 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllDayNav: Lifelong Navigation via Real-World Reinforcement Learning
Jun 09, 2026Lifelong embodied navigation in dynamic environments requires robots to form persistent scene understanding from fragmentary observations, which remains difficult for existing methods that rely on explicit maps or scene graphs and struggle to generalize beyond structured settings. We propose AllDayNav, a lifelong self-learning navigation framework that implicitly encodes scene dynamics into the billion-scale parameters of a large model via reinforcement learning, powered by a self-evolving multimodal memory that maintains and updates visual keyframes, semantic descriptions, and temporal context while autonomously generating open-vocabulary instructions, image goals, and structured rewards. Experiments in both synthetic and real-world environments across cross-room, cross-episode, and cross-task scenarios show that AllDayNav achieves success rates approaching $100\%$ and consistently surpasses strong map-based, VLM, and RL baselines in path efficiency and robustness, demonstrating implicit, memory-driven reinforcement learning as a scalable alternative to explicit mapping for reliable lifelong navigation.
TopoMesh: High-Fidelity Mesh Autoencoding via Topological Unification
Mar 25, 2026The dominant paradigm for high-fidelity 3D generation relies on a VAE-Diffusion pipeline, where the VAE's reconstruction capability sets a firm upper bound on generation quality. A fundamental challenge limiting existing VAEs is the representation mismatch between ground-truth meshes and network predictions: GT meshes have arbitrary, variable topology, while VAEs typically predict fixed-structure implicit fields (\eg, SDF on regular grids). This inherent misalignment prevents establishing explicit mesh-level correspondences, forcing prior work to rely on indirect supervision signals such as SDF or rendering losses. Consequently, fine geometric details, particularly sharp features, are poorly preserved during reconstruction. To address this, we introduce TopoMesh, a sparse voxel-based VAE that unifies both GT and predicted meshes under a shared Dual Marching Cubes (DMC) topological framework. Specifically, we convert arbitrary input meshes into DMC-compliant representations via a remeshing algorithm that preserves sharp edges using an L$\infty$ distance metric. Our decoder outputs meshes in the same DMC format, ensuring that both predicted and target meshes share identical topological structures. This establishes explicit correspondences at the vertex and face level, allowing us to derive explicit mesh-level supervision signals for topology, vertex positions, and face orientations with clear gradients. Our sparse VAE architecture employs this unified framework and is trained with Teacher Forcing and progressive resolution training for stable and efficient convergence. Extensive experiments demonstrate that TopoMesh significantly outperforms existing VAEs in reconstruction fidelity, achieving superior preservation of sharp features and geometric details.
NavGSim: High-Fidelity Gaussian Splatting Simulator for Large-Scale Navigation
Mar 16, 2026Simulating realistic environments for robots is widely recognized as a critical challenge in robot learning, particularly in terms of rendering and physical simulation. This challenge becomes even more pronounced in navigation tasks, where trajectories often extend across multiple rooms or entire floors. In this work, we present NavGSim, a Gaussian Splatting-based simulator designed to generate high-fidelity, large-scale navigation environments. Built upon a hierarchical 3D Gaussian Splatting framework, NavGSim enables photorealistic rendering in expansive scenes spanning hundreds of square meters. To simulate navigation collisions, we introduce a Gaussian Splatting-based slice technique that directly extracts navigable areas from reconstructed Gaussians. Additionally, for ease of use, we provide comprehensive NavGSim APIs supporting multi-GPU development, including tools for custom scene reconstruction, robot configuration, policy training, and evaluation. To evaluate NavGSim's effectiveness, we train a Vision-Language-Action (VLA) model using trajectories collected from NavGSim and assess its performance in both simulated and real-world environments. Our results demonstrate that NavGSim significantly enhances the VLA model's scene understanding, enabling the policy to handle diverse navigation queries effectively.
SPAN-Nav: Generalized Spatial Awareness for Versatile Vision-Language Navigation
Mar 10, 2026Recent embodied navigation approaches leveraging Vision-Language Models (VLMs) demonstrate strong generalization in versatile Vision-Language Navigation (VLN). However, reliable path planning in complex environments remains challenging due to insufficient spatial awareness. In this work, we introduce SPAN-Nav, an end-to-end foundation model designed to infuse embodied navigation with universal 3D spatial awareness using RGB video streams. SPAN-Nav extracts spatial priors across diverse scenes through an occupancy prediction task on extensive indoor and outdoor environments. To mitigate the computational burden, we introduce a compact representation for spatial priors, finding that a single token is sufficient to encapsulate the coarse-grained cues essential for navigation tasks. Furthermore, inspired by the Chain-of-Thought (CoT) mechanism, SPAN-Nav utilizes this single spatial token to explicitly inject spatial cues into action reasoning through an end-to end framework. Leveraging multi-task co-training, SPAN-Nav captures task-adaptive cues from generalized spatial priors, enabling robust spatial awareness to generalize even to the task lacking explicit spatial supervision. To support comprehensive spatial learning, we present a massive dataset of 4.2 million occupancy annotations that covers both indoor and outdoor scenes across multi-type navigation tasks. SPAN-Nav achieves state-of-the-art performance across three benchmarks spanning diverse scenarios and varied navigation tasks. Finally, real-world experiments validate the robust generalization and practical reliability of our approach across complex physical scenarios.
TrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
Oct 08, 2025Embodied Visual Tracking (EVT) is a fundamental ability that underpins practical applications, such as companion robots, guidance robots and service assistants, where continuously following moving targets is essential. Recent advances have enabled language-guided tracking in complex and unstructured scenes. However, existing approaches lack explicit spatial reasoning and effective temporal memory, causing failures under severe occlusions or in the presence of similar-looking distractors. To address these challenges, we present TrackVLA++, a novel Vision-Language-Action (VLA) model that enhances embodied visual tracking with two key modules, a spatial reasoning mechanism and a Target Identification Memory (TIM). The reasoning module introduces a Chain-of-Thought paradigm, termed Polar-CoT, which infers the target's relative position and encodes it as a compact polar-coordinate token for action prediction. Guided by these spatial priors, the TIM employs a gated update strategy to preserve long-horizon target memory, ensuring spatiotemporal consistency and mitigating target loss during extended occlusions. Extensive experiments show that TrackVLA++ achieves state-of-the-art performance on public benchmarks across both egocentric and multi-camera settings. On the challenging EVT-Bench DT split, TrackVLA++ surpasses the previous leading approach by 5.1 and 12, respectively. Furthermore, TrackVLA++ exhibits strong zero-shot generalization, enabling robust real-world tracking in dynamic and occluded scenarios.
TrackVLA: Embodied Visual Tracking in the Wild
May 29, 2025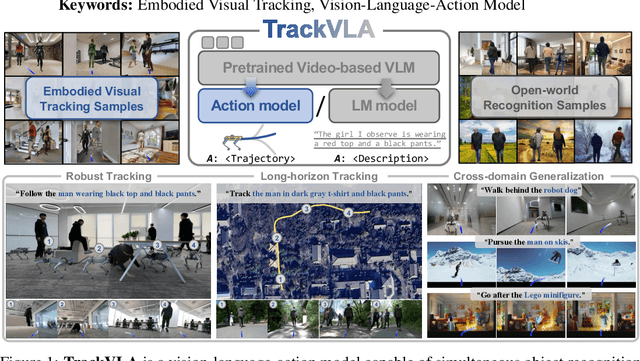

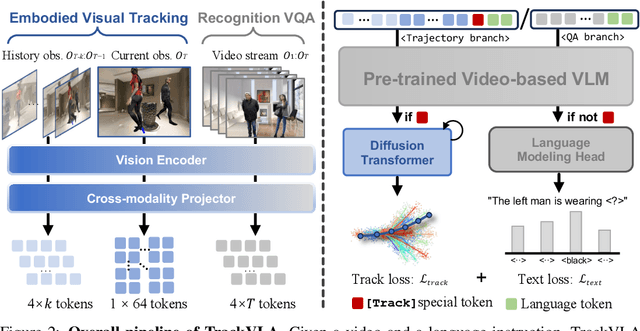
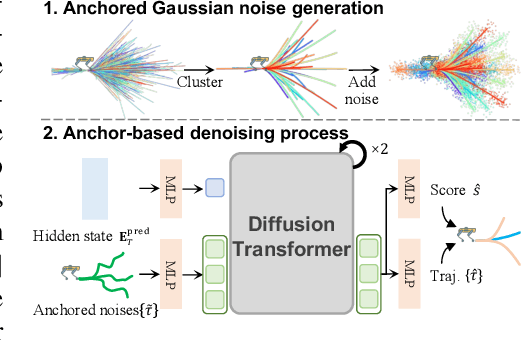
Embodied visual tracking is a fundamental skill in Embodied AI, enabling an agent to follow a specific target in dynamic environments using only egocentric vision. This task is inherently challenging as it requires both accurate target recognition and effective trajectory planning under conditions of severe occlusion and high scene dynamics. Existing approaches typically address this challenge through a modular separation of recognition and planning. In this work, we propose TrackVLA, a Vision-Language-Action (VLA) model that learns the synergy between object recognition and trajectory planning. Leveraging a shared LLM backbone, we employ a language modeling head for recognition and an anchor-based diffusion model for trajectory planning. To train TrackVLA, we construct an Embodied Visual Tracking Benchmark (EVT-Bench) and collect diverse difficulty levels of recognition samples, resulting in a dataset of 1.7 million samples. Through extensive experiments in both synthetic and real-world environments, TrackVLA demonstrates SOTA performance and strong generalizability. It significantly outperforms existing methods on public benchmarks in a zero-shot manner while remaining robust to high dynamics and occlusion in real-world scenarios at 10 FPS inference speed. Our project page is: https://pku-epic.github.io/TrackVLA-web.
SizeGS: Size-aware Compression of 3D Gaussians with Hierarchical Mixed Precision Quantization
Dec 08, 2024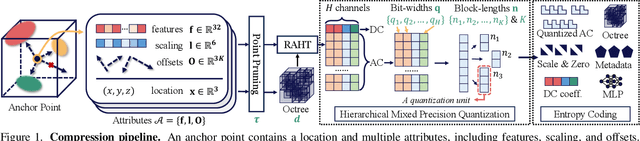
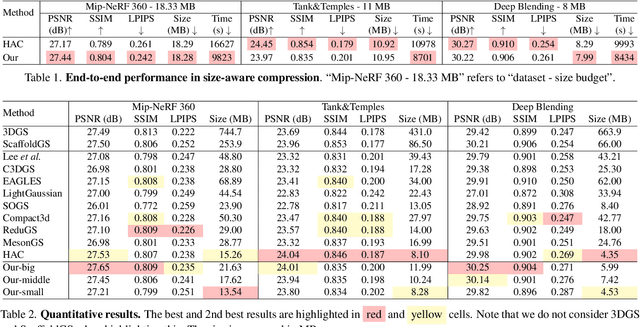
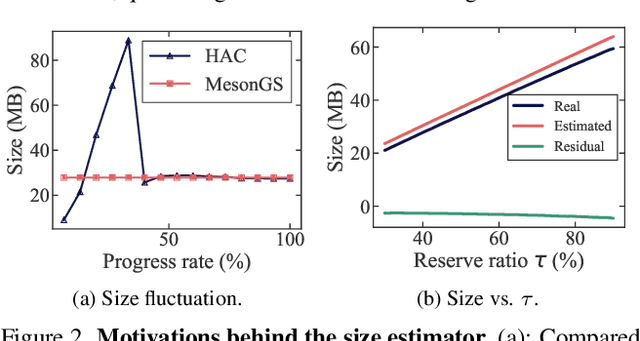

Effective compression technology is crucial for 3DGS to adapt to varying storage and transmission conditions. However, existing methods fail to address size constraints while maintaining optimal quality. In this paper, we introduce SizeGS, a framework that compresses 3DGS within a specified size budget while optimizing visual quality. We start with a size estimator to establish a clear relationship between file size and hyperparameters. Leveraging this estimator, we incorporate mixed precision quantization (MPQ) into 3DGS attributes, structuring MPQ in two hierarchical level -- inter-attribute and intra-attribute -- to optimize visual quality under the size constraint. At the inter-attribute level, we assign bit-widths to each attribute channel by formulating the combinatorial optimization as a 0-1 integer linear program, which can be efficiently solved. At the intra-attribute level, we divide each attribute channel into blocks of vectors, quantizing each vector based on the optimal bit-width derived at the inter-attribute level. Dynamic programming determines block lengths. Using the size estimator and MPQ, we develop a calibrated algorithm to identify optimal hyperparameters in just 10 minutes, achieving a 1.69$\times$ efficiency increase with quality comparable to state-of-the-art methods.
Robot Learning in the Era of Foundation Models: A Survey
Nov 24, 2023The proliferation of Large Language Models (LLMs) has s fueled a shift in robot learning from automation towards general embodied Artificial Intelligence (AI). Adopting foundation models together with traditional learning methods to robot learning has increasingly gained recent interest research community and showed potential for real-life application. However, there are few literatures comprehensively reviewing the relatively new technologies combined with robotics. The purpose of this review is to systematically assess the state-of-the-art foundation model techniques in the robot learning and to identify future potential areas. Specifically, we first summarized the technical evolution of robot learning and identified the necessary preliminary preparations for foundation models including the simulators, datasets, foundation model framework. In addition, we focused on the following four mainstream areas of robot learning including manipulation, navigation, planning, and reasoning and demonstrated how the foundation model techniques can be adopted in the above scenarios. Furthermore, critical issues which are neglected in the current literatures including robot hardware and software decoupling, dynamic data, generalization performance with the presence of human, etc. were discussed. This review highlights the state-of-the-art progress of foundation models in robot learning and future research should focus on multimodal interaction especially dynamics data, exclusive foundation models for robots, and AI alignment, etc.
Robust Learning-based Predictive Control for Constrained Nonlinear Systems
Nov 22, 2019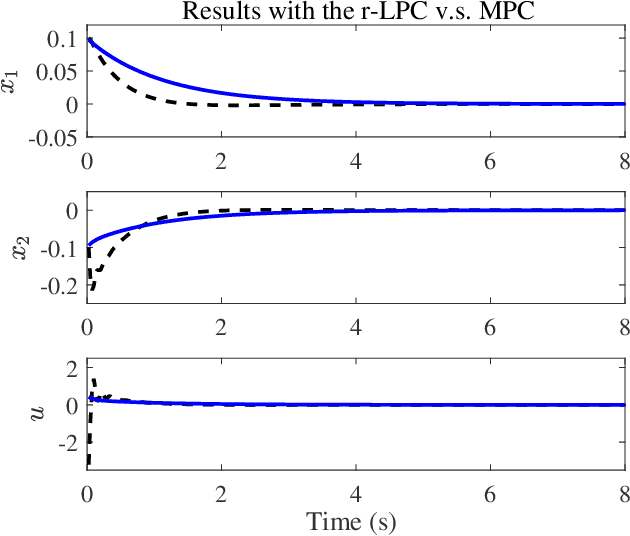

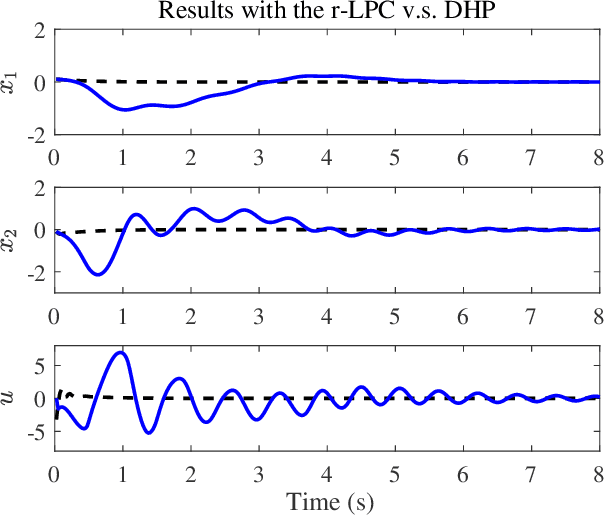
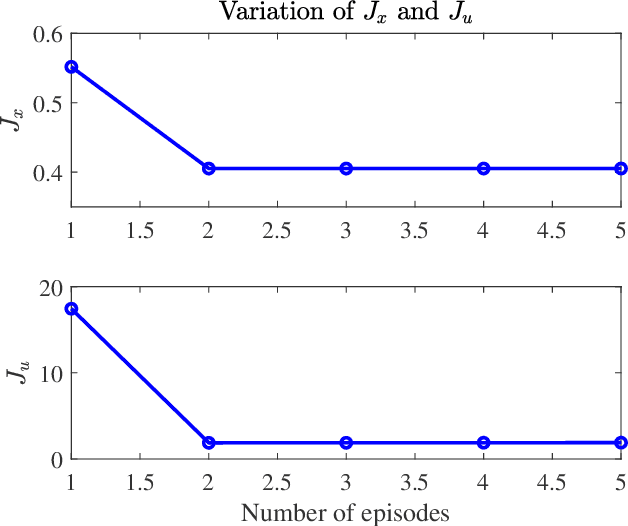
The integration of machine learning methods and Model Predictive Control (MPC) has received increasing attention in recent years. In general, learning-based predictive control (LPC) is promising to build data-driven models and solve the online optimization problem with lower computational costs. However, the robustness of LPC is difficult to be guaranteed since there will be uncertainties due to function approximation used in machine learning algorithms. In this paper, a novel robust learning-based predictive control (r-LPC) scheme is proposed for constrained nonlinear systems with unknown dynamics. In r-LPC, the Koopman operator is used to form a global linear representation of the unknown dynamics, and an incremental actor-critic algorithm is presented for receding horizon optimization. To realize the satisfaction of system constraints, soft logarithmic barrier functions are designed within the learning predictive framework. The recursive feasibility and stability of the closed-loop system are discussed under the convergence arguments of the approximation algorithms adopted. Also, the robustness property of r-LPC is analyzed theoretically by taking into consideration the existence of perturbations on the controller due to possible approximation errors. Simulation results with the proposed learning control approach for the data-driven regulation of a Van der Pol oscillator system have been reported, including the comparisons with a classic MPC and an infinite-horizon Dual Heuristic Programming (DHP) algorithm. The results show that the r-LPC significantly outperforms the DHP algorithm in terms of control performance and can be comparative to the MPC in terms of regulating control as well as energy consumption. Moreover, its average computational cost is much smaller than that with the MPC in the adopted environment.