 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Calibration of Multi Hand-Eye Robot System Based on Graph
May 04, 2023



Precise calibration is the basis for the vision-guided robot system to achieve high-precision operations. Systems with multiple eyes (cameras) and multiple hands (robots) are particularly sensitive to calibration errors, such as micro-assembly systems. Most existing methods focus on the calibration of a single unit of the whole system, such as poses between hand and eye, or between two hands. These methods can be used to determine the relative pose between each unit, but the serialized incremental calibration strategy cannot avoid the problem of error accumulation in a large-scale system. Instead of focusing on a single unit, this paper models the multi-eye and multi-hand system calibration problem as a graph and proposes a method based on the minimum spanning tree and graph optimization. This method can automatically plan the serialized optimal calibration strategy in accordance with the system settings to get coarse calibration results initially. Then, with these initial values, the closed-loop constraints are introduced to carry out global optimization. Simulation experiments demonstrate the performance of the proposed algorithm under different noises and various hand-eye configurations. In addition, experiments on real robot systems are presented to further verify the proposed method.
Patch Similarity Aware Data-Free Quantization for Vision Transformers
Mar 04, 2022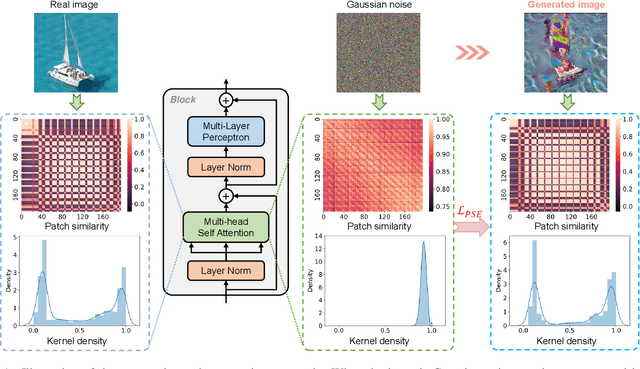
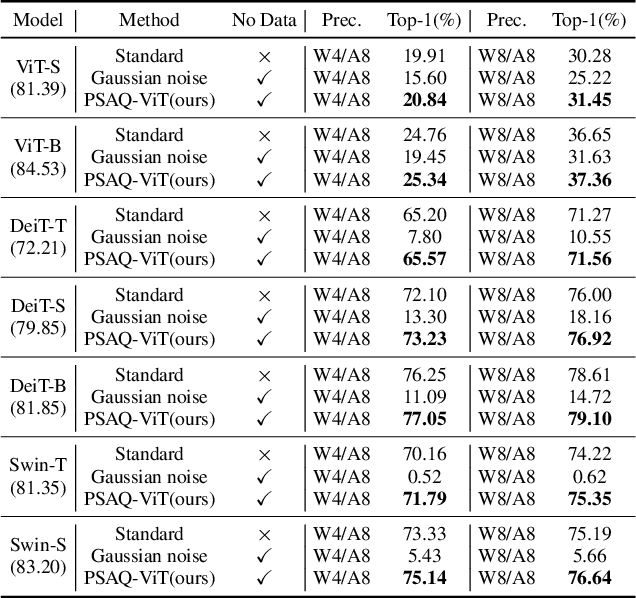
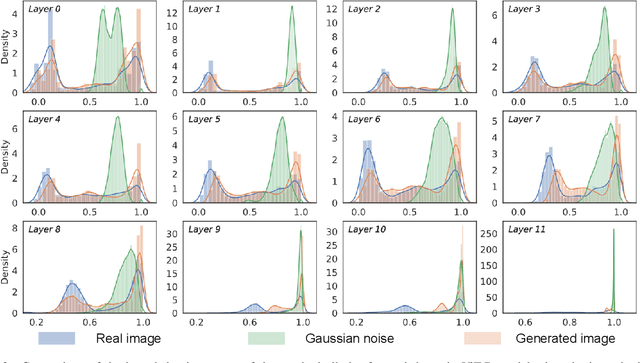
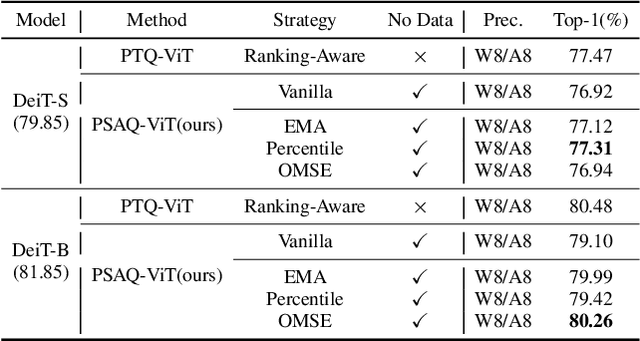
Vision transformers have recently gained great success on various computer vision tasks; nevertheless, their high model complexity makes it challenging to deploy on resource-constrained devices. Quantization is an effective approach to reduce model complexity, and data-free quantization, which can address data privacy and security concerns during model deployment, has received widespread interest. Unfortunately, all existing methods, such as BN regularization, were designed for convolutional neural networks and cannot be applied to vision transformers with significantly different model architectures. In this paper, we propose PSAQ-ViT, a Patch Similarity Aware data-free Quantization framework for Vision Transformers, to enable the generation of "realistic" samples based on the vision transformer's unique properties for calibrating the quantization parameters. Specifically, we analyze the self-attention module's properties and reveal a general difference (patch similarity) in its processing of Gaussian noise and real images. The above insights guide us to design a relative value metric to optimize the Gaussian noise to approximate the real images, which are then utilized to calibrate the quantization parameters. Extensive experiments and ablation studies are conducted on various benchmarks to validate the effectiveness of PSAQ-ViT, which can even outperform the real-data-driven methods.