 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-Shot Object-Level Change Detection by Incorporating Visual Correspondence
Jan 09, 2025
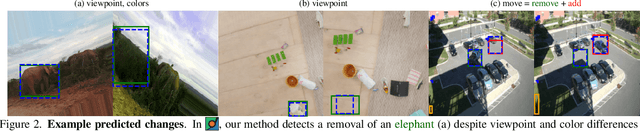

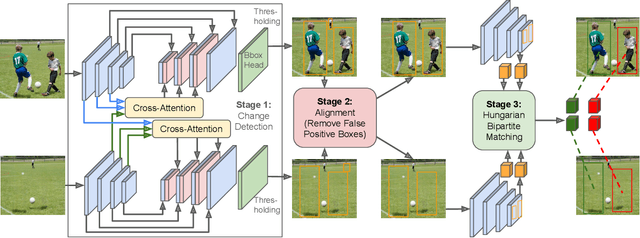
Detecting object-level changes between two images across possibly different views is a core task in many applications that involve visual inspection or camera surveillance. Existing change-detection approaches suffer from three major limitations: (1) lack of evaluation on image pairs that contain no changes, leading to unreported false positive rates; (2) lack of correspondences (\ie, localizing the regions before and after a change); and (3) poor zero-shot generalization across different domains. To address these issues, we introduce a novel method that leverages change correspondences (a) during training to improve change detection accuracy, and (b) at test time, to minimize false positives. That is, we harness the supervision labels of where an object is added or removed to supervise change detectors, improving their accuracy over previous work by a large margin. Our work is also the first to predict correspondences between pairs of detected changes using estimated homography and the Hungarian algorithm. Our model demonstrates superior performance over existing methods, achieving state-of-the-art results in change detection and change correspondence accuracy across both in-distribution and zero-shot benchmarks.
TAB: Transformer Attention Bottlenecks enable User Intervention and Debugging in Vision-Language Models
Dec 24, 2024Multi-head self-attention (MHSA) is a key component of Transformers, a widely popular architecture in both language and vision. Multiple heads intuitively enable different parallel processes over the same input. Yet, they also obscure the attribution of each input patch to the output of a model. We propose a novel 1-head Transformer Attention Bottleneck (TAB) layer, inserted after the traditional MHSA architecture, to serve as an attention bottleneck for interpretability and intervention. Unlike standard self-attention, TAB constrains the total attention over all patches to $\in [0, 1]$. That is, when the total attention is 0, no visual information is propagated further into the network and the vision-language model (VLM) would default to a generic, image-independent response. To demonstrate the advantages of TAB, we train VLMs with TAB to perform image difference captioning. Over three datasets, our models perform similarly to baseline VLMs in captioning but the bottleneck is superior in localizing changes and in identifying when no changes occur. TAB is the first architecture to enable users to intervene by editing attention, which often produces expected outputs by VLMs.