 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Subjective Truth: Collecting 2 Million Votes for Comprehensive Gen-AI Model Evaluation
Sep 18, 2024


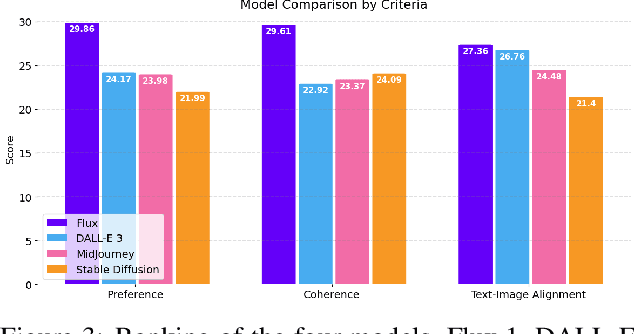
Efficiently evaluating the performance of text-to-image models is difficult as it inherently requires subjective judgment and human preference, making it hard to compare different models and quantify the state of the art. Leveraging Rapidata's technology, we present an efficient annotation framework that sources human feedback from a diverse, global pool of annotators. Our study collected over 2 million annotations across 4,512 images, evaluating four prominent models (DALL-E 3, Flux.1, MidJourney, and Stable Diffusion) on style preference, coherence, and text-to-image alignment. We demonstrate that our approach makes it feasible to comprehensively rank image generation models based on a vast pool of annotators and show that the diverse annotator demographics reflect the world population, significantly decreasing the risk of biases.
Model-aware 3D Eye Gaze from Weak and Few-shot Supervisions
Nov 20, 2023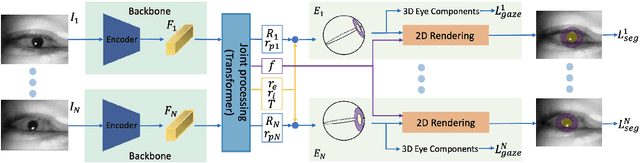
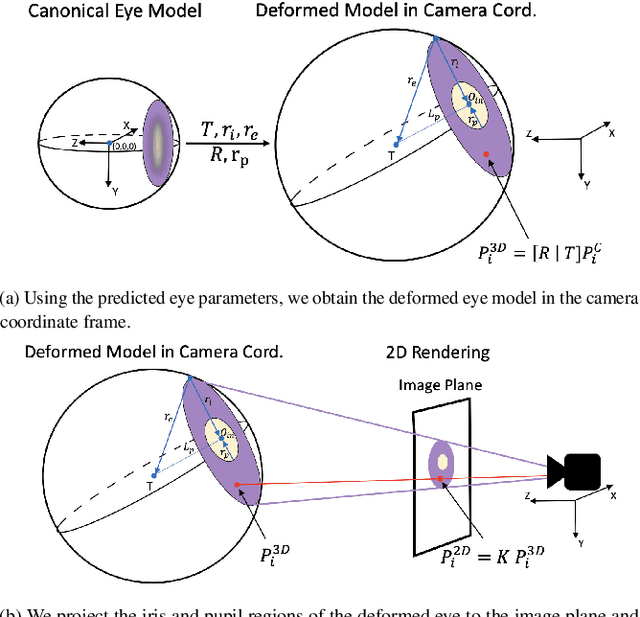
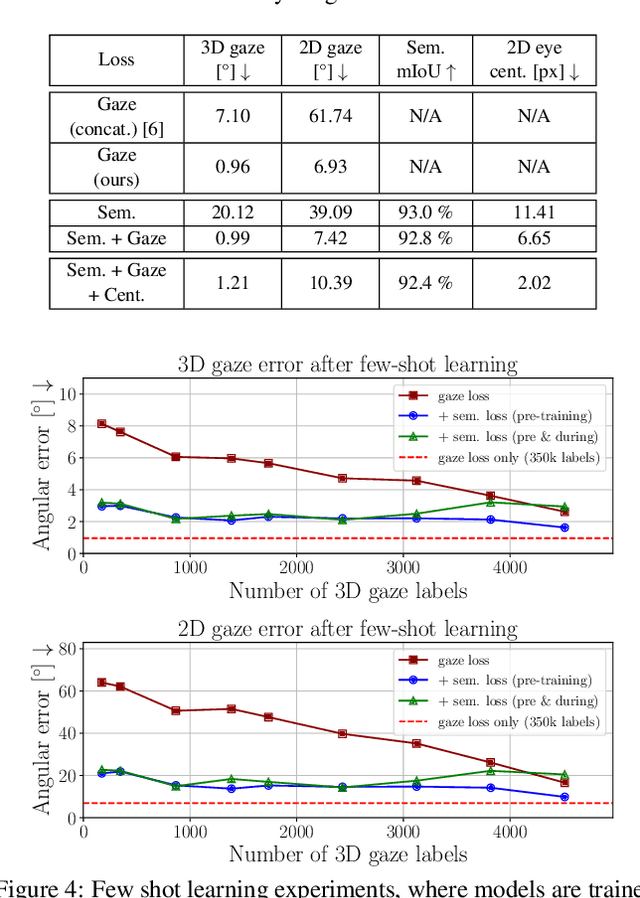
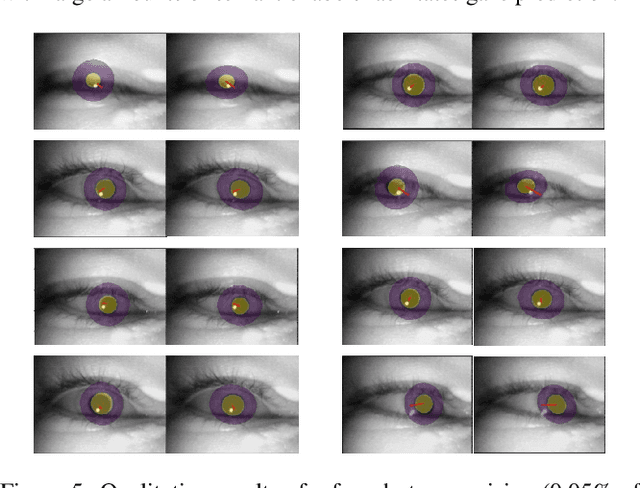
The task of predicting 3D eye gaze from eye images can be performed either by (a) end-to-end learning for image-to-gaze mapping or by (b) fitting a 3D eye model onto images. The former case requires 3D gaze labels, while the latter requires eye semantics or landmarks to facilitate the model fitting. Although obtaining eye semantics and landmarks is relatively easy, fitting an accurate 3D eye model on them remains to be very challenging due to its ill-posed nature in general. On the other hand, obtaining large-scale 3D gaze data is cumbersome due to the required hardware setups and computational demands. In this work, we propose to predict 3D eye gaze from weak supervision of eye semantic segmentation masks and direct supervision of a few 3D gaze vectors. The proposed method combines the best of both worlds by leveraging large amounts of weak annotations--which are easy to obtain, and only a few 3D gaze vectors--which alleviate the difficulty of fitting 3D eye models on the semantic segmentation of eye images. Thus, the eye gaze vectors, used in the model fitting, are directly supervised using the few-shot gaze labels. Additionally, we propose a transformer-based network architecture, that serves as a solid baseline for our improvements. Our experiments in diverse settings illustrate the significant benefits of the proposed method, achieving about 5 degrees lower angular gaze error over the baseline, when only 0.05% 3D annotations of the training images are used. The source code is available at https://github.com/dimitris-christodoulou57/Model-aware_3D_Eye_Gaze.