 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositeTasking: Understanding Images by Spatial Composition of Tasks
Paper and Code
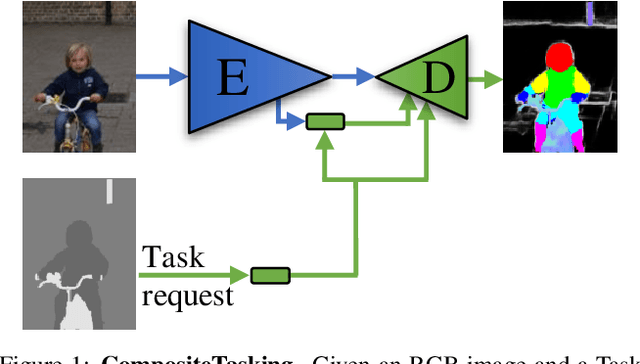
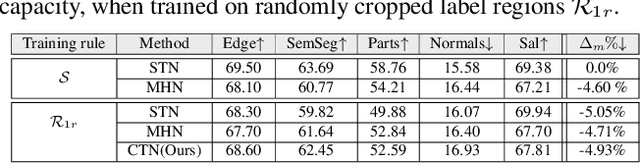
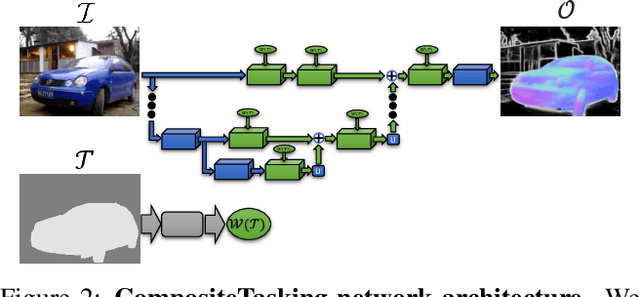
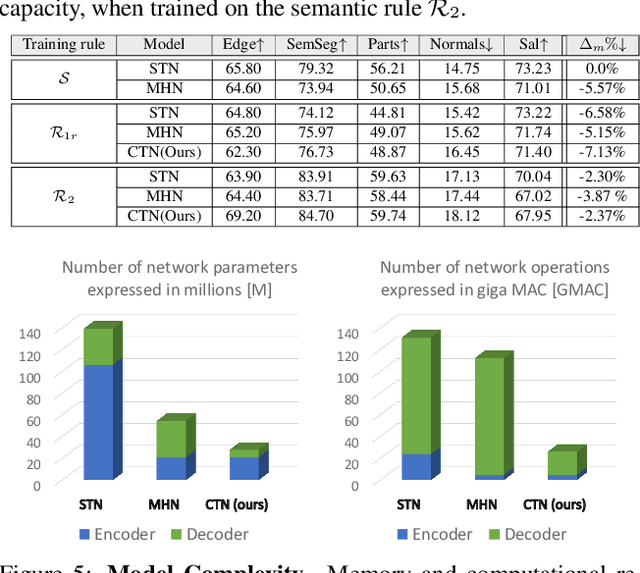
We define the concept of CompositeTasking as the fusion of multiple, spatially distributed tasks, for various aspects of image understanding. Learning to perform spatially distributed tasks is motivated by the frequent availability of only sparse labels across tasks, and the desire for a compact multi-tasking network. To facilitate CompositeTasking, we introduce a novel task conditioning model -- a single encoder-decoder network that performs multiple, spatially varying tasks at once. The proposed network takes a pair of an image and a set of pixel-wise dense tasks as inputs, and makes the task related predictions for each pixel, which includes the decision of applying which task where. As to the latter, we learn the composition of tasks that needs to be performed according to some CompositeTasking rules. It not only offers us a compact network for multi-tasking, but also allows for task-editing. The strength of the proposed method is demonstrated by only having to supply sparse supervision per task. The obtained results are on par with our baselines that use dense supervision and a multi-headed multi-tasking design. The source code will be made publicly available at www.github.com/nikola3794/composite-tasking .