriminator to distinguish the embeddings of original sentences and incomplete sentences by randomly masking several low-frequency words, enabling to emphasize the more informative low-frequency words. Our SLT-FAI is a flexible and plug-and-play framework, and it can be integrated with existing USRL techniques. We evaluate SLT-FAI with various backbones on benchmark datasets. Empirical results indicate that SLT-FAI can be superior to the existing USRL baselines. Our code is released in \url{https://github.com/wangbing1416/SLT-FAI}.
Self-Attention Recurrent Network for Saliency Detection
Aug 05, 2018

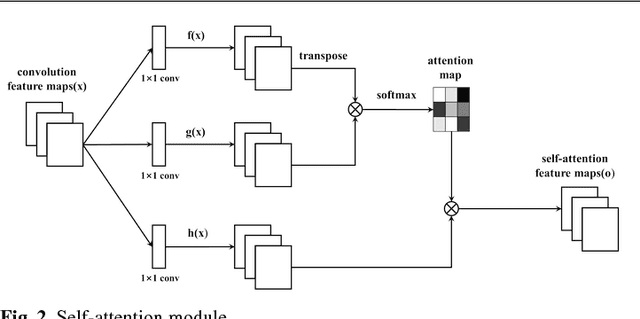
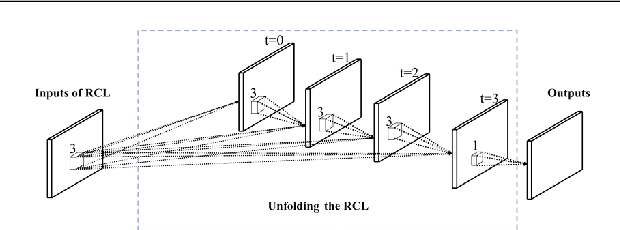
Feature maps in deep neural network generally contain different semantics. Existing methods often omit their characteristics that may lead to sub-optimal results. In this paper, we propose a novel end-to-end deep saliency network which could effectively utilize multi-scale feature maps according to their characteristics. Shallow layers often contain more local information, and deep layers have advantages in global semantics. Therefore, the network generates elaborate saliency maps by enhancing local and global information of feature maps in different layers. On one hand, local information of shallow layers is enhanced by a recurrent structure which shared convolution kernel at different time steps. On the other hand, global information of deep layers is utilized by a self-attention module, which generates different attention weights for salient objects and backgrounds thus achieve better performance. Experimental results on four widely used datasets demonstrate that our method has advantages in performance over existing algorithms.