 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency guided deep network for weakly-supervised image segmentation
Oct 19, 2018

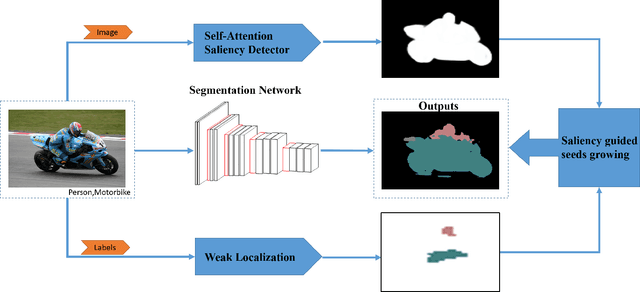

Weakly-supervised image segmentation is an important task in computer vision. A key problem is how to obtain high quality objects location from image-level category. Classification activation mapping is a common method which can be used to generate high-precise object location cues. However these location cues are generally very sparse and small such that they can not provide effective information for image segmentation. In this paper, we propose a saliency guided image segmentation network to resolve this problem. We employ a self-attention saliency method to generate subtle saliency maps, and render the location cues grow as seeds by seeded region growing method to expand pixel-level labels extent. In the process of seeds growing, we use the saliency values to weight the similarity between pixels to control the growing. Therefore saliency information could help generate discriminative object regions, and the effects of wrong salient pixels can be suppressed efficiently. Experimental results on a common segmentation dataset PASCAL VOC2012 demonstrate the effectiveness of our method.
Self-Attention Recurrent Network for Saliency Detection
Aug 05, 2018

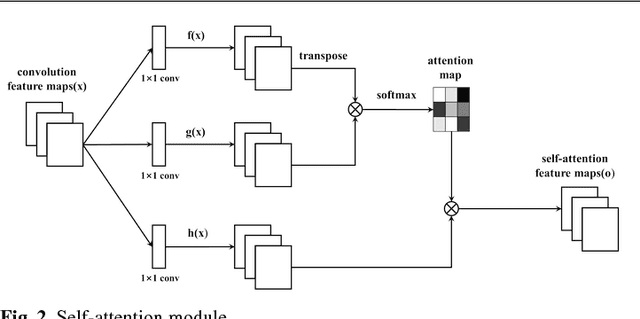
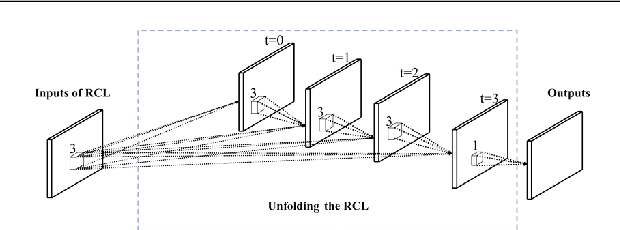
Feature maps in deep neural network generally contain different semantics. Existing methods often omit their characteristics that may lead to sub-optimal results. In this paper, we propose a novel end-to-end deep saliency network which could effectively utilize multi-scale feature maps according to their characteristics. Shallow layers often contain more local information, and deep layers have advantages in global semantics. Therefore, the network generates elaborate saliency maps by enhancing local and global information of feature maps in different layers. On one hand, local information of shallow layers is enhanced by a recurrent structure which shared convolution kernel at different time steps. On the other hand, global information of deep layers is utilized by a self-attention module, which generates different attention weights for salient objects and backgrounds thus achieve better performance. Experimental results on four widely used datasets demonstrate that our method has advantages in performance over existing algorithms.