 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Image-Text Alignment for Real-World Image Quality Assessment
Mar 17, 2024No-Reference Image Quality Assessment (NR-IQA) focuses on designing methods to measure image quality in alignment with human perception when a high-quality reference image is unavailable. The reliance on annotated Mean Opinion Scores (MOS) in the majority of state-of-the-art NR-IQA approaches limits their scalability and broader applicability to real-world scenarios. To overcome this limitation, we propose QualiCLIP (Quality-aware CLIP), a CLIP-based self-supervised opinion-unaware method that does not require labeled MOS. In particular, we introduce a quality-aware image-text alignment strategy to make CLIP generate representations that correlate with the inherent quality of the images. Starting from pristine images, we synthetically degrade them with increasing levels of intensity. Then, we train CLIP to rank these degraded images based on their similarity to quality-related antonym text prompts, while guaranteeing consistent representations for images with comparable quality. Our method achieves state-of-the-art performance on several datasets with authentic distortions. Moreover, despite not requiring MOS, QualiCLIP outperforms supervised methods when their training dataset differs from the testing one, thus proving to be more suitable for real-world scenarios. Furthermore, our approach demonstrates greater robustness and improved explainability than competing methods. The code and the model are publicly available at https://github.com/miccunifi/QualiCLIP.
Restoration of Analog Videos Using Swin-UNet
Nov 07, 2023In this paper, we present a system to restore analog videos of historical archives. These videos often contain severe visual degradation due to the deterioration of their tape supports that require costly and slow manual interventions to recover the original content. The proposed system uses a multi-frame approach and is able to deal with severe tape mistracking, which results in completely scrambled frames. Tests on real-world videos from a major historical video archive show the effectiveness of our demo system. The code and the pre-trained model are publicly available at https://github.com/miccunifi/analog-video-restoration.
Perceptual Quality Improvement in Videoconferencing using Keyframes-based GAN
Nov 07, 2023In the latest years, videoconferencing has taken a fundamental role in interpersonal relations, both for personal and business purposes. Lossy video compression algorithms are the enabling technology for videoconferencing, as they reduce the bandwidth required for real-time video streaming. However, lossy video compression decreases the perceived visual quality. Thus, many techniques for reducing compression artifacts and improving video visual quality have been proposed in recent years. In this work, we propose a novel GAN-based method for compression artifacts reduction in videoconferencing. Given that, in this context, the speaker is typically in front of the camera and remains the same for the entire duration of the transmission, we can maintain a set of reference keyframes of the person from the higher-quality I-frames that are transmitted within the video stream and exploit them to guide the visual quality improvement; a novel aspect of this approach is the update policy that maintains and updates a compact and effective set of reference keyframes. First, we extract multi-scale features from the compressed and reference frames. Then, our architecture combines these features in a progressive manner according to facial landmarks. This allows the restoration of the high-frequency details lost after the video compression. Experiments show that the proposed approach improves visual quality and generates photo-realistic results even with high compression rates. Code and pre-trained networks are publicly available at https://github.com/LorenzoAgnolucci/Keyframes-GAN.
Reference-based Restoration of Digitized Analog Videotapes
Nov 03, 2023Analog magnetic tapes have been the main video data storage device for several decades. Videos stored on analog videotapes exhibit unique degradation patterns caused by tape aging and reader device malfunctioning that are different from those observed in film and digital video restoration tasks. In this work, we present a reference-based approach for the resToration of digitized Analog videotaPEs (TAPE). We leverage CLIP for zero-shot artifact detection to identify the cleanest frames of each video through textual prompts describing different artifacts. Then, we select the clean frames most similar to the input ones and employ them as references. We design a transformer-based Swin-UNet network that exploits both neighboring and reference frames via our Multi-Reference Spatial Feature Fusion (MRSFF) blocks. MRSFF blocks rely on cross-attention and attention pooling to take advantage of the most useful parts of each reference frame. To address the absence of ground truth in real-world videos, we create a synthetic dataset of videos exhibiting artifacts that closely resemble those commonly found in analog videotapes. Both quantitative and qualitative experiments show the effectiveness of our approach compared to other state-of-the-art methods. The code, the model, and the synthetic dataset are publicly available at https://github.com/miccunifi/TAPE.
ARNIQA: Learning Distortion Manifold for Image Quality Assessment
Oct 20, 2023No-Reference Image Quality Assessment (NR-IQA) aims to develop methods to measure image quality in alignment with human perception without the need for a high-quality reference image. In this work, we propose a self-supervised approach named ARNIQA (leArning distoRtion maNifold for Image Quality Assessment) for modeling the image distortion manifold to obtain quality representations in an intrinsic manner. First, we introduce an image degradation model that randomly composes ordered sequences of consecutively applied distortions. In this way, we can synthetically degrade images with a large variety of degradation patterns. Second, we propose to train our model by maximizing the similarity between the representations of patches of different images distorted equally, despite varying content. Therefore, images degraded in the same manner correspond to neighboring positions within the distortion manifold. Finally, we map the image representations to the quality scores with a simple linear regressor, thus without fine-tuning the encoder weights. The experiments show that our approach achieves state-of-the-art performance on several datasets. In addition, ARNIQA demonstrates improved data efficiency, generalization capabilities, and robustness compared to competing methods. The code and the model are publicly available at https://github.com/miccunifi/ARNIQA.
Robust pedestrian detection in thermal imagery using synthesized images
Feb 03, 2021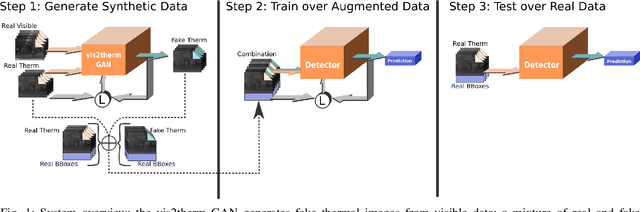
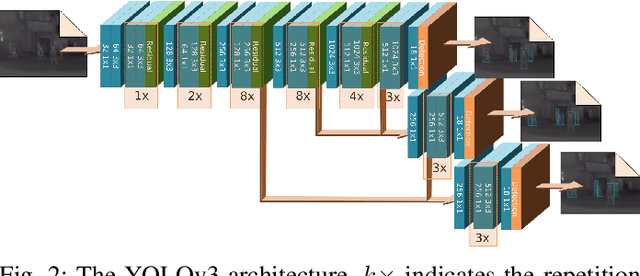

In this paper we propose a method for improving pedestrian detection in the thermal domain using two stages: first, a generative data augmentation approach is used, then a domain adaptation method using generated data adapts an RGB pedestrian detector. Our model, based on the Least-Squares Generative Adversarial Network, is trained to synthesize realistic thermal versions of input RGB images which are then used to augment the limited amount of labeled thermal pedestrian images available for training. We apply our generative data augmentation strategy in order to adapt a pretrained YOLOv3 pedestrian detector to detection in the thermal-only domain. Experimental results demonstrate the effectiveness of our approach: using less than 50\% of available real thermal training data, and relying on synthesized data generated by our model in the domain adaptation phase, our detector achieves state-of-the-art results on the KAIST Multispectral Pedestrian Detection Benchmark; even if more real thermal data is available adding GAN generated images to the training data results in improved performance, thus showing that these images act as an effective form of data augmentation. To the best of our knowledge, our detector achieves the best single-modality detection results on KAIST with respect to the state-of-the-art.
Semantic Road Layout Understanding by Generative Adversarial Inpainting
May 29, 2018
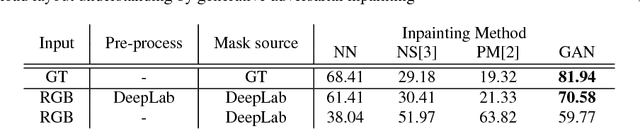
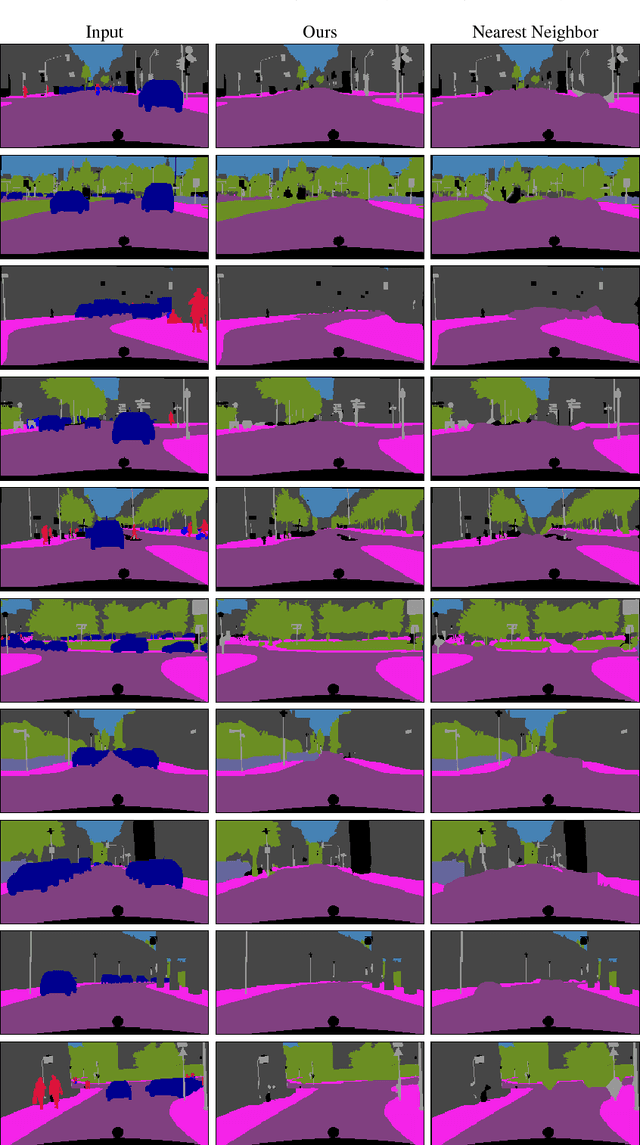
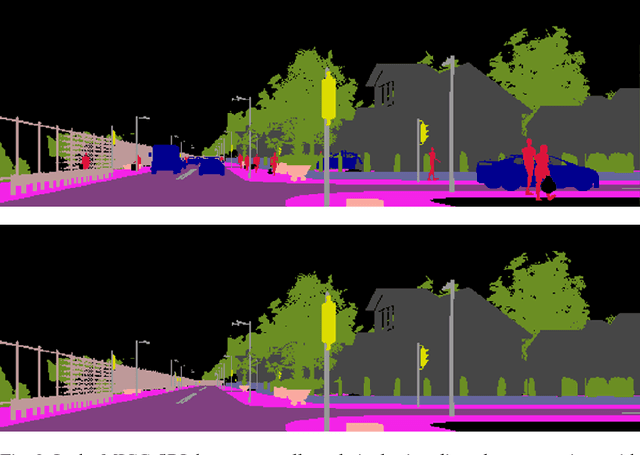
Autonomous driving is becoming a reality, yet vehicles still need to rely on complex sensor fusion techniques to fully understand the scene they act in. Being able to discern the static environment from the dynamic entities that populate it, will improve scene comprehension algorithms and will pose constraints to the reasoning process about moving objects. With this in mind, we propose a scene comprehension task aimed at providing a complete understanding of the static surroundings, with a particular attention to road layout. In order to cut to the bare minimum the sensor requirements to be deployed on-board, we solely rely on semantic segmentation masks, which can be reliably obtained with computer vision algorithms from any RGB source. We cast this problem as an inpainting task based on a Generative Adversarial Network model to remove all dynamic objects from the scene and focus on understanding its static components such as streets, sidewalks and buildings. We evaluate this task on a synthetically generated dataset obtained with the CARLA simulator, demonstrating the effectiveness of our method.
Deep Generative Adversarial Compression Artifact Removal
Dec 06, 2017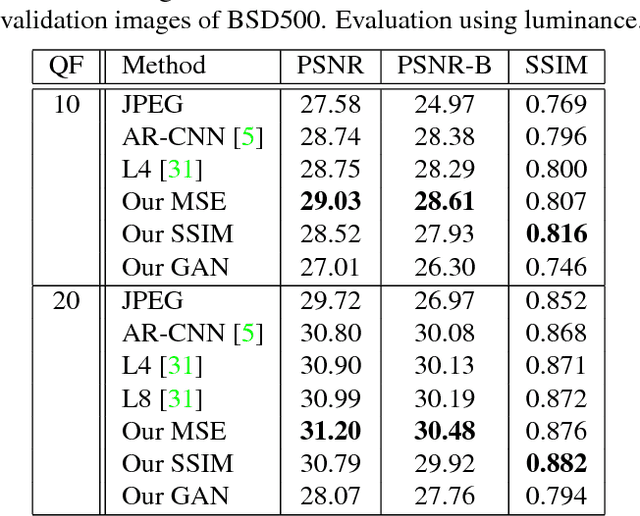

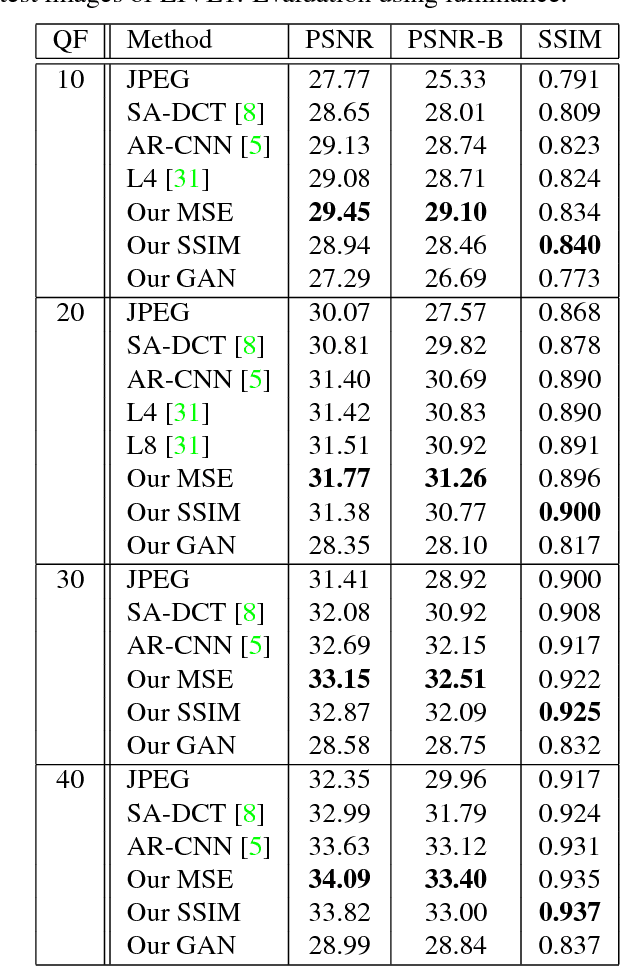
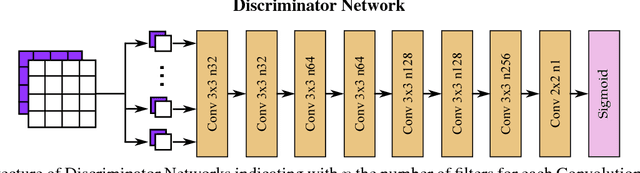
Compression artifacts arise in images whenever a lossy compression algorithm is applied. These artifacts eliminate details present in the original image, or add noise and small structures; because of these effects they make images less pleasant for the human eye, and may also lead to decreased performance of computer vision algorithms such as object detectors. To eliminate such artifacts, when decompressing an image, it is required to recover the original image from a disturbed version. To this end, we present a feed-forward fully convolutional residual network model trained using a generative adversarial framework. To provide a baseline, we show that our model can be also trained optimizing the Structural Similarity (SSIM), which is a better loss with respect to the simpler Mean Squared Error (MSE). Our GAN is able to produce images with more photorealistic details than MSE or SSIM based networks. Moreover we show that our approach can be used as a pre-processing step for object detection in case images are degraded by compression to a point that state-of-the art detectors fail. In this task, our GAN method obtains better performance than MSE or SSIM trained networks.