 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUHD-IQA Benchmark Database: Pushing the Boundaries of Blind Photo Quality Assessment
Jun 25, 2024We introduce a novel Image Quality Assessment (IQA) dataset comprising 6073 UHD-1 (4K) images, annotated at a fixed width of 3840 pixels. Contrary to existing No-Reference (NR) IQA datasets, ours focuses on highly aesthetic photos of high technical quality, filling a gap in the literature. The images, carefully curated to exclude synthetic content, are sufficiently diverse to train general NR-IQA models. The dataset is annotated with perceptual quality ratings obtained through a crowdsourcing study. Ten expert raters, comprising photographers and graphics artists, assessed each image at least twice in multiple sessions spanning several days, resulting in highly reliable labels. Annotators were rigorously selected based on several metrics, including self-consistency, to ensure their reliability. The dataset includes rich metadata with user and machine-generated tags from over 5,000 categories and popularity indicators such as favorites, likes, downloads, and views. With its unique characteristics, such as its focus on high-quality images, reliable crowdsourced annotations, and high annotation resolution, our dataset opens up new opportunities for advancing perceptual image quality assessment research and developing practical NR-IQA models that apply to modern photos. Our dataset is available at https://database.mmsp-kn.de/uhd-iqa-benchmark-database.html
Localization of Just Noticeable Difference for Image Compression
Jun 13, 2023



The just noticeable difference (JND) is the minimal difference between stimuli that can be detected by a person. The picture-wise just noticeable difference (PJND) for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction. These differences can only be observed in some specific regions within the image, dubbed as JND-critical regions. Identifying these regions can improve the development of image compression algorithms. Due to the fact that visual perception varies among individuals, determining the PJND values and JND-critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers. In this paper, we propose a novel framework for conducting such experiments using crowdsourcing. By applying this framework, we created a novel PJND dataset, KonJND++, consisting of 300 source images, compressed versions thereof under JPEG or BPG compression, and an average of 43 ratings of PJND and 129 self-reported locations of JND-critical regions for each source image. Our experiments demonstrate the effectiveness and reliability of our proposed framework, which is easy to be adapted for collecting a large-scale dataset. The source code and dataset are available at https://github.com/angchen-dev/LocJND.
KonX: Cross-Resolution Image Quality Assessment
Dec 12, 2022Scale-invariance is an open problem in many computer vision subfields. For example, object labels should remain constant across scales, yet model predictions diverge in many cases. This problem gets harder for tasks where the ground-truth labels change with the presentation scale. In image quality assessment (IQA), downsampling attenuates impairments, e.g., blurs or compression artifacts, which can positively affect the impression evoked in subjective studies. To accurately predict perceptual image quality, cross-resolution IQA methods must therefore account for resolution-dependent errors induced by model inadequacies as well as for the perceptual label shifts in the ground truth. We present the first study of its kind that disentangles and examines the two issues separately via KonX, a novel, carefully crafted cross-resolution IQA database. This paper contributes the following: 1. Through KonX, we provide empirical evidence of label shifts caused by changes in the presentation resolution. 2. We show that objective IQA methods have a scale bias, which reduces their predictive performance. 3. We propose a multi-scale and multi-column DNN architecture that improves performance over previous state-of-the-art IQA models for this task, including recent transformers. We thus both raise and address a novel research problem in image quality assessment.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
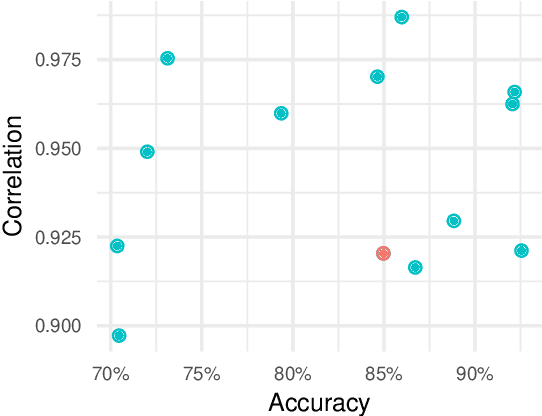

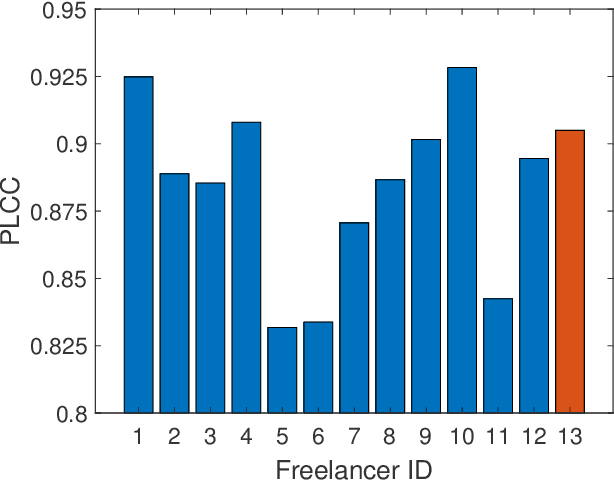
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.