 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Similarity Aware Data-Free Quantization for Vision Transformers
Paper and Code
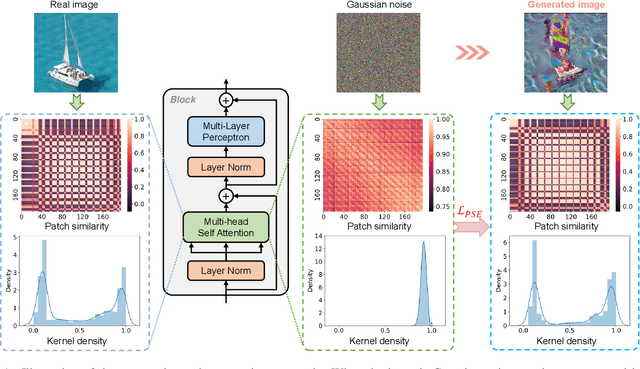
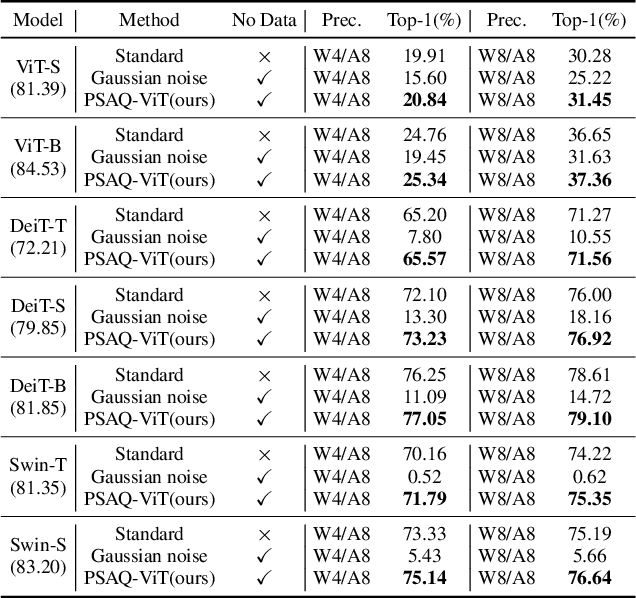
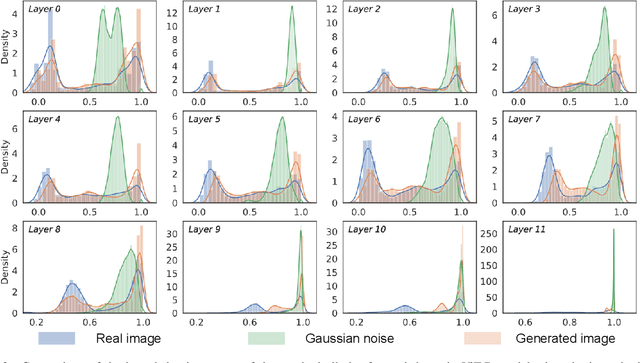
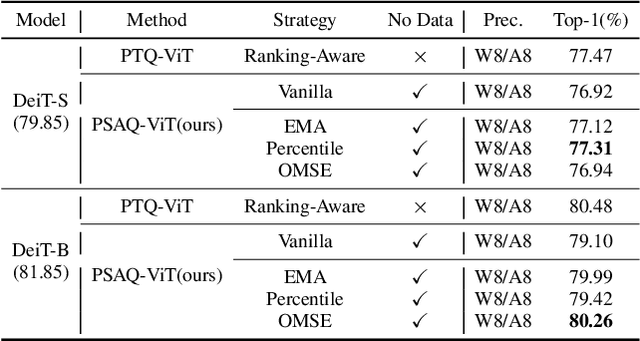
Vision transformers have recently gained great success on various computer vision tasks; nevertheless, their high model complexity makes it challenging to deploy on resource-constrained devices. Quantization is an effective approach to reduce model complexity, and data-free quantization, which can address data privacy and security concerns during model deployment, has received widespread interest. Unfortunately, all existing methods, such as BN regularization, were designed for convolutional neural networks and cannot be applied to vision transformers with significantly different model architectures. In this paper, we propose PSAQ-ViT, a Patch Similarity Aware data-free Quantization framework for Vision Transformers, to enable the generation of "realistic" samples based on the vision transformer's unique properties for calibrating the quantization parameters. Specifically, we analyze the self-attention module's properties and reveal a general difference (patch similarity) in its processing of Gaussian noise and real images. The above insights guide us to design a relative value metric to optimize the Gaussian noise to approximate the real images, which are then utilized to calibrate the quantization parameters. Extensive experiments and ablation studies are conducted on various benchmarks to validate the effectiveness of PSAQ-ViT, which can even outperform the real-data-driven methods.