 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Road Layout Understanding by Generative Adversarial Inpainting
Paper and Code
May 29, 2018
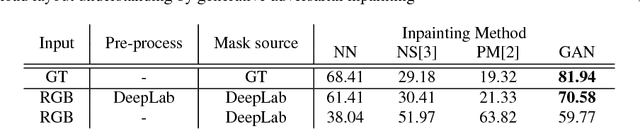
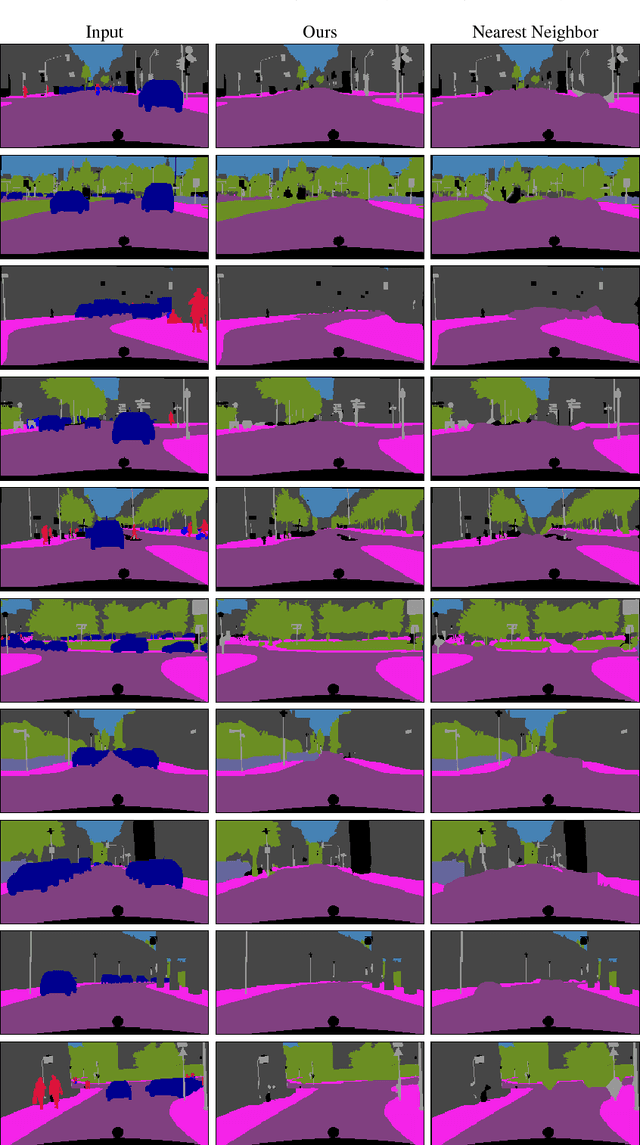
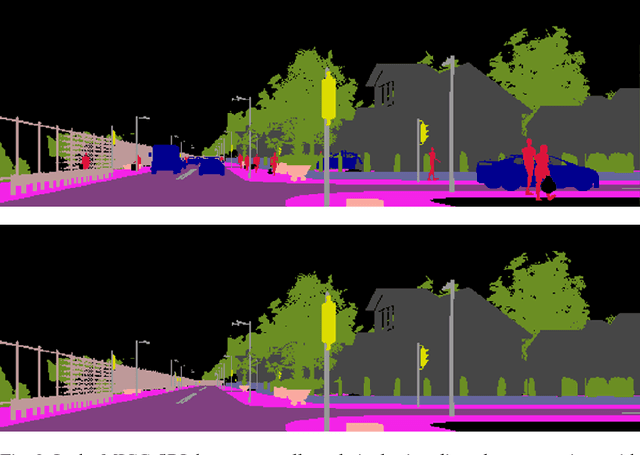
Autonomous driving is becoming a reality, yet vehicles still need to rely on complex sensor fusion techniques to fully understand the scene they act in. Being able to discern the static environment from the dynamic entities that populate it, will improve scene comprehension algorithms and will pose constraints to the reasoning process about moving objects. With this in mind, we propose a scene comprehension task aimed at providing a complete understanding of the static surroundings, with a particular attention to road layout. In order to cut to the bare minimum the sensor requirements to be deployed on-board, we solely rely on semantic segmentation masks, which can be reliably obtained with computer vision algorithms from any RGB source. We cast this problem as an inpainting task based on a Generative Adversarial Network model to remove all dynamic objects from the scene and focus on understanding its static components such as streets, sidewalks and buildings. We evaluate this task on a synthetically generated dataset obtained with the CARLA simulator, demonstrating the effectiveness of our method.