 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Face Hallucination and Deblurring via Structure Generation and Detail Enhancement
Nov 22, 2018



We address the problem of restoring a high-resolution face image from a blurry low-resolution input. This problem is difficult as super-resolution and deblurring need to be tackled simultaneously. Moreover, existing algorithms cannot handle face images well as low-resolution face images do not have much texture which is especially critical for deblurring. In this paper, we propose an effective algorithm by utilizing the domain-specific knowledge of human faces to recover high-quality faces. We first propose a facial component guided deep Convolutional Neural Network (CNN) to restore a coarse face image, which is denoted as the base image where the facial component is automatically generated from the input face image. However, the CNN based method cannot handle image details well. We further develop a novel exemplar-based detail enhancement algorithm via facial component matching. Extensive experiments show that the proposed method outperforms the state-of-the-art algorithms both quantitatively and qualitatively.
Robust Piecewise-Constant Smoothing: M-Smoother Revisited
Dec 19, 2017



A robust estimator, namely M-smoother, for piecewise-constant smoothing is revisited in this paper. Starting from its generalized formulation, we propose a numerical scheme/framework for solving it via a series of weighted-average filtering (e.g., box filtering, Gaussian filtering, bilateral filtering, and guided filtering). Because of the equivalence between M-smoother and local-histogram-based filters (such as median filter and mode filter), the proposed framework enables fast approximation of histogram filters via a number of box filtering or Gaussian filtering. In addition, high-quality piecewise-constant smoothing can be achieved via a number of bilateral filtering or guided filtering integrated in the proposed framework. Experiments on depth map denoising show the effectiveness of our framework.
Stylizing Face Images via Multiple Exemplars
Aug 28, 2017



We address the problem of transferring the style of a headshot photo to face images. Existing methods using a single exemplar lead to inaccurate results when the exemplar does not contain sufficient stylized facial components for a given photo. In this work, we propose an algorithm to stylize face images using multiple exemplars containing different subjects in the same style. Patch correspondences between an input photo and multiple exemplars are established using a Markov Random Field (MRF), which enables accurate local energy transfer via Laplacian stacks. As image patches from multiple exemplars are used, the boundaries of facial components on the target image are inevitably inconsistent. The artifacts are removed by a post-processing step using an edge-preserving filter. Experimental results show that the proposed algorithm consistently produces visually pleasing results.
Fast Preprocessing for Robust Face Sketch Synthesis
Aug 01, 2017
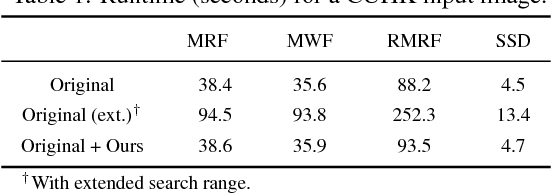
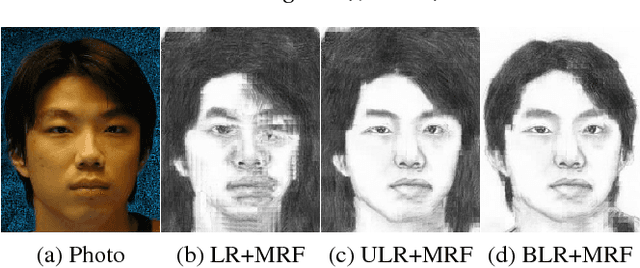

Exemplar-based face sketch synthesis methods usually meet the challenging problem that input photos are captured in different lighting conditions from training photos. The critical step causing the failure is the search of similar patch candidates for an input photo patch. Conventional illumination invariant patch distances are adopted rather than directly relying on pixel intensity difference, but they will fail when local contrast within a patch changes. In this paper, we propose a fast preprocessing method named Bidirectional Luminance Remapping (BLR), which interactively adjust the lighting of training and input photos. Our method can be directly integrated into state-of-the-art exemplar-based methods to improve their robustness with ignorable computational cost.
Learning to Hallucinate Face Images via Component Generation and Enhancement
Aug 01, 2017
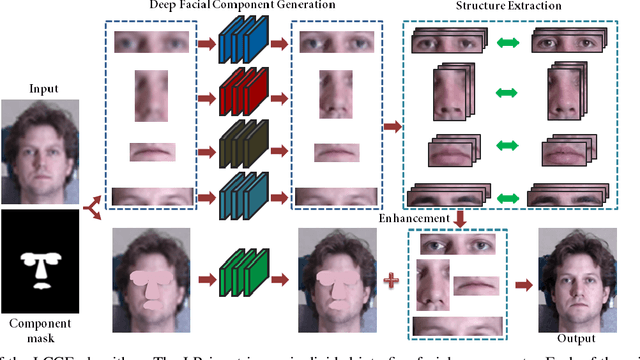


We propose a two-stage method for face hallucination. First, we generate facial components of the input image using CNNs. These components represent the basic facial structures. Second, we synthesize fine-grained facial structures from high resolution training images. The details of these structures are transferred into facial components for enhancement. Therefore, we generate facial components to approximate ground truth global appearance in the first stage and enhance them through recovering details in the second stage. The experiments demonstrate that our method performs favorably against state-of-the-art methods
3D Hand Pose Tracking and Estimation Using Stereo Matching
Oct 23, 2016
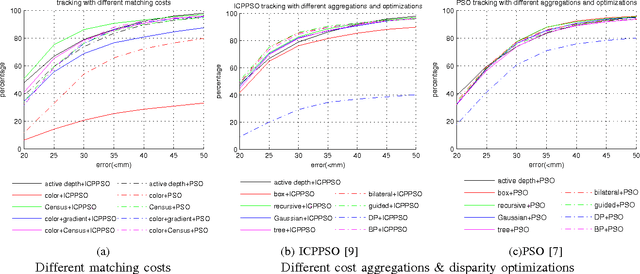
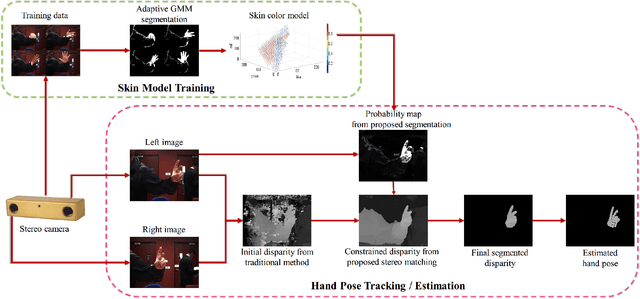

3D hand pose tracking/estimation will be very important in the next generation of human-computer interaction. Most of the currently available algorithms rely on low-cost active depth sensors. However, these sensors can be easily interfered by other active sources and require relatively high power consumption. As a result, they are currently not suitable for outdoor environments and mobile devices. This paper aims at tracking/estimating hand poses using passive stereo which avoids these limitations. A benchmark with 18,000 stereo image pairs and 18,000 depth images captured from different scenarios and the ground-truth 3D positions of palm and finger joints (obtained from the manual label) is thus proposed. This paper demonstrates that the performance of the state-of-the art tracking/estimation algorithms can be maintained with most stereo matching algorithms on the proposed benchmark, as long as the hand segmentation is correct. As a result, a novel stereo-based hand segmentation algorithm specially designed for hand tracking/estimation is proposed. The quantitative evaluation demonstrates that the proposed algorithm is suitable for the state-of-the-art hand pose tracking/estimation algorithms and the tracking quality is comparable to the use of active depth sensors under different challenging scenarios.
RGBD Salient Object Detection via Deep Fusion
Jul 12, 2016



Numerous efforts have been made to design different low level saliency cues for the RGBD saliency detection, such as color or depth contrast features, background and color compactness priors. However, how these saliency cues interact with each other and how to incorporate these low level saliency cues effectively to generate a master saliency map remain a challenging problem. In this paper, we design a new convolutional neural network (CNN) to fuse different low level saliency cues into hierarchical features for automatically detecting salient objects in RGBD images. In contrast to the existing works that directly feed raw image pixels to the CNN, the proposed method takes advantage of the knowledge in traditional saliency detection by adopting various meaningful and well-designed saliency feature vectors as input. This can guide the training of CNN towards detecting salient object more effectively due to the reduced learning ambiguity. We then integrate a Laplacian propagation framework with the learned CNN to extract a spatially consistent saliency map by exploiting the intrinsic structure of the input image. Extensive quantitative and qualitative experimental evaluations on three datasets demonstrate that the proposed method consistently outperforms state-of-the-art methods.
Superpixel Hierarchy
May 20, 2016

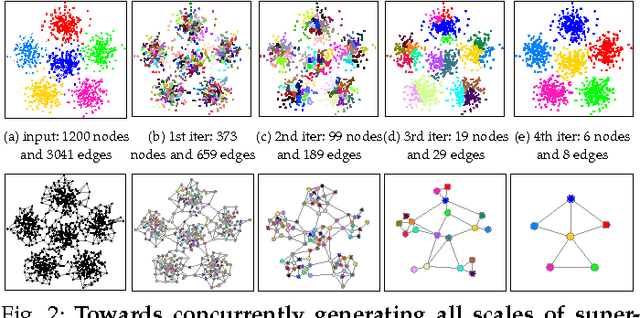

Superpixel segmentation is becoming ubiquitous in computer vision. In practice, an object can either be represented by a number of segments in finer levels of detail or included in a surrounding region at coarser levels of detail, and thus a superpixel segmentation hierarchy is useful for applications that require different levels of image segmentation detail depending on the particular image objects segmented. Unfortunately, there is no method that can generate all scales of superpixels accurately in real-time. As a result, a simple yet effective algorithm named Super Hierarchy (SH) is proposed in this paper. It is as accurate as the state-of-the-art but 1-2 orders of magnitude faster. The proposed method can be directly integrated with recent efficient edge detectors like the structured forest edges to significantly outperforms the state-of-the-art in terms of segmentation accuracy. Quantitative and qualitative evaluation on a number of computer vision applications was conducted, demonstrating that the proposed method is the top performer.
Deep Colorization
Apr 30, 2016



This paper investigates into the colorization problem which converts a grayscale image to a colorful version. This is a very difficult problem and normally requires manual adjustment to achieve artifact-free quality. For instance, it normally requires human-labelled color scribbles on the grayscale target image or a careful selection of colorful reference images (e.g., capturing the same scene in the grayscale target image). Unlike the previous methods, this paper aims at a high-quality fully-automatic colorization method. With the assumption of a perfect patch matching technique, the use of an extremely large-scale reference database (that contains sufficient color images) is the most reliable solution to the colorization problem. However, patch matching noise will increase with respect to the size of the reference database in practice. Inspired by the recent success in deep learning techniques which provide amazing modeling of large-scale data, this paper re-formulates the colorization problem so that deep learning techniques can be directly employed. To ensure artifact-free quality, a joint bilateral filtering based post-processing step is proposed. We further develop an adaptive image clustering technique to incorporate the global image information. Numerous experiments demonstrate that our method outperforms the state-of-art algorithms both in terms of quality and speed.
Video Tracking Using Learned Hierarchical Features
Nov 25, 2015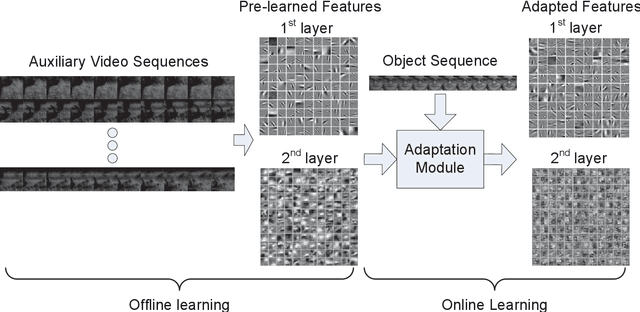



In this paper, we propose an approach to learn hierarchical features for visual object tracking. First, we offline learn features robust to diverse motion patterns from auxiliary video sequences. The hierarchical features are learned via a two-layer convolutional neural network. Embedding the temporal slowness constraint in the stacked architecture makes the learned features robust to complicated motion transformations, which is important for visual object tracking. Then, given a target video sequence, we propose a domain adaptation module to online adapt the pre-learned features according to the specific target object. The adaptation is conducted in both layers of the deep feature learning module so as to include appearance information of the specific target object. As a result, the learned hierarchical features can be robust to both complicated motion transformations and appearance changes of target objects. We integrate our feature learning algorithm into three tracking methods. Experimental results demonstrate that significant improvement can be achieved using our learned hierarchical features, especially on video sequences with complicated motion transformations.
* 12 pages, 7 figures