 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding
May 12, 2019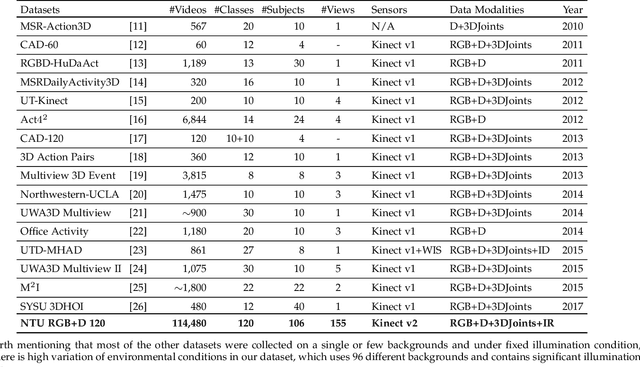
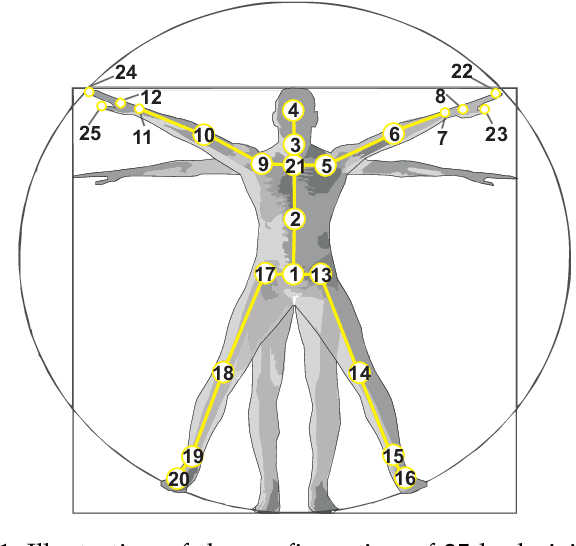
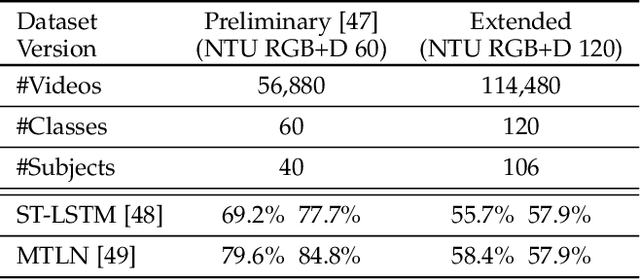
Research on depth-based human activity analysis achieved outstanding performance and demonstrated the effectiveness of 3D representation for action recognition. The existing depth-based and RGB+D-based action recognition benchmarks have a number of limitations, including the lack of large-scale training samples, realistic number of distinct class categories, diversity in camera views, varied environmental conditions, and variety of human subjects. In this work, we introduce a large-scale dataset for RGB+D human action recognition, which is collected from 106 distinct subjects and contains more than 114 thousand video samples and 8 million frames. This dataset contains 120 different action classes including daily, mutual, and health-related activities. We evaluate the performance of a series of existing 3D activity analysis methods on this dataset, and show the advantage of applying deep learning methods for 3D-based human action recognition. Furthermore, we investigate a novel one-shot 3D activity recognition problem on our dataset, and a simple yet effective Action-Part Semantic Relevance-aware (APSR) framework is proposed for this task, which yields promising results for recognition of the novel action classes. We believe the introduction of this large-scale dataset will enable the community to apply, adapt, and develop various data-hungry learning techniques for depth-based and RGB+D-based human activity understanding. [The dataset is available at: http://rose1.ntu.edu.sg/Datasets/actionRecognition.asp]
Skeleton-Based Online Action Prediction Using Scale Selection Network
Apr 03, 2019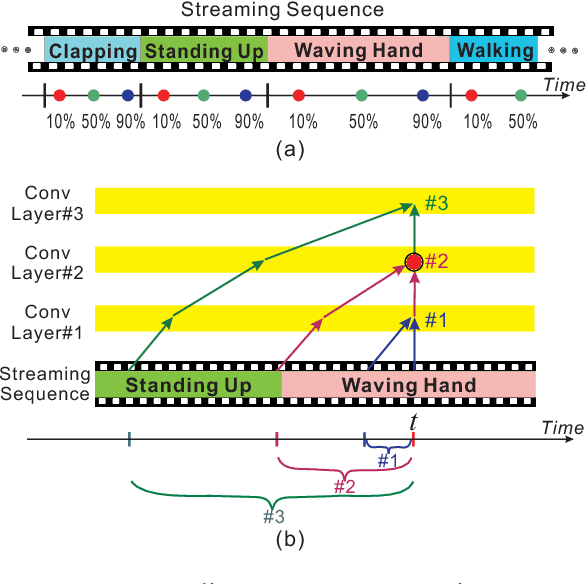

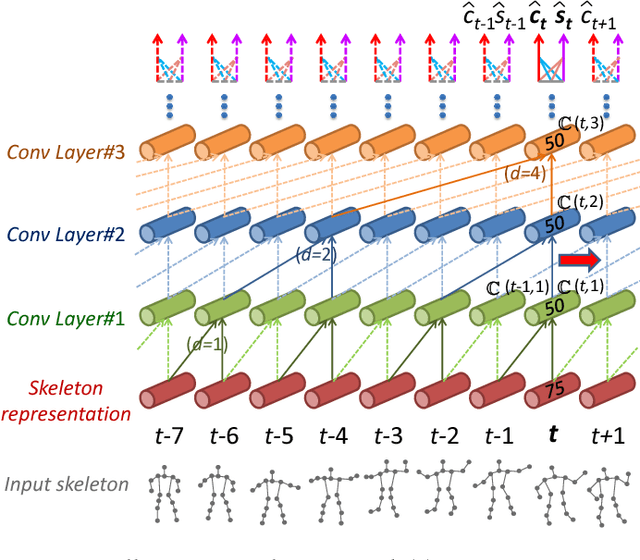
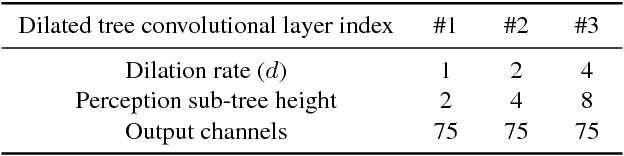
Action prediction is to recognize the class label of an ongoing activity when only a part of it is observed. In this paper, we focus on online action prediction in streaming 3D skeleton sequences. A dilated convolutional network is introduced to model the motion dynamics in temporal dimension via a sliding window over the temporal axis. Since there are significant temporal scale variations in the observed part of the ongoing action at different time steps, a novel window scale selection method is proposed to make our network focus on the performed part of the ongoing action and try to suppress the possible incoming interference from the previous actions at each step. An activation sharing scheme is also proposed to handle the overlapping computations among the adjacent time steps, which enables our framework to run more efficiently. Moreover, to enhance the performance of our framework for action prediction with the skeletal input data, a hierarchy of dilated tree convolutions are also designed to learn the multi-level structured semantic representations over the skeleton joints at each frame. Our proposed approach is evaluated on four challenging datasets. The extensive experiments demonstrate the effectiveness of our method for skeleton-based online action prediction.
Feature Boosting Network For 3D Pose Estimation
Jan 15, 2019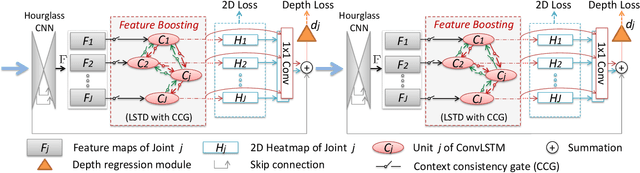
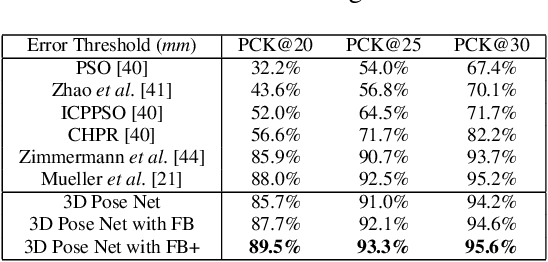
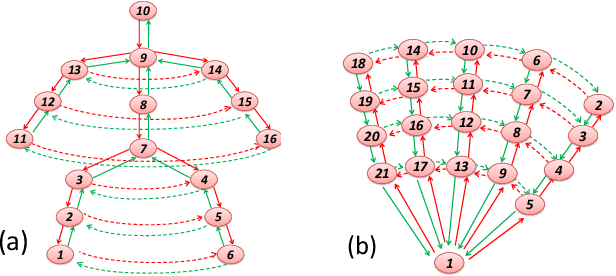

In this paper, a feature boosting network is proposed for estimating 3D hand pose and 3D body pose from a single RGB image. In this method, the features learned by the convolutional layers are boosted with a new long short-term dependence-aware (LSTD) module, which enables the intermediate convolutional feature maps to perceive the graphical long short-term dependency among different hand (or body) parts using the designed Graphical ConvLSTM. Learning a set of features that are reliable and discriminatively representative of the pose of a hand (or body) part is difficult due to the ambiguities, texture and illumination variation, and self-occlusion in the real application of 3D pose estimation. To improve the reliability of the features for representing each body part and enhance the LSTD module, we further introduce a context consistency gate (CCG) in this paper, with which the convolutional feature maps are modulated according to their consistency with the context representations. We evaluate the proposed method on challenging benchmark datasets for 3D hand pose estimation and 3D full body pose estimation. Experimental results show the effectiveness of our method that achieves state-of-the-art performance on both of the tasks.
Recent Advances in Convolutional Neural Networks
Oct 19, 2017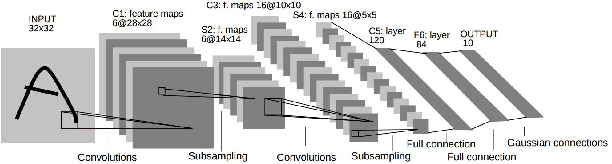
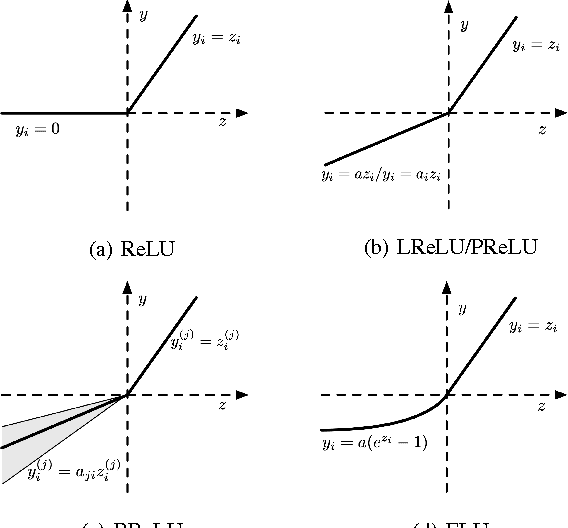
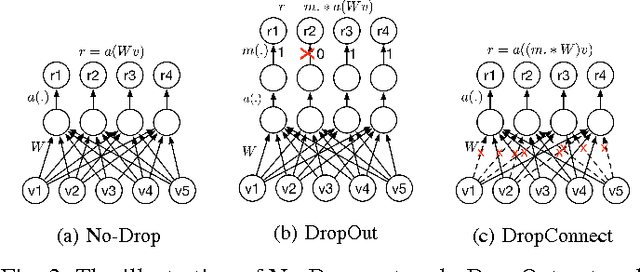
In the last few years, deep learning has led to very good performance on a variety of problems, such as visual recognition, speech recognition and natural language processing. Among different types of deep neural networks, convolutional neural networks have been most extensively studied. Leveraging on the rapid growth in the amount of the annotated data and the great improvements in the strengths of graphics processor units, the research on convolutional neural networks has been emerged swiftly and achieved state-of-the-art results on various tasks. In this paper, we provide a broad survey of the recent advances in convolutional neural networks. We detailize the improvements of CNN on different aspects, including layer design, activation function, loss function, regularization, optimization and fast computation. Besides, we also introduce various applications of convolutional neural networks in computer vision, speech and natural language processing.
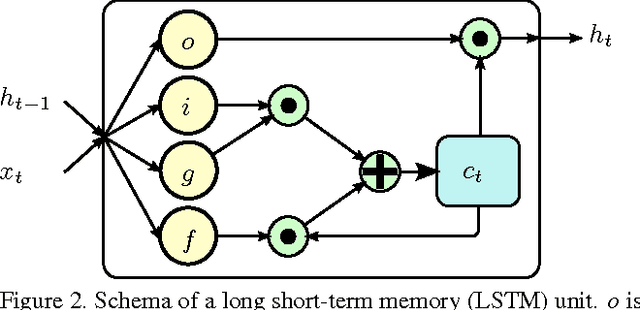
Skeleton-Based Action Recognition Using Spatio-Temporal LSTM Network with Trust Gates
Jun 26, 2017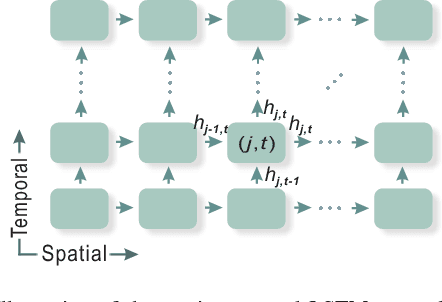
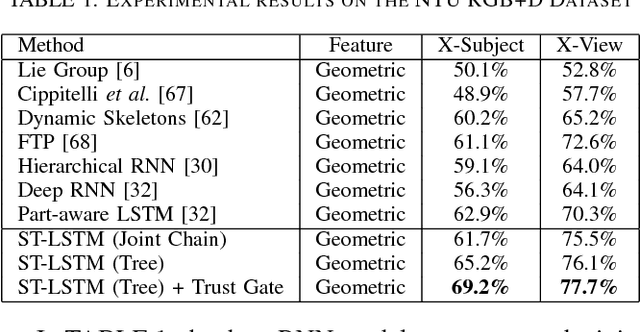
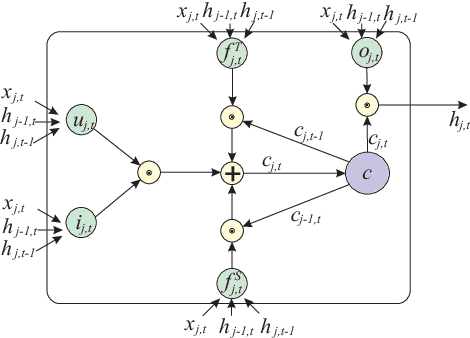
Skeleton-based human action recognition has attracted a lot of research attention during the past few years. Recent works attempted to utilize recurrent neural networks to model the temporal dependencies between the 3D positional configurations of human body joints for better analysis of human activities in the skeletal data. The proposed work extends this idea to spatial domain as well as temporal domain to better analyze the hidden sources of action-related information within the human skeleton sequences in both of these domains simultaneously. Based on the pictorial structure of Kinect's skeletal data, an effective tree-structure based traversal framework is also proposed. In order to deal with the noise in the skeletal data, a new gating mechanism within LSTM module is introduced, with which the network can learn the reliability of the sequential data and accordingly adjust the effect of the input data on the updating procedure of the long-term context representation stored in the unit's memory cell. Moreover, we introduce a novel multi-modal feature fusion strategy within the LSTM unit in this paper. The comprehensive experimental results on seven challenging benchmark datasets for human action recognition demonstrate the effectiveness of the proposed method.
Deep Multimodal Feature Analysis for Action Recognition in RGB+D Videos
Dec 26, 2016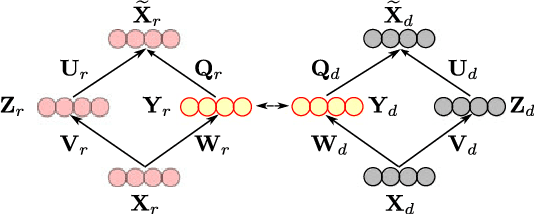
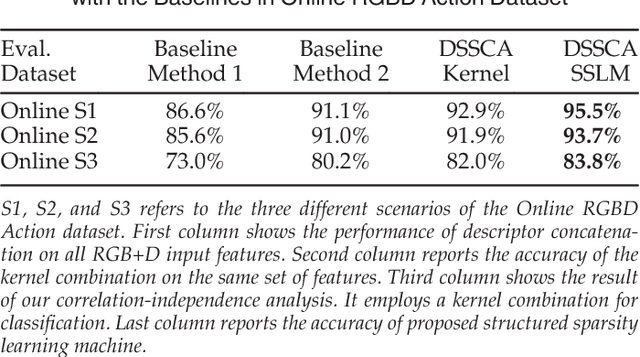
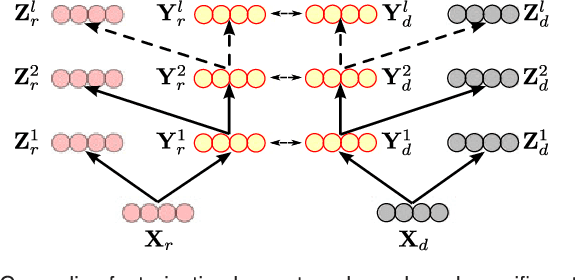
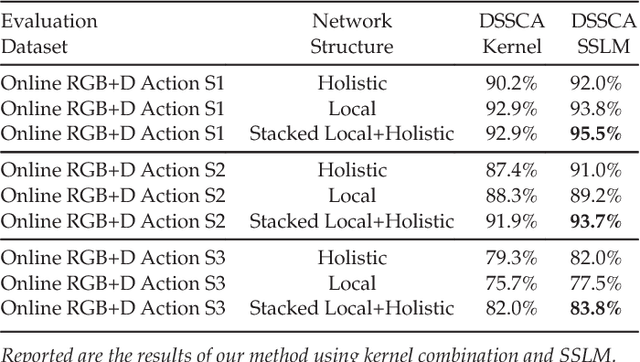
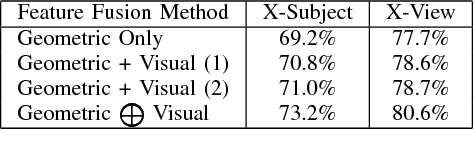
Single modality action recognition on RGB or depth sequences has been extensively explored recently. It is generally accepted that each of these two modalities has different strengths and limitations for the task of action recognition. Therefore, analysis of the RGB+D videos can help us to better study the complementary properties of these two types of modalities and achieve higher levels of performance. In this paper, we propose a new deep autoencoder based shared-specific feature factorization network to separate input multimodal signals into a hierarchy of components. Further, based on the structure of the features, a structured sparsity learning machine is proposed which utilizes mixed norms to apply regularization within components and group selection between them for better classification performance. Our experimental results show the effectiveness of our cross-modality feature analysis framework by achieving state-of-the-art accuracy for action classification on five challenging benchmark datasets.
Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition
Jul 24, 2016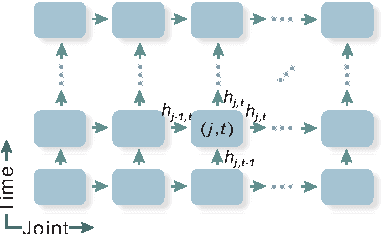
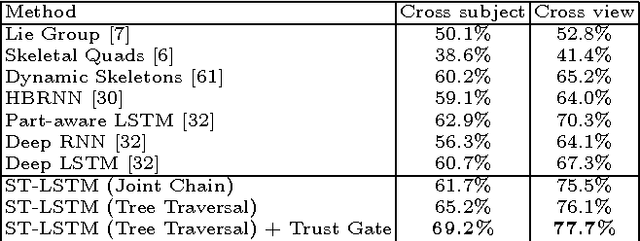
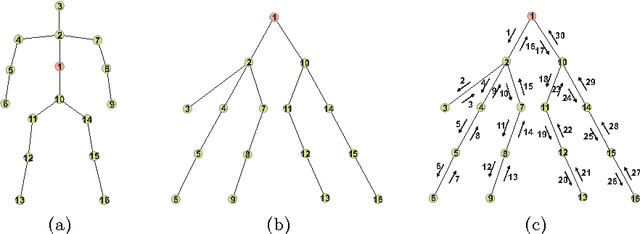
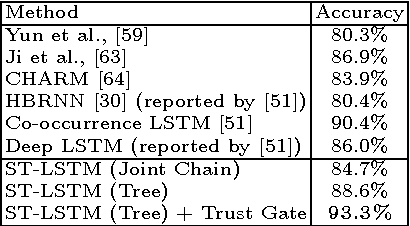
3D action recognition - analysis of human actions based on 3D skeleton data - becomes popular recently due to its succinctness, robustness, and view-invariant representation. Recent attempts on this problem suggested to develop RNN-based learning methods to model the contextual dependency in the temporal domain. In this paper, we extend this idea to spatio-temporal domains to analyze the hidden sources of action-related information within the input data over both domains concurrently. Inspired by the graphical structure of the human skeleton, we further propose a more powerful tree-structure based traversal method. To handle the noise and occlusion in 3D skeleton data, we introduce new gating mechanism within LSTM to learn the reliability of the sequential input data and accordingly adjust its effect on updating the long-term context information stored in the memory cell. Our method achieves state-of-the-art performance on 4 challenging benchmark datasets for 3D human action analysis.
NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis
Apr 11, 2016
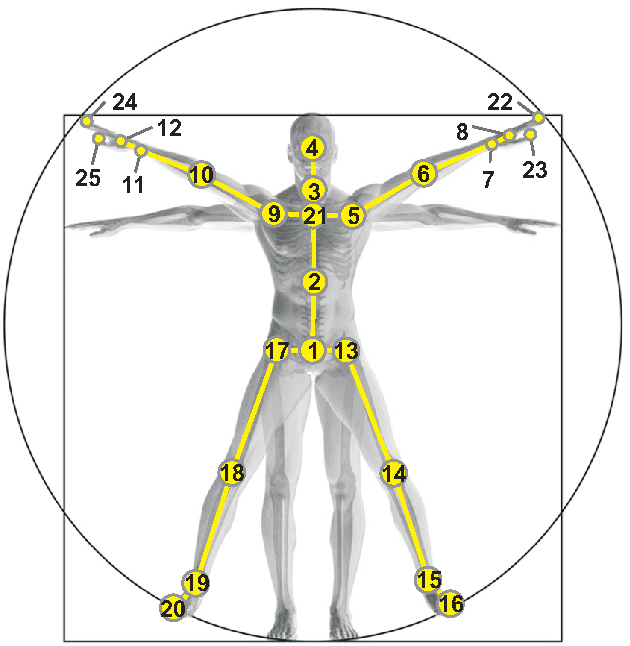
Recent approaches in depth-based human activity analysis achieved outstanding performance and proved the effectiveness of 3D representation for classification of action classes. Currently available depth-based and RGB+D-based action recognition benchmarks have a number of limitations, including the lack of training samples, distinct class labels, camera views and variety of subjects. In this paper we introduce a large-scale dataset for RGB+D human action recognition with more than 56 thousand video samples and 4 million frames, collected from 40 distinct subjects. Our dataset contains 60 different action classes including daily, mutual, and health-related actions. In addition, we propose a new recurrent neural network structure to model the long-term temporal correlation of the features for each body part, and utilize them for better action classification. Experimental results show the advantages of applying deep learning methods over state-of-the-art hand-crafted features on the suggested cross-subject and cross-view evaluation criteria for our dataset. The introduction of this large scale dataset will enable the community to apply, develop and adapt various data-hungry learning techniques for the task of depth-based and RGB+D-based human activity analysis.
Multimodal Multipart Learning for Action Recognition in Depth Videos
Jul 31, 2015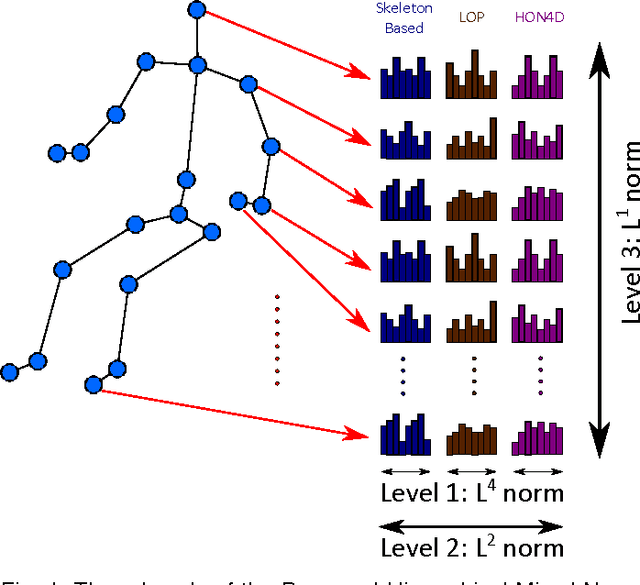


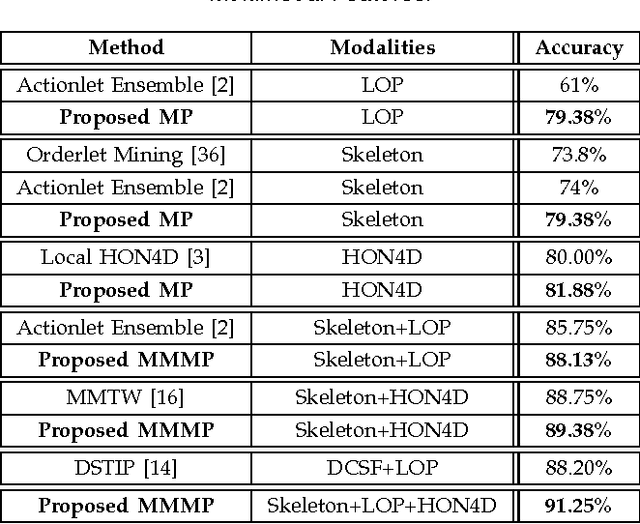
The articulated and complex nature of human actions makes the task of action recognition difficult. One approach to handle this complexity is dividing it to the kinetics of body parts and analyzing the actions based on these partial descriptors. We propose a joint sparse regression based learning method which utilizes the structured sparsity to model each action as a combination of multimodal features from a sparse set of body parts. To represent dynamics and appearance of parts, we employ a heterogeneous set of depth and skeleton based features. The proper structure of multimodal multipart features are formulated into the learning framework via the proposed hierarchical mixed norm, to regularize the structured features of each part and to apply sparsity between them, in favor of a group feature selection. Our experimental results expose the effectiveness of the proposed learning method in which it outperforms other methods in all three tested datasets while saturating one of them by achieving perfect accuracy.