 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Feature Mining for Video Semantic Segmentation
Paper and Code
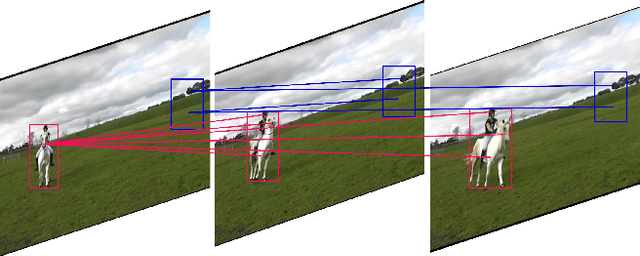
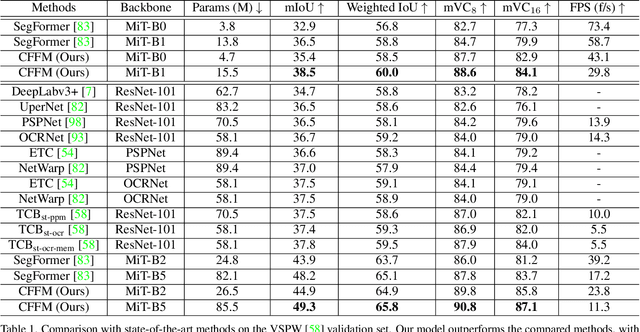
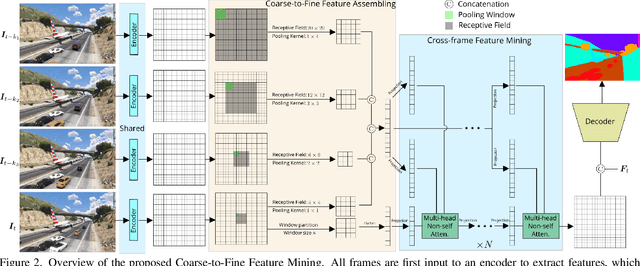
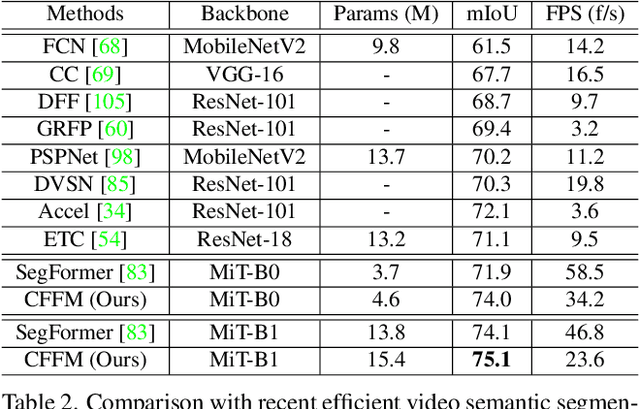
The contextual information plays a core role in semantic segmentation. As for video semantic segmentation, the contexts include static contexts and motional contexts, corresponding to static content and moving content in a video clip, respectively. The static contexts are well exploited in image semantic segmentation by learning multi-scale and global/long-range features. The motional contexts are studied in previous video semantic segmentation. However, there is no research about how to simultaneously learn static and motional contexts which are highly correlated and complementary to each other. To address this problem, we propose a Coarse-to-Fine Feature Mining (CFFM) technique to learn a unified presentation of static contexts and motional contexts. This technique consists of two parts: coarse-to-fine feature assembling and cross-frame feature mining. The former operation prepares data for further processing, enabling the subsequent joint learning of static and motional contexts. The latter operation mines useful information/contexts from the sequential frames to enhance the video contexts of the features of the target frame. The enhanced features can be directly applied for the final prediction. Experimental results on popular benchmarks demonstrate that the proposed CFFM performs favorably against state-of-the-art methods for video semantic segmentation. Our implementation is available at https://github.com/GuoleiSun/VSS-CFFM