 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphoGuard: A Morphology-Based Whole-Body Interactive Motion Controller
Apr 02, 2026Whole-body control (WBC) has demonstrated significant advantages in complex interactive movements of high-dimensional robotic systems. However, when a robot is required to handle dynamic multi-contact combinations along a single kinematic chain-such as pushing open a door with its elbow while grasping an object-it faces major obstacles in terms of complex contact representation and joint configuration coupling. To address this, we propose a new control approach that explicitly manages arbitrary contact combinations, aiming to endow robots with whole-body interactive capabilities. We develop a morphology-constrained WBC network (MorphoGuard)-which is trained on a self-constructed dual-arm physical and simulation platform. A series of model recommendation experiments are designed to systematically investigate the impact of backbone architecture, fusion strategy, and model scale on network performance. To evaluate the control performance, we adopt a multi-object interaction task as the benchmark, requiring the model to simultaneously manipulate multiple target objects to specified positions. Experimental results show that the proposed method achieves a contact point management error of approximately 1 cm, demonstrating its effectiveness in whole-body interactive control.
Morphogenetic Assembly and Adaptive Control for Heterogeneous Modular Robots
Feb 11, 2026This paper presents a closed-loop automation framework for heterogeneous modular robots, covering the full pipeline from morphological construction to adaptive control. In this framework, a mobile manipulator handles heterogeneous functional modules including structural, joint, and wheeled modules to dynamically assemble diverse robot configurations and provide them with immediate locomotion capability. To address the state-space explosion in large-scale heterogeneous reconfiguration, we propose a hierarchical planner: the high-level planner uses a bidirectional heuristic search with type-penalty terms to generate module-handling sequences, while the low level planner employs A* search to compute optimal execution trajectories. This design effectively decouples discrete configuration planning from continuous motion execution. For adaptive motion generation of unknown assembled configurations, we introduce a GPU accelerated Annealing-Variance Model Predictive Path Integral (MPPI) controller. By incorporating a multi stage variance annealing strategy to balance global exploration and local convergence, the controller enables configuration-agnostic, real-time motion control. Large scale simulations show that the type-penalty term is critical for planning robustness in heterogeneous scenarios. Moreover, the greedy heuristic produces plans with lower physical execution costs than the Hungarian heuristic. The proposed annealing-variance MPPI significantly outperforms standard MPPI in both velocity tracking accuracy and control frequency, achieving real time control at 50 Hz. The framework validates the full-cycle process, including module assembly, robot merging and splitting, and dynamic motion generation.
ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification
Jun 13, 2025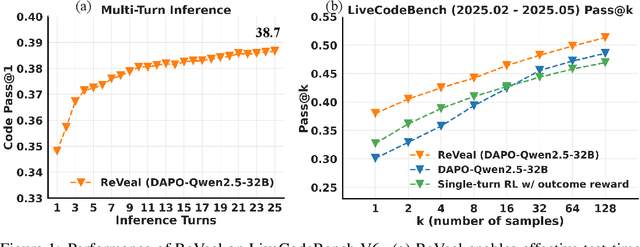



Recent advances in reinforcement learning (RL) with verifiable outcome rewards have significantly improved the reasoning capabilities of large language models (LLMs), especially when combined with multi-turn tool interactions. However, existing methods lack both meaningful verification signals from realistic environments and explicit optimization for verification, leading to unreliable self-verification. To address these limitations, we propose ReVeal, a multi-turn reinforcement learning framework that interleaves code generation with explicit self-verification and tool-based evaluation. ReVeal enables LLMs to autonomously generate test cases, invoke external tools for precise feedback, and improves performance via a customized RL algorithm with dense, per-turn rewards. As a result, ReVeal fosters the co-evolution of a model's generation and verification capabilities through RL training, expanding the reasoning boundaries of the base model, demonstrated by significant gains in Pass@k on LiveCodeBench. It also enables test-time scaling into deeper inference regimes, with code consistently evolving as the number of turns increases during inference, ultimately surpassing DeepSeek-R1-Zero-Qwen-32B. These findings highlight the promise of ReVeal as a scalable and effective paradigm for building more robust and autonomous AI agents.
Kaiwu: A Multimodal Manipulation Dataset and Framework for Robot Learning and Human-Robot Interaction
Mar 07, 2025



Cutting-edge robot learning techniques including foundation models and imitation learning from humans all pose huge demands on large-scale and high-quality datasets which constitute one of the bottleneck in the general intelligent robot fields. This paper presents the Kaiwu multimodal dataset to address the missing real-world synchronized multimodal data problems in the sophisticated assembling scenario,especially with dynamics information and its fine-grained labelling. The dataset first provides an integration of human,environment and robot data collection framework with 20 subjects and 30 interaction objects resulting in totally 11,664 instances of integrated actions. For each of the demonstration,hand motions,operation pressures,sounds of the assembling process,multi-view videos, high-precision motion capture information,eye gaze with first-person videos,electromyography signals are all recorded. Fine-grained multi-level annotation based on absolute timestamp,and semantic segmentation labelling are performed. Kaiwu dataset aims to facilitate robot learning,dexterous manipulation,human intention investigation and human-robot collaboration research.
SSFold: Learning to Fold Arbitrary Crumpled Cloth Using Graph Dynamics from Human Demonstration
Oct 24, 2024



Robotic cloth manipulation faces challenges due to the fabric's complex dynamics and the high dimensionality of configuration spaces. Previous methods have largely focused on isolated smoothing or folding tasks and overly reliant on simulations, often failing to bridge the significant sim-to-real gap in deformable object manipulation. To overcome these challenges, we propose a two-stream architecture with sequential and spatial pathways, unifying smoothing and folding tasks into a single adaptable policy model that accommodates various cloth types and states. The sequential stream determines the pick and place positions for the cloth, while the spatial stream, using a connectivity dynamics model, constructs a visibility graph from partial point cloud data of the self-occluded cloth, allowing the robot to infer the cloth's full configuration from incomplete observations. To bridge the sim-to-real gap, we utilize a hand tracking detection algorithm to gather and integrate human demonstration data into our novel end-to-end neural network, improving real-world adaptability. Our method, validated on a UR5 robot across four distinct cloth folding tasks with different goal shapes, consistently achieves folded states from arbitrary crumpled initial configurations, with success rates of 99\%, 99\%, 83\%, and 67\%. It outperforms existing state-of-the-art cloth manipulation techniques and demonstrates strong generalization to unseen cloth with diverse colors, shapes, and stiffness in real-world experiments.Videos and source code are available at: https://zcswdt.github.io/SSFold/
A Survey on Robotic Manipulation of Deformable Objects: Recent Advances, Open Challenges and New Frontiers
Dec 16, 2023Deformable object manipulation (DOM) for robots has a wide range of applications in various fields such as industrial, service and health care sectors. However, compared to manipulation of rigid objects, DOM poses significant challenges for robotic perception, modeling and manipulation, due to the infinite dimensionality of the state space of deformable objects (DOs) and the complexity of their dynamics. The development of computer graphics and machine learning has enabled novel techniques for DOM. These techniques, based on data-driven paradigms, can address some of the challenges that analytical approaches of DOM face. However, some existing reviews do not include all aspects of DOM, and some previous reviews do not summarize data-driven approaches adequately. In this article, we survey more than 150 relevant studies (data-driven approaches mainly) and summarize recent advances, open challenges, and new frontiers for aspects of perception, modeling and manipulation for DOs. Particularly, we summarize initial progress made by Large Language Models (LLMs) in robotic manipulation, and indicates some valuable directions for further research. We believe that integrating data-driven approaches and analytical approaches can provide viable solutions to open challenges of DOM.
Robot Learning in the Era of Foundation Models: A Survey
Nov 24, 2023The proliferation of Large Language Models (LLMs) has s fueled a shift in robot learning from automation towards general embodied Artificial Intelligence (AI). Adopting foundation models together with traditional learning methods to robot learning has increasingly gained recent interest research community and showed potential for real-life application. However, there are few literatures comprehensively reviewing the relatively new technologies combined with robotics. The purpose of this review is to systematically assess the state-of-the-art foundation model techniques in the robot learning and to identify future potential areas. Specifically, we first summarized the technical evolution of robot learning and identified the necessary preliminary preparations for foundation models including the simulators, datasets, foundation model framework. In addition, we focused on the following four mainstream areas of robot learning including manipulation, navigation, planning, and reasoning and demonstrated how the foundation model techniques can be adopted in the above scenarios. Furthermore, critical issues which are neglected in the current literatures including robot hardware and software decoupling, dynamic data, generalization performance with the presence of human, etc. were discussed. This review highlights the state-of-the-art progress of foundation models in robot learning and future research should focus on multimodal interaction especially dynamics data, exclusive foundation models for robots, and AI alignment, etc.