 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePan More Gold from the Sand: Refining Open-domain Dialogue Training with Noisy Self-Retrieval Generation
Paper and Code
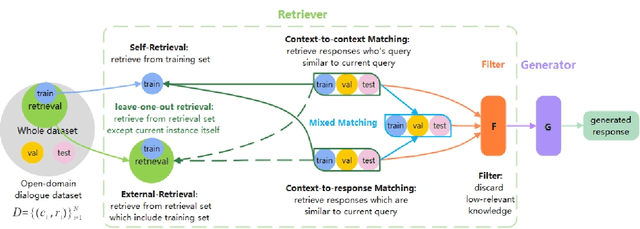
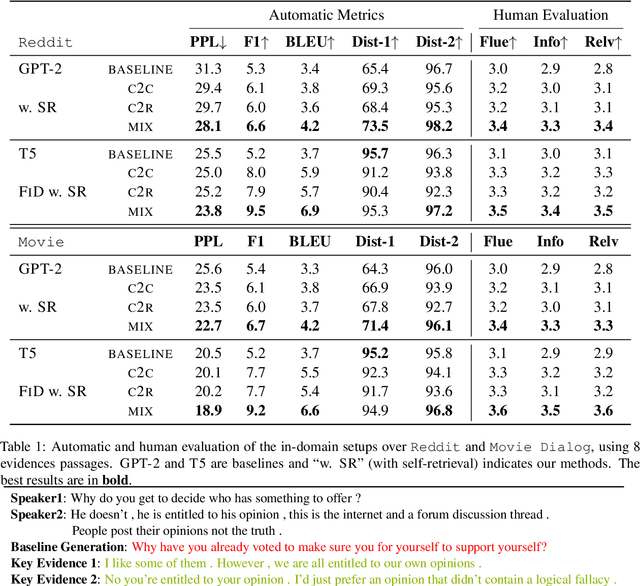
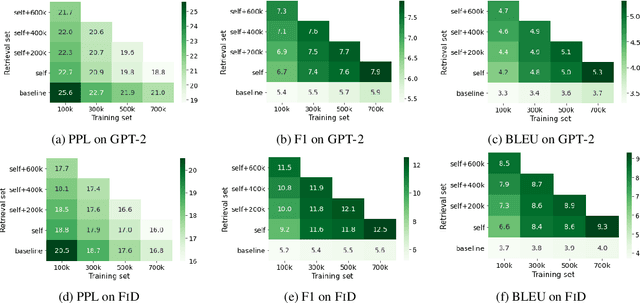
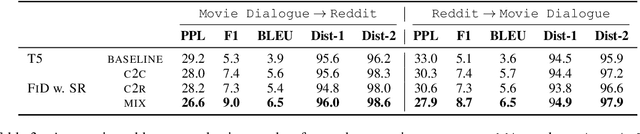
Real human conversation data are complicated, heterogeneous, and noisy, from whom building open-domain dialogue systems remains a challenging task. In fact, such dialogue data can still contain a wealth of information and knowledge, however, they are not fully explored. In this paper, we show existing open-domain dialogue generation methods by memorizing context-response paired data with causal or encode-decode language models underutilize the training data. Different from current approaches, using external knowledge, we explore a retrieval-generation training framework that can increase the usage of training data by directly considering the heterogeneous and noisy training data as the "evidence". Experiments over publicly available datasets demonstrate that our method can help models generate better responses, even such training data are usually impressed as low-quality data. Such performance gain is comparable with those improved by enlarging the training set, even better. We also found that the model performance has a positive correlation with the relevance of the retrieved evidence. Moreover, our method performed well on zero-shot experiments, which indicates that our method can be more robust to real-world data.