 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Learners Meet Web Image-Text Pairs
Paper and Code
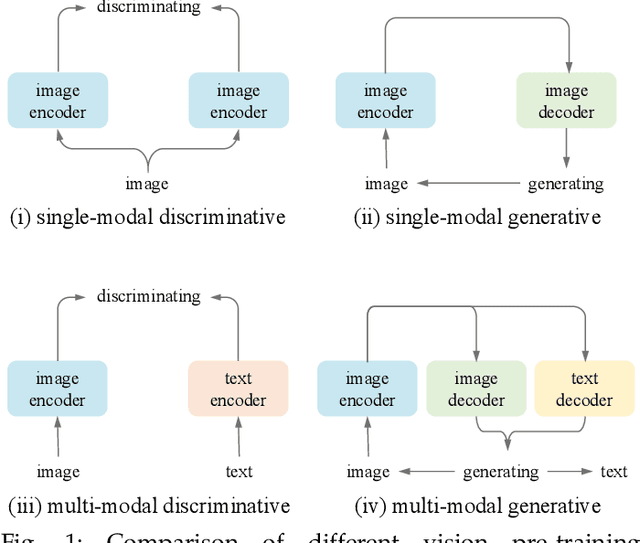
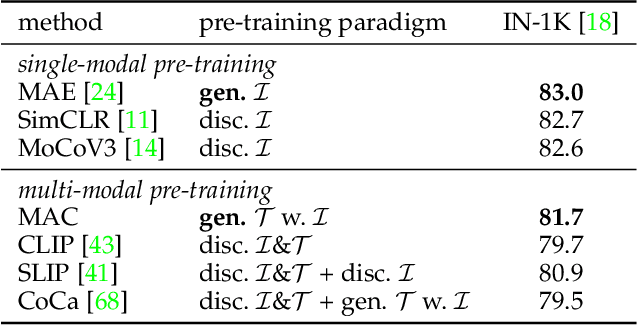

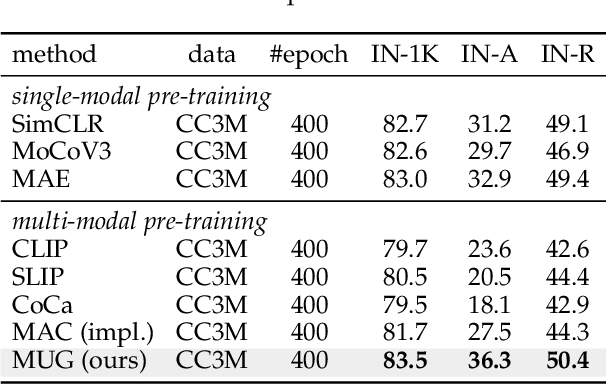
Most recent self-supervised learning~(SSL) methods are pre-trained on the well-curated ImageNet-1K dataset. In this work, we consider SSL pre-training on noisy web image-text paired data due to the excellent scalability of web data. First, we conduct a benchmark study of representative SSL pre-training methods on large-scale web data in a fair condition. Methods include single-modal ones such as MAE and multi-modal ones such as CLIP. We observe that multi-modal methods cannot outperform single-modal ones on vision transfer learning tasks. We derive an information-theoretical view to explain the benchmarking results, which provides insights into designing novel vision learners. Inspired by the above explorations, we present a visual representation pre-training method, MUlti-modal Generator~(MUG), for scalable web image-text data. MUG achieves state-of-the-art transferring performances on a variety of tasks and shows promising scaling behavior. Models and codes will be made public. Demo available at https://huggingface.co/spaces/tennant/MUG_caption