 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compact Recurrent Neural Networks with Block-Term Tensor Decomposition
May 11, 2018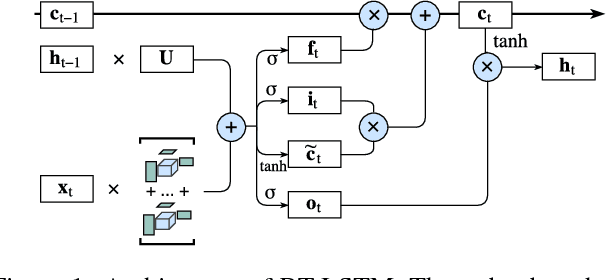
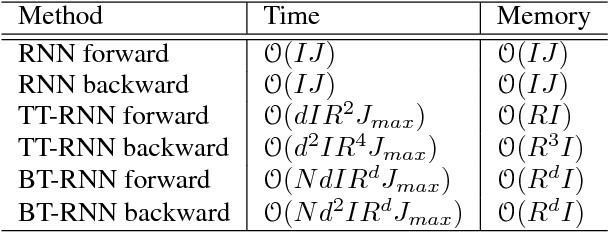
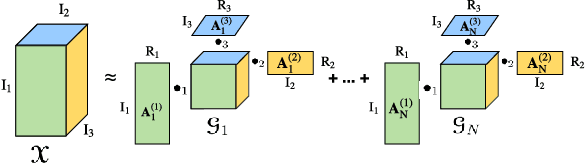
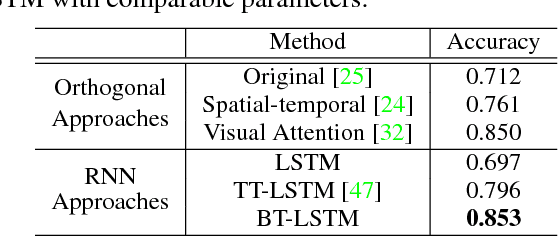
Recurrent Neural Networks (RNNs) are powerful sequence modeling tools. However, when dealing with high dimensional inputs, the training of RNNs becomes computational expensive due to the large number of model parameters. This hinders RNNs from solving many important computer vision tasks, such as Action Recognition in Videos and Image Captioning. To overcome this problem, we propose a compact and flexible structure, namely Block-Term tensor decomposition, which greatly reduces the parameters of RNNs and improves their training efficiency. Compared with alternative low-rank approximations, such as tensor-train RNN (TT-RNN), our method, Block-Term RNN (BT-RNN), is not only more concise (when using the same rank), but also able to attain a better approximation to the original RNNs with much fewer parameters. On three challenging tasks, including Action Recognition in Videos, Image Captioning and Image Generation, BT-RNN outperforms TT-RNN and the standard RNN in terms of both prediction accuracy and convergence rate. Specifically, BT-LSTM utilizes 17,388 times fewer parameters than the standard LSTM to achieve an accuracy improvement over 15.6\% in the Action Recognition task on the UCF11 dataset.
Epitome for Automatic Image Colorization
Oct 08, 2012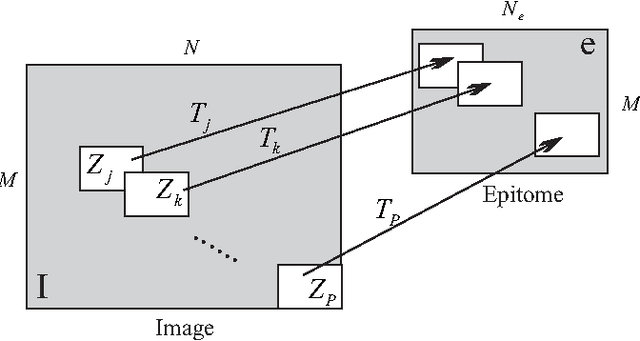
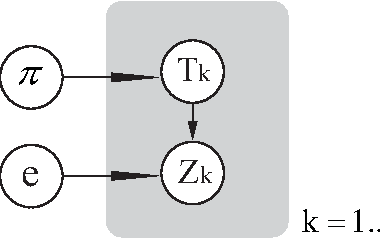


Image colorization adds color to grayscale images. It not only increases the visual appeal of grayscale images, but also enriches the information contained in scientific images that lack color information. Most existing methods of colorization require laborious user interaction for scribbles or image segmentation. To eliminate the need for human labor, we develop an automatic image colorization method using epitome. Built upon a generative graphical model, epitome is a condensed image appearance and shape model which also proves to be an effective summary of color information for the colorization task. We train the epitome from the reference images and perform inference in the epitome to colorize grayscale images, rendering better colorization results than previous method in our experiments.