 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Boosting Network For 3D Pose Estimation
Paper and Code
Jan 15, 2019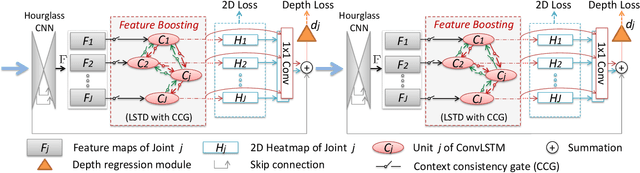
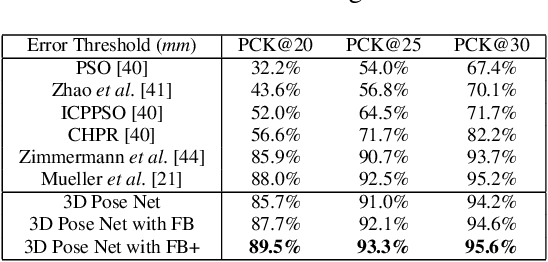
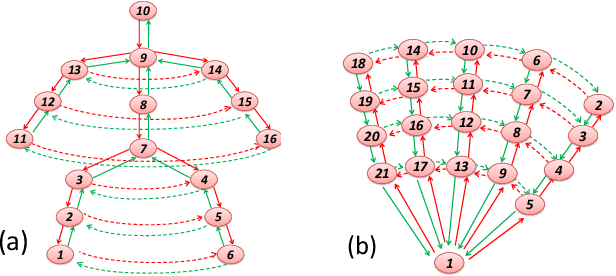

In this paper, a feature boosting network is proposed for estimating 3D hand pose and 3D body pose from a single RGB image. In this method, the features learned by the convolutional layers are boosted with a new long short-term dependence-aware (LSTD) module, which enables the intermediate convolutional feature maps to perceive the graphical long short-term dependency among different hand (or body) parts using the designed Graphical ConvLSTM. Learning a set of features that are reliable and discriminatively representative of the pose of a hand (or body) part is difficult due to the ambiguities, texture and illumination variation, and self-occlusion in the real application of 3D pose estimation. To improve the reliability of the features for representing each body part and enhance the LSTD module, we further introduce a context consistency gate (CCG) in this paper, with which the convolutional feature maps are modulated according to their consistency with the context representations. We evaluate the proposed method on challenging benchmark datasets for 3D hand pose estimation and 3D full body pose estimation. Experimental results show the effectiveness of our method that achieves state-of-the-art performance on both of the tasks.