 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Policies with Value-Conditional Optimization for Offline Reinforcement Learning
Nov 12, 2025
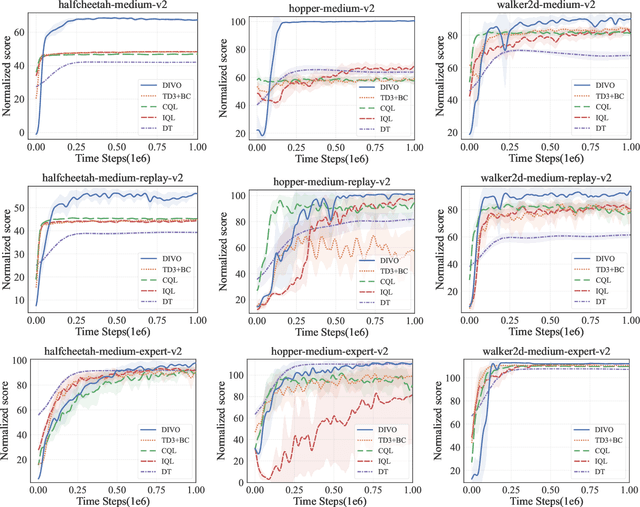

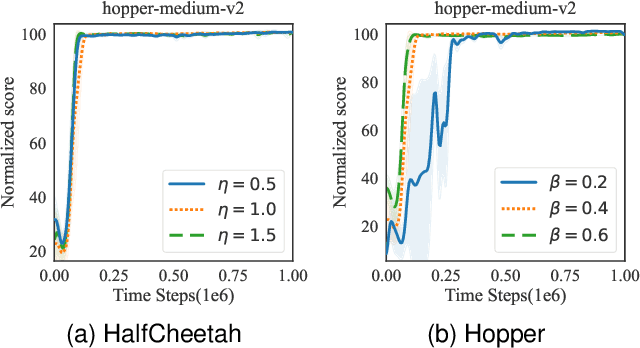
In offline reinforcement learning, value overestimation caused by out-of-distribution (OOD) actions significantly limits policy performance. Recently, diffusion models have been leveraged for their strong distribution-matching capabilities, enforcing conservatism through behavior policy constraints. However, existing methods often apply indiscriminate regularization to redundant actions in low-quality datasets, resulting in excessive conservatism and an imbalance between the expressiveness and efficiency of diffusion modeling. To address these issues, we propose DIffusion policies with Value-conditional Optimization (DIVO), a novel approach that leverages diffusion models to generate high-quality, broadly covered in-distribution state-action samples while facilitating efficient policy improvement. Specifically, DIVO introduces a binary-weighted mechanism that utilizes the advantage values of actions in the offline dataset to guide diffusion model training. This enables a more precise alignment with the dataset's distribution while selectively expanding the boundaries of high-advantage actions. During policy improvement, DIVO dynamically filters high-return-potential actions from the diffusion model, effectively guiding the learned policy toward better performance. This approach achieves a critical balance between conservatism and explorability in offline RL. We evaluate DIVO on the D4RL benchmark and compare it against state-of-the-art baselines. Empirical results demonstrate that DIVO achieves superior performance, delivering significant improvements in average returns across locomotion tasks and outperforming existing methods in the challenging AntMaze domain, where sparse rewards pose a major difficulty.
Versatile Distributed Maneuvering with Generalized Formations using Guiding Vector Fields
May 09, 2025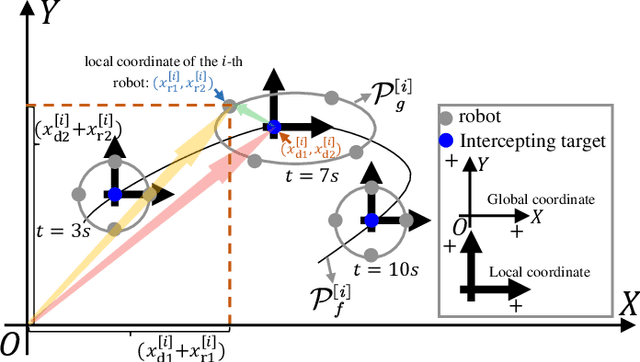
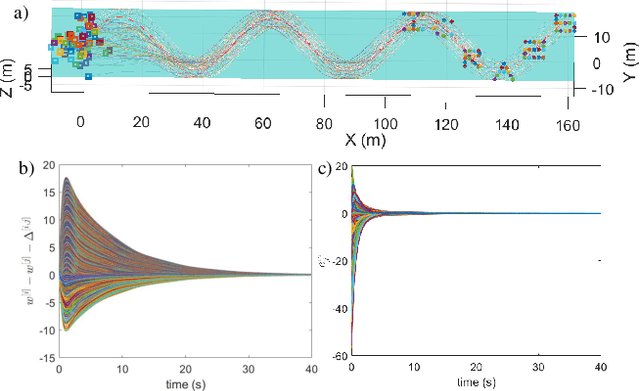
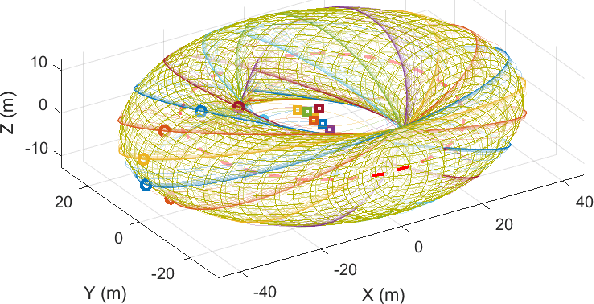
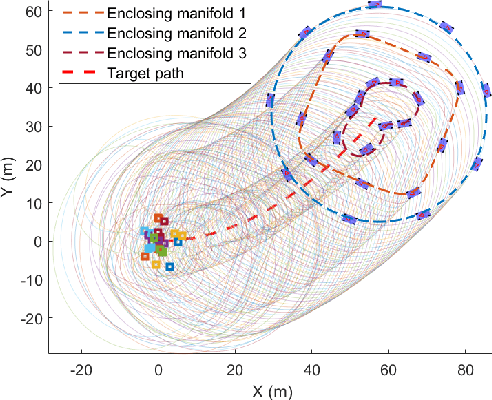
This paper presents a unified approach to realize versatile distributed maneuvering with generalized formations. Specifically, we decompose the robots' maneuvers into two independent components, i.e., interception and enclosing, which are parameterized by two independent virtual coordinates. Treating these two virtual coordinates as dimensions of an abstract manifold, we derive the corresponding singularity-free guiding vector field (GVF), which, along with a distributed coordination mechanism based on the consensus theory, guides robots to achieve various motions (i.e., versatile maneuvering), including (a) formation tracking, (b) target enclosing, and (c) circumnavigation. Additional motion parameters can generate more complex cooperative robot motions. Based on GVFs, we design a controller for a nonholonomic robot model. Besides the theoretical results, extensive simulations and experiments are performed to validate the effectiveness of the approach.
Flexible Exoskeleton Control Based on Binding Alignment Strategy and Full-arm Coordination Mechanism
Mar 03, 2025In rehabilitation, powered, and teleoperation exoskeletons, connecting the human body to the exoskeleton through binding attachments is a common configuration. However, the uncertainty of the tightness and the donning deviation of the binding attachments will affect the flexibility and comfort of the exoskeletons, especially during high-speed movement. To address this challenge, this paper presents a flexible exoskeleton control approach with binding alignment and full-arm coordination. Firstly, the sources of the force interaction caused by donning offsets are analyzed, based on which the interactive force data is classified into the major, assistant, coordination, and redundant component categories. Then, a binding alignment strategy (BAS) is proposed to reduce the donning disturbances by combining different force data. Furthermore, we propose a full-arm coordination mechanism (FCM) that focuses on two modes of arm movement intent, joint-oriented and target-oriented, to improve the flexible performance of the whole exoskeleton control during high-speed motion. In this method, we propose an algorithm to distinguish the two intentions to resolve the conflict issue of the force component. Finally, a series of experiments covering various aspects of exoskeleton performance (flexibility, adaptability, accuracy, speed, and fatigue) were conducted to demonstrate the benefits of our control framework in our full-arm exoskeleton.
Toward Scalable Multirobot Control: Fast Policy Learning in Distributed MPC
Dec 27, 2024



Distributed model predictive control (DMPC) is promising in achieving optimal cooperative control in multirobot systems (MRS). However, real-time DMPC implementation relies on numerical optimization tools to periodically calculate local control sequences online. This process is computationally demanding and lacks scalability for large-scale, nonlinear MRS. This article proposes a novel distributed learning-based predictive control (DLPC) framework for scalable multirobot control. Unlike conventional DMPC methods that calculate open-loop control sequences, our approach centers around a computationally fast and efficient distributed policy learning algorithm that generates explicit closed-loop DMPC policies for MRS without using numerical solvers. The policy learning is executed incrementally and forward in time in each prediction interval through an online distributed actor-critic implementation. The control policies are successively updated in a receding-horizon manner, enabling fast and efficient policy learning with the closed-loop stability guarantee. The learned control policies could be deployed online to MRS with varying robot scales, enhancing scalability and transferability for large-scale MRS. Furthermore, we extend our methodology to address the multirobot safe learning challenge through a force field-inspired policy learning approach. We validate our approach's effectiveness, scalability, and efficiency through extensive experiments on cooperative tasks of large-scale wheeled robots and multirotor drones. Our results demonstrate the rapid learning and deployment of DMPC policies for MRS with scales up to 10,000 units.
Learning-based Near-optimal Motion Planning for Intelligent Vehicles with Uncertain Dynamics
Aug 09, 2023Motion planning has been an important research topic in achieving safe and flexible maneuvers for intelligent vehicles. However, it remains challenging to realize efficient and optimal planning in the presence of uncertain model dynamics. In this paper, a sparse kernel-based reinforcement learning (RL) algorithm with Gaussian Process (GP) Regression (called GP-SKRL) is proposed to achieve online adaption and near-optimal motion planning performance. In this algorithm, we design an efficient sparse GP regression method to learn the uncertain dynamics. Based on the updated model, a sparse kernel-based policy iteration algorithm with an exponential barrier function is designed to learn the near-optimal planning policies with the capability to avoid dynamic obstacles. Thereby, batch-mode GP-SKRL with online adaption capability can estimate the changing system dynamics. The converged RL policies are then deployed on vehicles efficiently under a safety-aware module. As a result, the produced driving actions are safe and less conservative, and the planning performance has been noticeably improved. Extensive simulation results show that GP-SKRL outperforms several advanced motion planning methods in terms of average cumulative cost, trajectory length, and task completion time. In particular, experiments on a Hongqi E-HS3 vehicle demonstrate that superior GP-SKRL provides a practical planning solution.
Model-Based Safe Reinforcement Learning with Time-Varying State and Control Constraints: An Application to Intelligent Vehicles
Dec 18, 2021
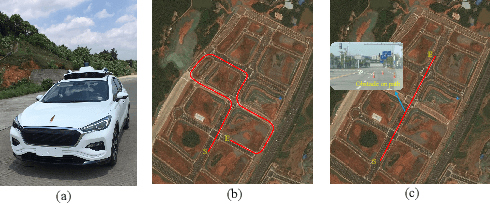
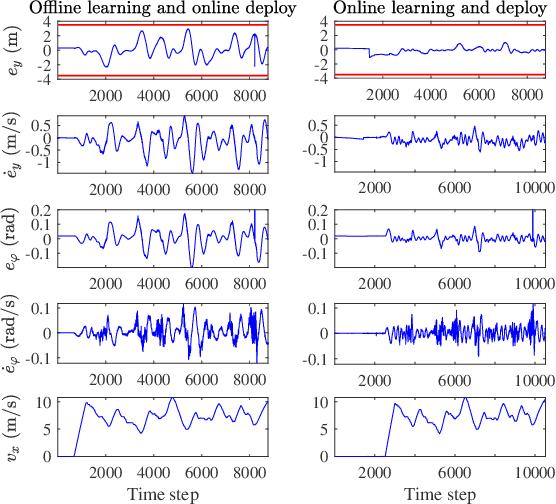
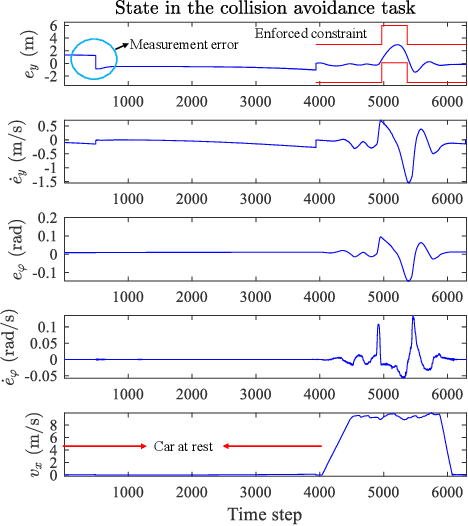
Recently, barrier function-based safe reinforcement learning (RL) with the actor-critic structure for continuous control tasks has received increasing attention. It is still challenging to learn a near-optimal control policy with safety and convergence guarantees. Also, few works have addressed the safe RL algorithm design under time-varying safety constraints. This paper proposes a model-based safe RL algorithm for optimal control of nonlinear systems with time-varying state and control constraints. In the proposed approach, we construct a novel barrier-based control policy structure that can guarantee control safety. A multi-step policy evaluation mechanism is proposed to predict the policy's safety risk under time-varying safety constraints and guide the policy to update safely. Theoretical results on stability and robustness are proven. Also, the convergence of the actor-critic learning algorithm is analyzed. The performance of the proposed algorithm outperforms several state-of-the-art RL algorithms in the simulated Safety Gym environment. Furthermore, the approach is applied to the integrated path following and collision avoidance problem for two real-world intelligent vehicles. A differential-drive vehicle and an Ackermann-drive one are used to verify the offline deployment performance and the online learning performance, respectively. Our approach shows an impressive sim-to-real transfer capability and a satisfactory online control performance in the experiment.
Robust Learning-based Predictive Control for Constrained Nonlinear Systems
Nov 22, 2019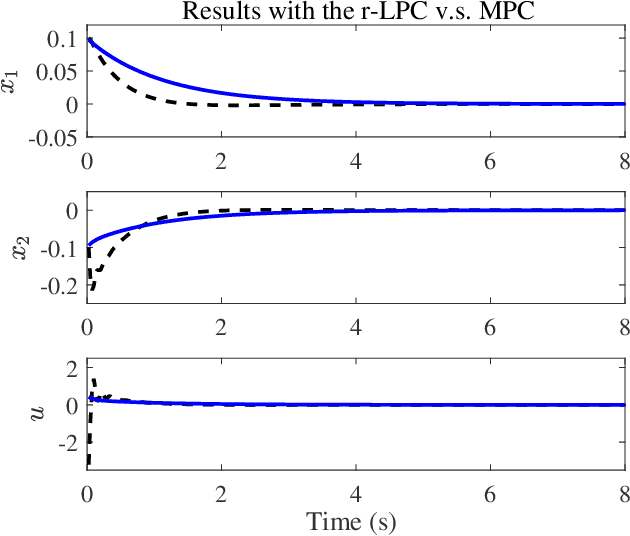

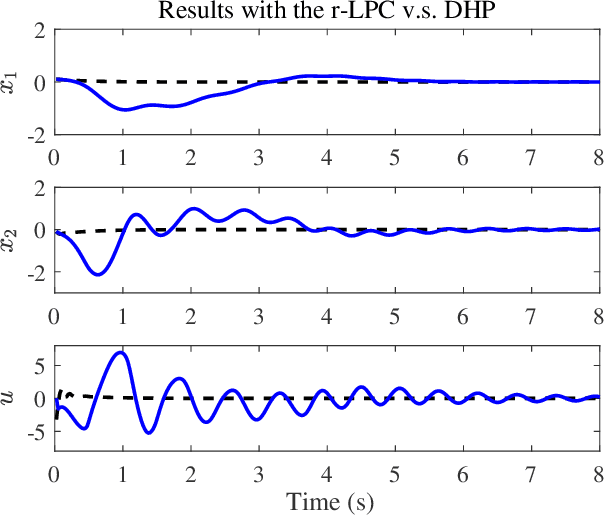
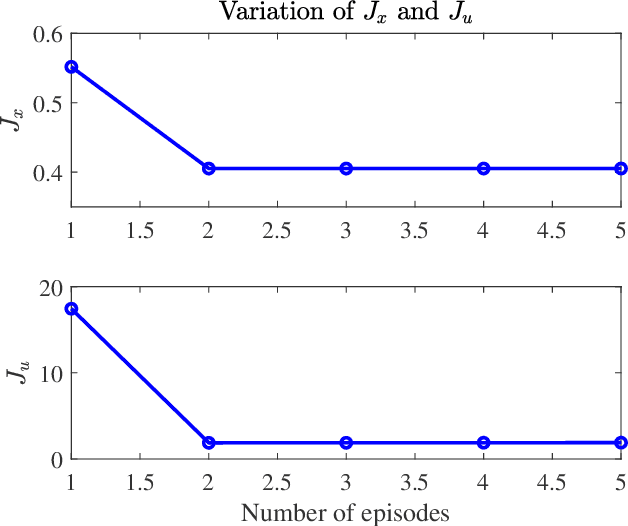
The integration of machine learning methods and Model Predictive Control (MPC) has received increasing attention in recent years. In general, learning-based predictive control (LPC) is promising to build data-driven models and solve the online optimization problem with lower computational costs. However, the robustness of LPC is difficult to be guaranteed since there will be uncertainties due to function approximation used in machine learning algorithms. In this paper, a novel robust learning-based predictive control (r-LPC) scheme is proposed for constrained nonlinear systems with unknown dynamics. In r-LPC, the Koopman operator is used to form a global linear representation of the unknown dynamics, and an incremental actor-critic algorithm is presented for receding horizon optimization. To realize the satisfaction of system constraints, soft logarithmic barrier functions are designed within the learning predictive framework. The recursive feasibility and stability of the closed-loop system are discussed under the convergence arguments of the approximation algorithms adopted. Also, the robustness property of r-LPC is analyzed theoretically by taking into consideration the existence of perturbations on the controller due to possible approximation errors. Simulation results with the proposed learning control approach for the data-driven regulation of a Van der Pol oscillator system have been reported, including the comparisons with a classic MPC and an infinite-horizon Dual Heuristic Programming (DHP) algorithm. The results show that the r-LPC significantly outperforms the DHP algorithm in terms of control performance and can be comparative to the MPC in terms of regulating control as well as energy consumption. Moreover, its average computational cost is much smaller than that with the MPC in the adopted environment.