 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Feature Analysis for Action Recognition in RGB+D Videos
Dec 26, 2016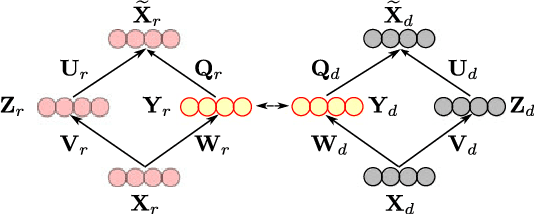
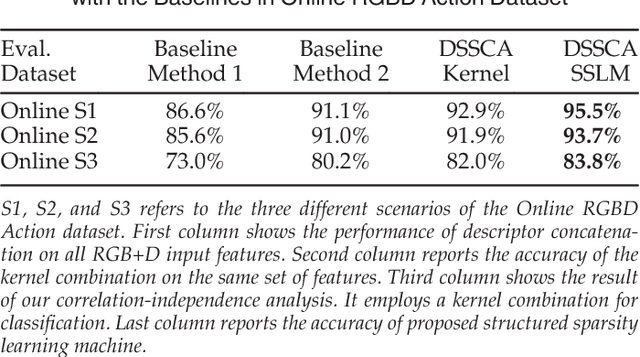
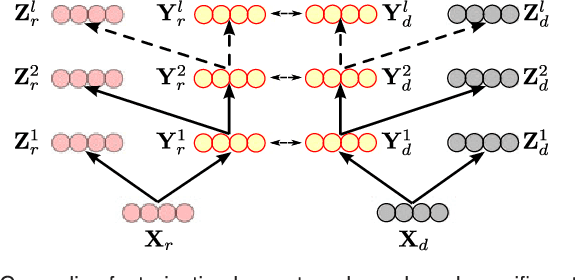
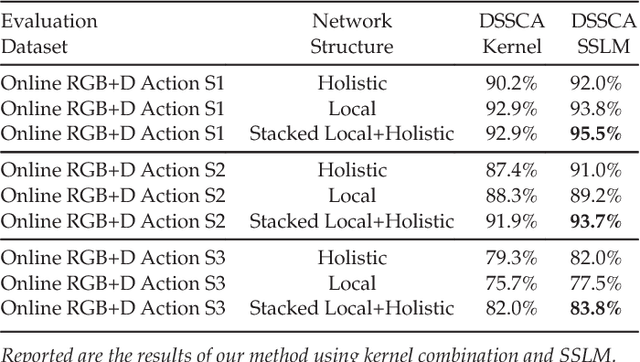
Single modality action recognition on RGB or depth sequences has been extensively explored recently. It is generally accepted that each of these two modalities has different strengths and limitations for the task of action recognition. Therefore, analysis of the RGB+D videos can help us to better study the complementary properties of these two types of modalities and achieve higher levels of performance. In this paper, we propose a new deep autoencoder based shared-specific feature factorization network to separate input multimodal signals into a hierarchy of components. Further, based on the structure of the features, a structured sparsity learning machine is proposed which utilizes mixed norms to apply regularization within components and group selection between them for better classification performance. Our experimental results show the effectiveness of our cross-modality feature analysis framework by achieving state-of-the-art accuracy for action classification on five challenging benchmark datasets.
NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis
Apr 11, 2016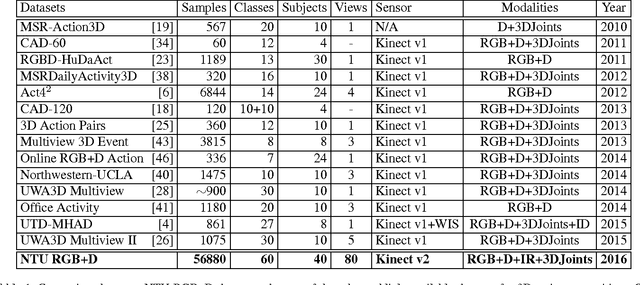
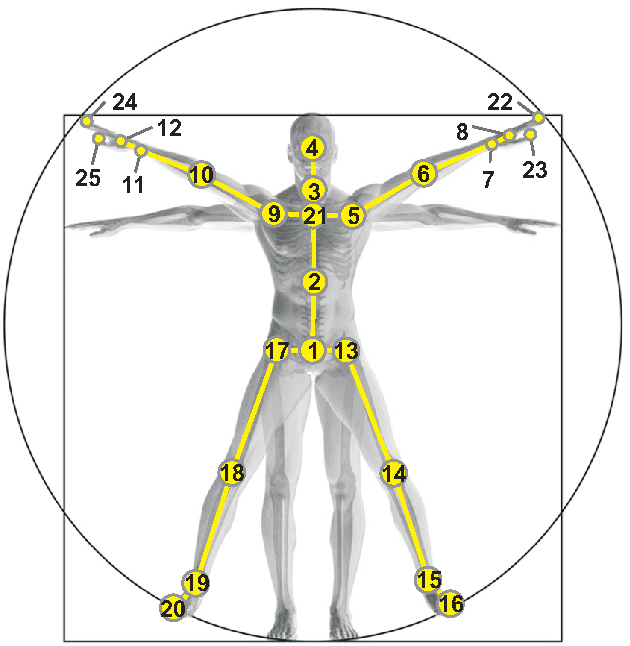
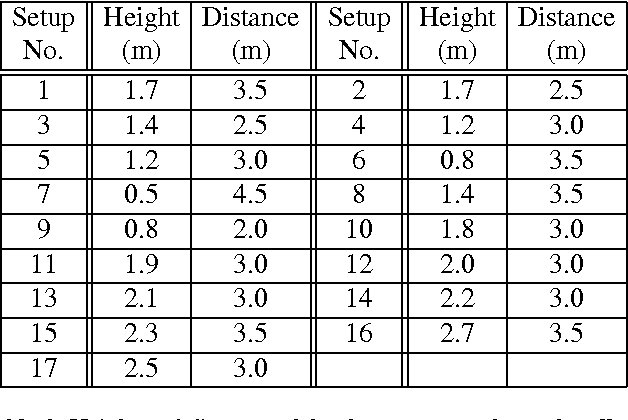
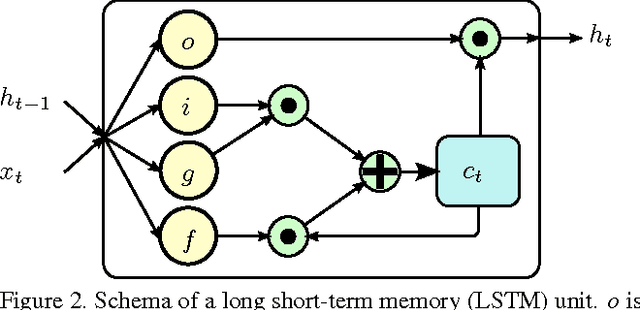
Recent approaches in depth-based human activity analysis achieved outstanding performance and proved the effectiveness of 3D representation for classification of action classes. Currently available depth-based and RGB+D-based action recognition benchmarks have a number of limitations, including the lack of training samples, distinct class labels, camera views and variety of subjects. In this paper we introduce a large-scale dataset for RGB+D human action recognition with more than 56 thousand video samples and 4 million frames, collected from 40 distinct subjects. Our dataset contains 60 different action classes including daily, mutual, and health-related actions. In addition, we propose a new recurrent neural network structure to model the long-term temporal correlation of the features for each body part, and utilize them for better action classification. Experimental results show the advantages of applying deep learning methods over state-of-the-art hand-crafted features on the suggested cross-subject and cross-view evaluation criteria for our dataset. The introduction of this large scale dataset will enable the community to apply, develop and adapt various data-hungry learning techniques for the task of depth-based and RGB+D-based human activity analysis.
Towards Predicting the Likeability of Fashion Images
Nov 23, 2015
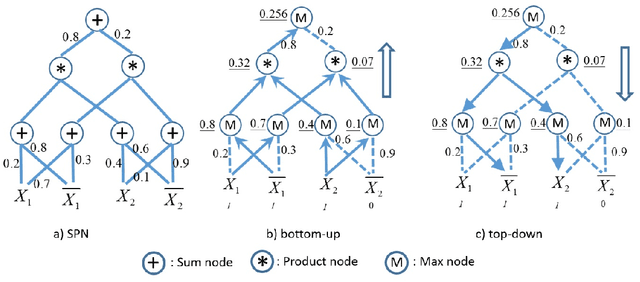

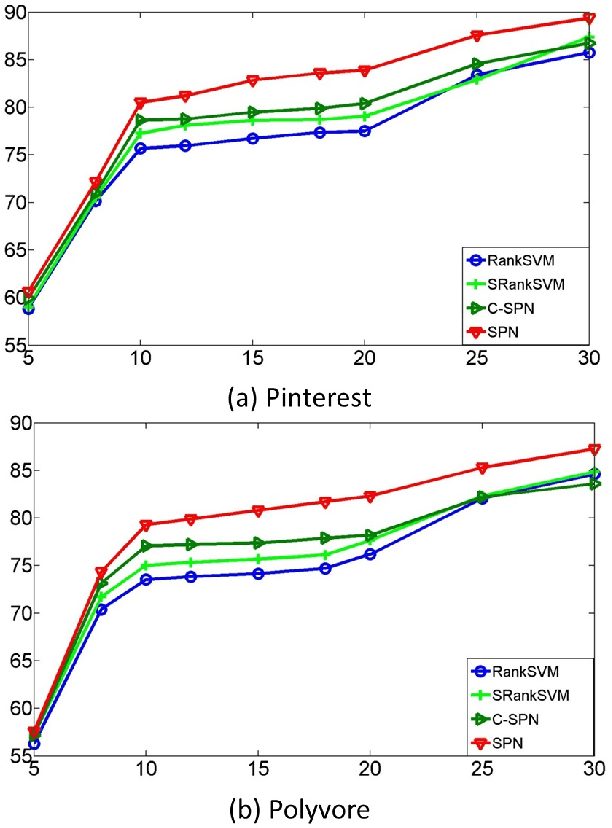
In this paper, we propose a method for ranking fashion images to find the ones which might be liked by more people. We collect two new datasets from image sharing websites (Pinterest and Polyvore). We represent fashion images based on attributes: semantic attributes and data-driven attributes. To learn semantic attributes from limited training data, we use an algorithm on multi-task convolutional neural networks to share visual knowledge among different semantic attribute categories. To discover data-driven attributes unsupervisedly, we propose an algorithm to simultaneously discover visual clusters and learn fashion-specific feature representations. Given attributes as representations, we propose to learn a ranking SPN (sum product networks) to rank pairs of fashion images. The proposed ranking SPN can capture the high-order correlations of the attributes. We show the effectiveness of our method on our two newly collected datasets.
Multimodal Multipart Learning for Action Recognition in Depth Videos
Jul 31, 2015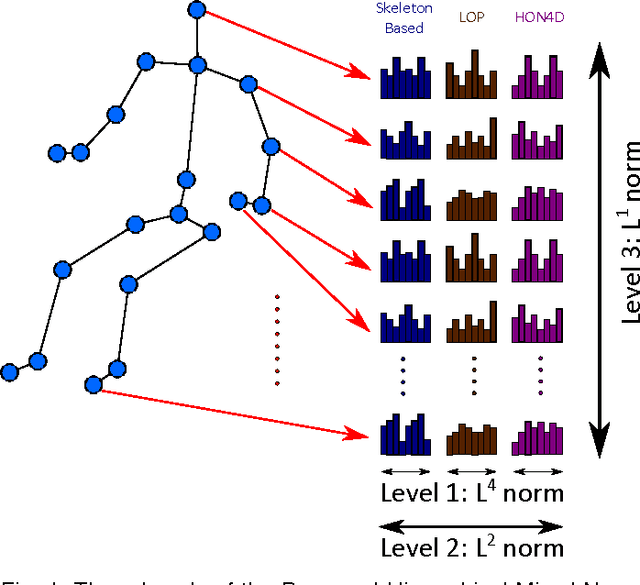


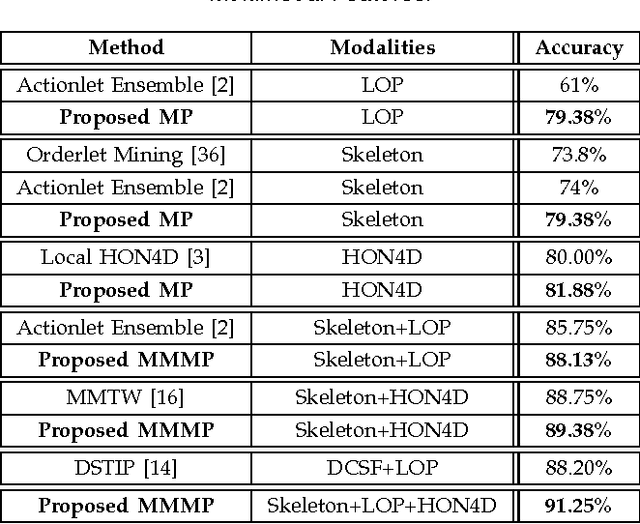
The articulated and complex nature of human actions makes the task of action recognition difficult. One approach to handle this complexity is dividing it to the kinetics of body parts and analyzing the actions based on these partial descriptors. We propose a joint sparse regression based learning method which utilizes the structured sparsity to model each action as a combination of multimodal features from a sparse set of body parts. To represent dynamics and appearance of parts, we employ a heterogeneous set of depth and skeleton based features. The proper structure of multimodal multipart features are formulated into the learning framework via the proposed hierarchical mixed norm, to regularize the structured features of each part and to apply sparsity between them, in favor of a group feature selection. Our experimental results expose the effectiveness of the proposed learning method in which it outperforms other methods in all three tested datasets while saturating one of them by achieving perfect accuracy.
Epitome for Automatic Image Colorization
Oct 08, 2012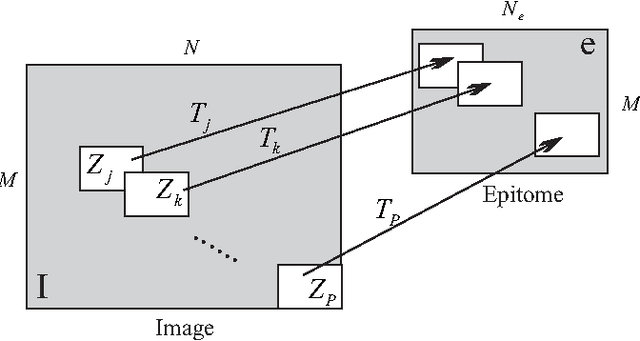
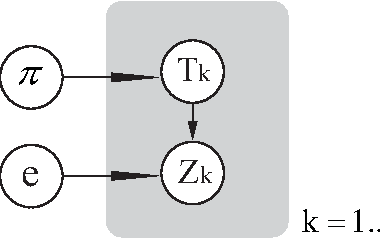


Image colorization adds color to grayscale images. It not only increases the visual appeal of grayscale images, but also enriches the information contained in scientific images that lack color information. Most existing methods of colorization require laborious user interaction for scribbles or image segmentation. To eliminate the need for human labor, we develop an automatic image colorization method using epitome. Built upon a generative graphical model, epitome is a condensed image appearance and shape model which also proves to be an effective summary of color information for the colorization task. We train the epitome from the reference images and perform inference in the epitome to colorize grayscale images, rendering better colorization results than previous method in our experiments.