 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Conditioned Background Generation for Editable Multi-Layer Documents
Dec 19, 2025



We present a framework for document-centric background generation with multi-page editing and thematic continuity. To ensure text regions remain readable, we employ a \emph{latent masking} formulation that softly attenuates updates in the diffusion space, inspired by smooth barrier functions in physics and numerical optimization. In addition, we introduce \emph{Automated Readability Optimization (ARO)}, which automatically places semi-transparent, rounded backing shapes behind text regions. ARO determines the minimal opacity needed to satisfy perceptual contrast standards (WCAG 2.2) relative to the underlying background, ensuring readability while maintaining aesthetic harmony without human intervention. Multi-page consistency is maintained through a summarization-and-instruction process, where each page is distilled into a compact representation that recursively guides subsequent generations. This design reflects how humans build continuity by retaining prior context, ensuring that visual motifs evolve coherently across an entire document. Our method further treats a document as a structured composition in which text, figures, and backgrounds are preserved or regenerated as separate layers, allowing targeted background editing without compromising readability. Finally, user-provided prompts allow stylistic adjustments in color and texture, balancing automated consistency with flexible customization. Our training-free framework produces visually coherent, text-preserving, and thematically aligned documents, bridging generative modeling with natural design workflows.
Crossing Borders: A Multimodal Challenge for Indian Poetry Translation and Image Generation
Nov 18, 2025Indian poetry, known for its linguistic complexity and deep cultural resonance, has a rich and varied heritage spanning thousands of years. However, its layered meanings, cultural allusions, and sophisticated grammatical constructions often pose challenges for comprehension, especially for non-native speakers or readers unfamiliar with its context and language. Despite its cultural significance, existing works on poetry have largely overlooked Indian language poems. In this paper, we propose the Translation and Image Generation (TAI) framework, leveraging Large Language Models (LLMs) and Latent Diffusion Models through appropriate prompt tuning. Our framework supports the United Nations Sustainable Development Goals of Quality Education (SDG 4) and Reduced Inequalities (SDG 10) by enhancing the accessibility of culturally rich Indian-language poetry to a global audience. It includes (1) a translation module that uses an Odds Ratio Preference Alignment Algorithm to accurately translate morphologically rich poetry into English, and (2) an image generation module that employs a semantic graph to capture tokens, dependencies, and semantic relationships between metaphors and their meanings, to create visually meaningful representations of Indian poems. Our comprehensive experimental evaluation, including both human and quantitative assessments, demonstrates the superiority of TAI Diffusion in poem image generation tasks, outperforming strong baselines. To further address the scarcity of resources for Indian-language poetry, we introduce the Morphologically Rich Indian Language Poems MorphoVerse Dataset, comprising 1,570 poems across 21 low-resource Indian languages. By addressing the gap in poetry translation and visual comprehension, this work aims to broaden accessibility and enrich the reader's experience.
POET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
Contextual Prompt Learning for Vision-Language Understanding
Jul 03, 2023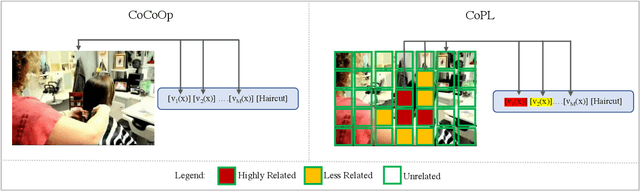
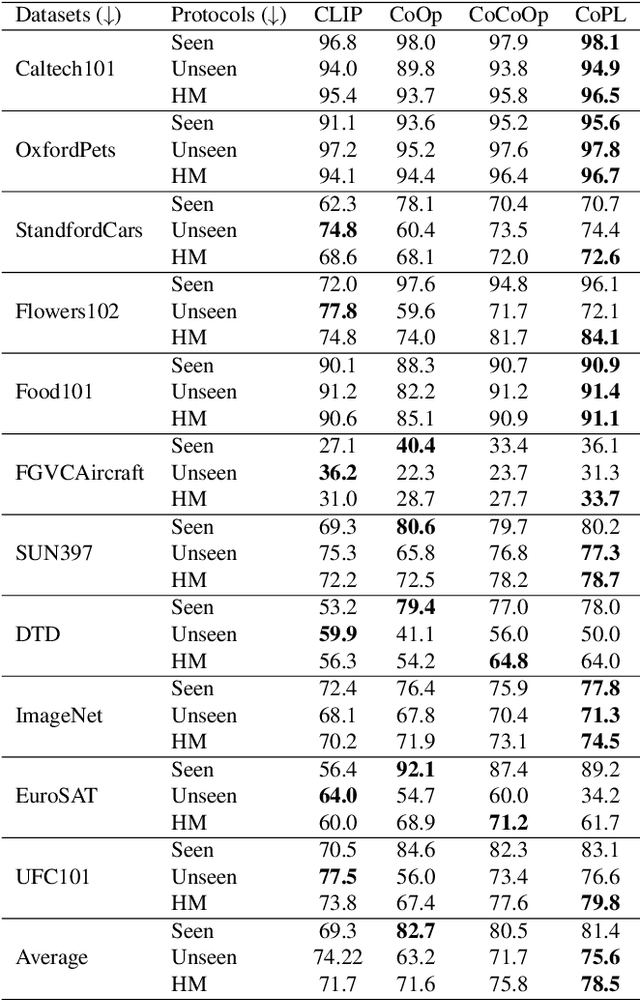
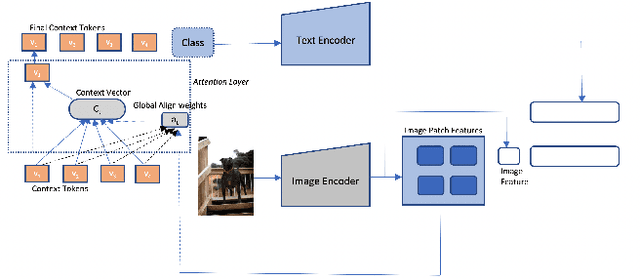

Recent advances in multimodal learning has resulted in powerful vision-language models, whose representations are generalizable across a variety of downstream tasks. Recently, their generalizability has been further extended by incorporating trainable prompts, borrowed from the natural language processing literature. While such prompt learning techniques have shown impressive results, we identify that these prompts are trained based on global image features which limits itself in two aspects: First, by using global features, these prompts could be focusing less on the discriminative foreground image, resulting in poor generalization to various out-of-distribution test cases. Second, existing work weights all prompts equally whereas our intuition is that these prompts are more specific to the type of the image. We address these issues with as part of our proposed Contextual Prompt Learning (CoPL) framework, capable of aligning the prompts to the localized features of the image. Our key innovations over earlier works include using local image features as part of the prompt learning process, and more crucially, learning to weight these prompts based on local features that are appropriate for the task at hand. This gives us dynamic prompts that are both aligned to local image features as well as aware of local contextual relationships. Our extensive set of experiments on a variety of standard and few-shot datasets show that our method produces substantially improved performance when compared to the current state of the art methods. We also demonstrate both few-shot and out-of-distribution performance to establish the utility of learning dynamic prompts that are aligned to local image features.
Zero Shot Domain Generalization
Aug 17, 2020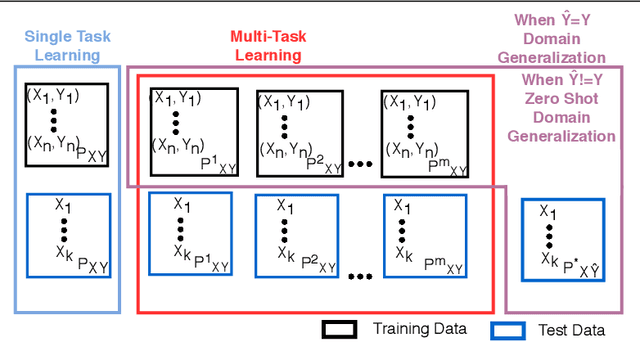
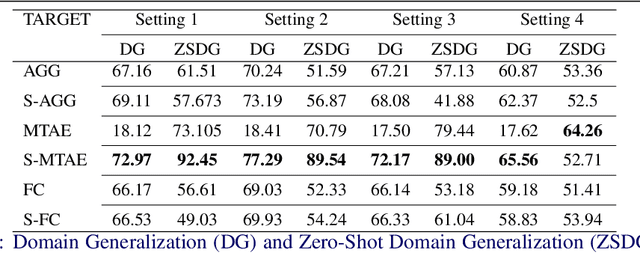
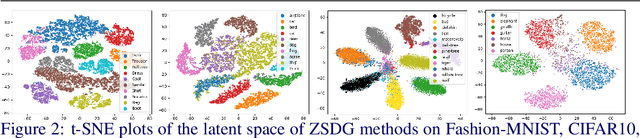
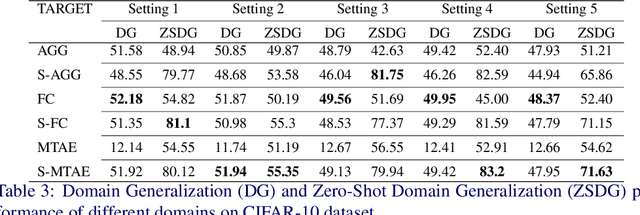
Standard supervised learning setting assumes that training data and test data come from the same distribution (domain). Domain generalization (DG) methods try to learn a model that when trained on data from multiple domains, would generalize to a new unseen domain. We extend DG to an even more challenging setting, where the label space of the unseen domain could also change. We introduce this problem as Zero-Shot Domain Generalization (to the best of our knowledge, the first such effort), where the model generalizes across new domains and also across new classes in those domains. We propose a simple strategy which effectively exploits semantic information of classes, to adapt existing DG methods to meet the demands of Zero-Shot Domain Generalization. We evaluate the proposed methods on CIFAR-10, CIFAR-100, F-MNIST and PACS datasets, establishing a strong baseline to foster interest in this new research direction.