 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-Shot Object-Level Change Detection by Incorporating Visual Correspondence
Jan 09, 2025
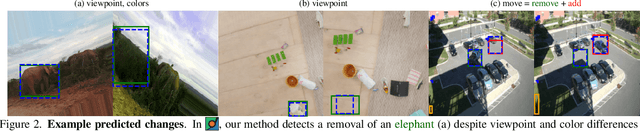

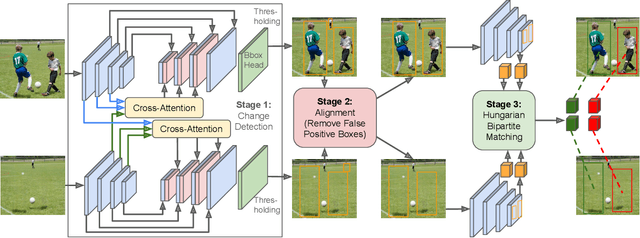
Detecting object-level changes between two images across possibly different views is a core task in many applications that involve visual inspection or camera surveillance. Existing change-detection approaches suffer from three major limitations: (1) lack of evaluation on image pairs that contain no changes, leading to unreported false positive rates; (2) lack of correspondences (\ie, localizing the regions before and after a change); and (3) poor zero-shot generalization across different domains. To address these issues, we introduce a novel method that leverages change correspondences (a) during training to improve change detection accuracy, and (b) at test time, to minimize false positives. That is, we harness the supervision labels of where an object is added or removed to supervise change detectors, improving their accuracy over previous work by a large margin. Our work is also the first to predict correspondences between pairs of detected changes using estimated homography and the Hungarian algorithm. Our model demonstrates superior performance over existing methods, achieving state-of-the-art results in change detection and change correspondence accuracy across both in-distribution and zero-shot benchmarks.
Vision language models are blind
Jul 11, 2024Large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro are powering countless image-text applications and scoring high on many vision-understanding benchmarks. We propose BlindTest, a suite of 7 visual tasks absurdly easy to humans such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting the number of circles in a Olympic-like logo. Surprisingly, four state-of-the-art VLMs are, on average, only 56.20% accurate on our benchmark, with \newsonnet being the best (73.77% accuracy). On BlindTest, VLMs struggle with tasks that requires precise spatial information and counting (from 0 to 10), sometimes providing an impression of a person with myopia seeing fine details as blurry and making educated guesses. Code is available at: https://vlmsareblind.github.io/