 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy of Thoughts: Scaling LLM Reasoning via Test-time Policy Evolution
Jan 28, 2026Large language models (LLMs) struggle with complex, long-horizon reasoning due to instability caused by their frozen policy assumption. Current test-time scaling methods treat execution feedback merely as an external signal for filtering or rewriting trajectories, without internalizing it to improve the underlying reasoning strategy. Inspired by Popper's epistemology of "conjectures and refutations," we argue that intelligence requires real-time evolution of the model's policy through learning from failed attempts. We introduce Policy of Thoughts (PoT), a framework that recasts reasoning as a within-instance online optimization process. PoT first generates diverse candidate solutions via an efficient exploration mechanism, then uses Group Relative Policy Optimization (GRPO) to update a transient LoRA adapter based on execution feedback. This closed-loop design enables dynamic, instance-specific refinement of the model's reasoning priors. Experiments show that PoT dramatically boosts performance: a 4B model achieves 49.71% accuracy on LiveCodeBench, outperforming GPT-4o and DeepSeek-V3 despite being over 50 smaller.
Imperceptible but Forgeable: Practical Invisible Watermark Forgery via Diffusion Models
Mar 28, 2025Invisible watermarking is critical for content provenance and accountability in Generative AI. Although commercial companies have increasingly committed to using watermarks, the robustness of existing watermarking schemes against forgery attacks is understudied. This paper proposes DiffForge, the first watermark forgery framework capable of forging imperceptible watermarks under a no-box setting. We estimate the watermark distribution using an unconditional diffusion model and introduce shallow inversion to inject the watermark into a non-watermarked image seamlessly. This approach facilitates watermark injection while preserving image quality by adaptively selecting the depth of inversion steps, leveraging our key insight that watermarks degrade with added noise during the early diffusion phases. Comprehensive evaluations show that DiffForge deceives open-source watermark detectors with a 96.38% success rate and misleads a commercial watermark system with over 97% success rate, achieving high confidence.1 This work reveals fundamental security limitations in current watermarking paradigms.
Robust Watermarks Leak: Channel-Aware Feature Extraction Enables Adversarial Watermark Manipulation
Feb 10, 2025



Watermarking plays a key role in the provenance and detection of AI-generated content. While existing methods prioritize robustness against real-world distortions (e.g., JPEG compression and noise addition), we reveal a fundamental tradeoff: such robust watermarks inherently improve the redundancy of detectable patterns encoded into images, creating exploitable information leakage. To leverage this, we propose an attack framework that extracts leakage of watermark patterns through multi-channel feature learning using a pre-trained vision model. Unlike prior works requiring massive data or detector access, our method achieves both forgery and detection evasion with a single watermarked image. Extensive experiments demonstrate that our method achieves a 60\% success rate gain in detection evasion and 51\% improvement in forgery accuracy compared to state-of-the-art methods while maintaining visual fidelity. Our work exposes the robustness-stealthiness paradox: current "robust" watermarks sacrifice security for distortion resistance, providing insights for future watermark design.
Reverse Attitude Statistics Based Star Map Identification Method
Oct 31, 2024



The star tracker is generally affected by the atmospheric background light and the aerodynamic environment when working in near space, which results in missing stars or false stars. Moreover, high-speed maneuvering may cause star trailing, which reduces the accuracy of the star position. To address the challenges for starmap identification, a reverse attitude statistics based method is proposed to handle position noise, false stars, and missing stars. Conversely to existing methods which match before solving for attitude, this method introduces attitude solving into the matching process, and obtains the final match and the correct attitude simultaneously by frequency statistics. Firstly, based on stable angular distance features, the initial matching is obtained by utilizing spatial hash indexing. Then, the dual-vector attitude determination is introduced to calculate potential attitude. Finally, the star pairs are accurately matched by applying a frequency statistics filtering method. In addition, Bayesian optimization is employed to find optimal parameters under the impact of noises, which is able to enhance the algorithm performance further. In this work, the proposed method is validated in simulation, field test and on-orbit experiment. Compared with the state-of-the-art, the identification rate is improved by more than 14.3%, and the solving time is reduced by over 28.5%.
SurrogatePrompt: Bypassing the Safety Filter of Text-To-Image Models via Substitution
Sep 25, 2023



Advanced text-to-image models such as DALL-E 2 and Midjourney possess the capacity to generate highly realistic images, raising significant concerns regarding the potential proliferation of unsafe content. This includes adult, violent, or deceptive imagery of political figures. Despite claims of rigorous safety mechanisms implemented in these models to restrict the generation of not-safe-for-work (NSFW) content, we successfully devise and exhibit the first prompt attacks on Midjourney, resulting in the production of abundant photorealistic NSFW images. We reveal the fundamental principles of such prompt attacks and suggest strategically substituting high-risk sections within a suspect prompt to evade closed-source safety measures. Our novel framework, SurrogatePrompt, systematically generates attack prompts, utilizing large language models, image-to-text, and image-to-image modules to automate attack prompt creation at scale. Evaluation results disclose an 88% success rate in bypassing Midjourney's proprietary safety filter with our attack prompts, leading to the generation of counterfeit images depicting political figures in violent scenarios. Both subjective and objective assessments validate that the images generated from our attack prompts present considerable safety hazards.
Connecting First and Second Order Recurrent Networks with Deterministic Finite Automata
Nov 12, 2019

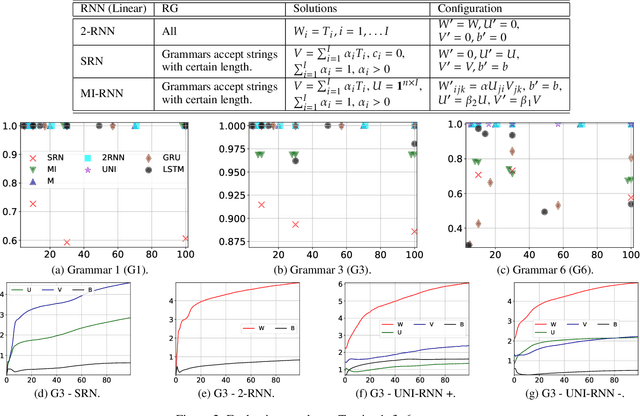
We propose an approach that connects recurrent networks with different orders of hidden interaction with regular grammars of different levels of complexity. We argue that the correspondence between recurrent networks and formal computational models gives understanding to the analysis of the complicated behaviors of recurrent networks. We introduce an entropy value that categorizes all regular grammars into three classes with different levels of complexity, and show that several existing recurrent networks match grammars from either all or partial classes. As such, the differences between regular grammars reveal the different properties of these models. We also provide a unification of all investigated recurrent networks. Our evaluation shows that the unified recurrent network has improved performance in learning grammars, and demonstrates comparable performance on a real-world dataset with more complicated models.
Shapley Homology: Topological Analysis of Sample Influence for Neural Networks
Oct 15, 2019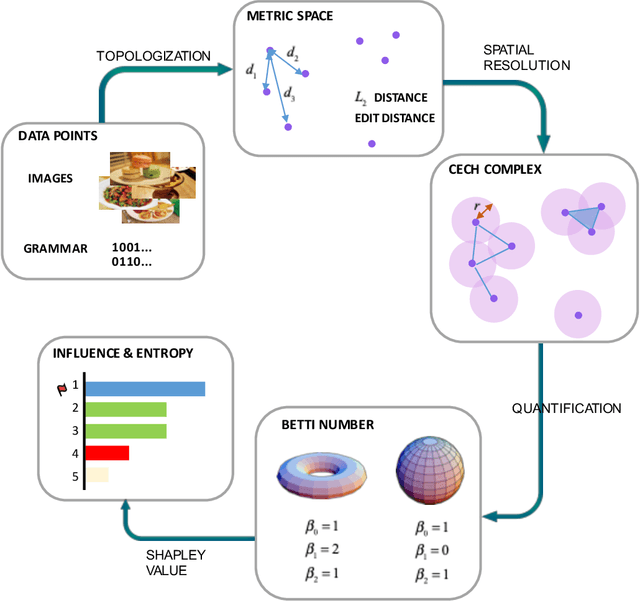

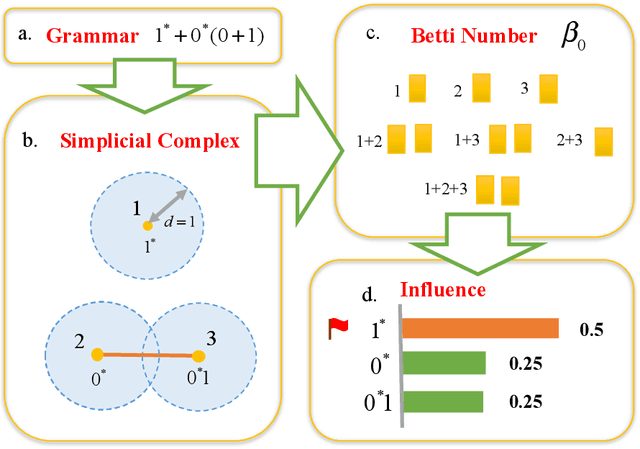
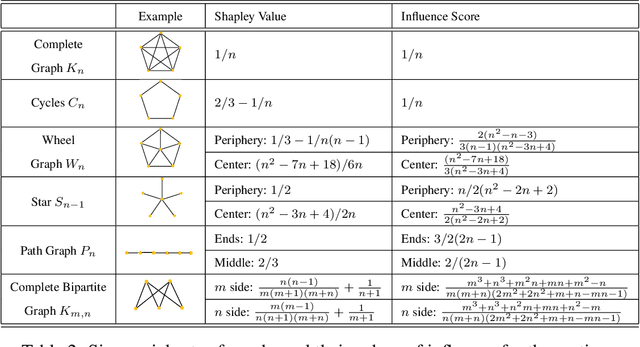
Data samples collected for training machine learning models are typically assumed to be independent and identically distributed (iid). Recent research has demonstrated that this assumption can be problematic as it simplifies the manifold of structured data. This has motivated different research areas such as data poisoning, model improvement, and explanation of machine learning models. In this work, we study the influence of a sample on determining the intrinsic topological features of its underlying manifold. We propose the Shapley Homology framework, which provides a quantitative metric for the influence of a sample of the homology of a simplicial complex. By interpreting the influence as a probability measure, we further define an entropy which reflects the complexity of the data manifold. Our empirical studies show that when using the 0-dimensional homology, on neighboring graphs, samples with higher influence scores have more impact on the accuracy of neural networks for determining the graph connectivity and on several regular grammars whose higher entropy values imply more difficulty in being learned.
Verification of Recurrent Neural Networks Through Rule Extraction
Nov 14, 2018
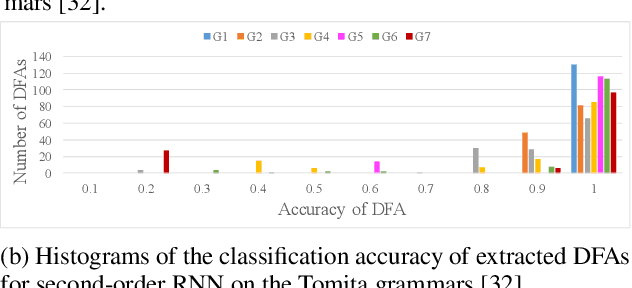
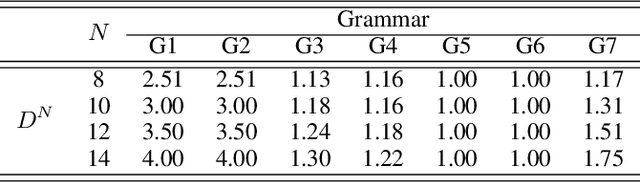
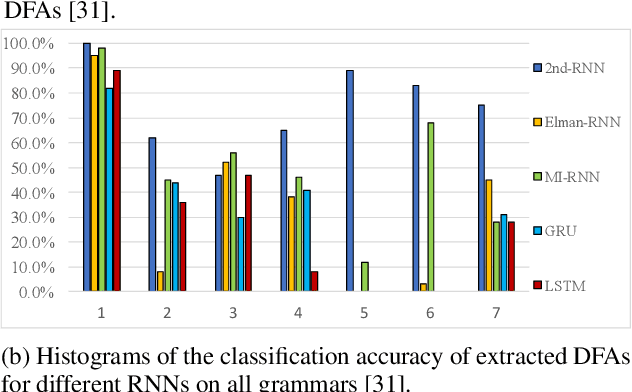
The verification problem for neural networks is verifying whether a neural network will suffer from adversarial samples, or approximating the maximal allowed scale of adversarial perturbation that can be endured. While most prior work contributes to verifying feed-forward networks, little has been explored for verifying recurrent networks. This is due to the existence of a more rigorous constraint on the perturbation space for sequential data, and the lack of a proper metric for measuring the perturbation. In this work, we address these challenges by proposing a metric which measures the distance between strings, and use deterministic finite automata (DFA) to represent a rigorous oracle which examines if the generated adversarial samples violate certain constraints on a perturbation. More specifically, we empirically show that certain recurrent networks allow relatively stable DFA extraction. As such, DFAs extracted from these recurrent networks can serve as a surrogate oracle for when the ground truth DFA is unknown. We apply our verification mechanism to several widely used recurrent networks on a set of the Tomita grammars. The results demonstrate that only a few models remain robust against adversarial samples. In addition, we show that for grammars with different levels of complexity, there is also a difference in the difficulty of robust learning of these grammars.
Energy Spatio-Temporal Pattern Prediction for Electric Vehicle Networks
Feb 14, 2018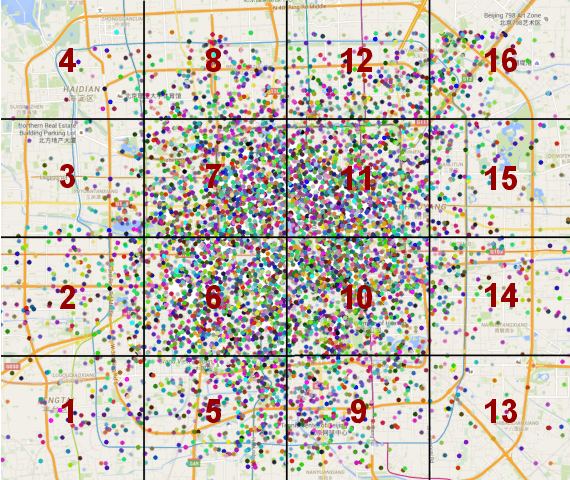



Information about the spatio-temporal pattern of electricity energy carried by EVs, instead of EVs themselves, is crucial for EVs to establish more effective and intelligent interactions with the smart grid. In this paper, we propose a framework for predicting the amount of the electricity energy stored by a large number of EVs aggregated within different city-scale regions, based on spatio-temporal pattern of the electricity energy. The spatial pattern is modeled via using a neural network based spatial predictor, while the temporal pattern is captured via using a linear-chain conditional random field (CRF) based temporal predictor. Two predictors are fed with spatial and temporal features respectively, which are extracted based on real trajectories data recorded in Beijing. Furthermore, we combine both predictors to build the spatio-temporal predictor, by using an optimal combination coefficient which minimizes the normalized mean square error (NMSE) of the predictions. The prediction performance is evaluated based on extensive experiments covering both spatial and temporal predictions, and the improvement achieved by the combined spatio-temporal predictor. The experiment results show that the NMSE of the spatio-temporal predictor is maintained below 0.1 for all investigate regions of Beijing. We further visualize the prediction and discuss the potential benefits can be brought to smart grid scheduling and EV charging by utilizing the proposed framework.
A Comparison of Rule Extraction for Different Recurrent Neural Network Models and Grammatical Complexity
Jan 16, 2018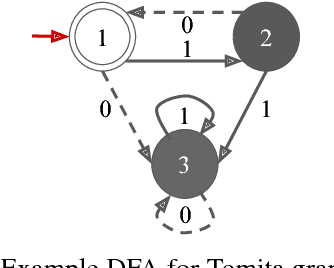
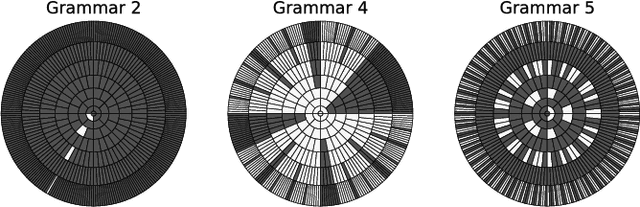
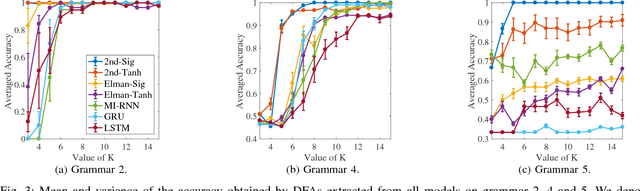
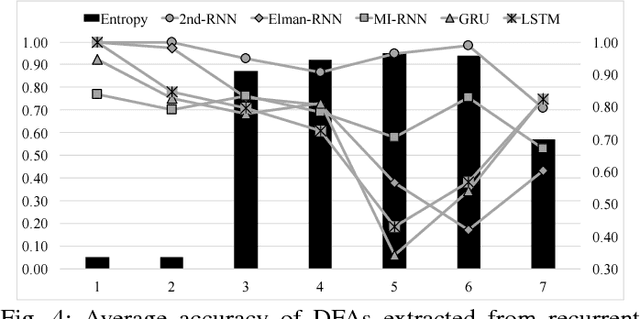
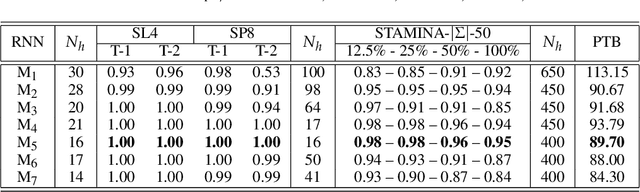
It has been shown that rules can be extracted from highly non-linear, recursive models such as recurrent neural networks (RNNs). The RNN models mostly investigated include both Elman networks and second-order recurrent networks. Recently, new types of RNNs have demonstrated superior power in handling many machine learning tasks, especially when structural data is involved such as language modeling. Here, we empirically evaluate different recurrent models on the task of learning deterministic finite automata (DFA), the seven Tomita grammars. We are interested in the capability of recurrent models with different architectures in learning and expressing regular grammars, which can be the building blocks for many applications dealing with structural data. Our experiments show that a second-order RNN provides the best and stablest performance of extracting DFA over all Tomita grammars and that other RNN models are greatly influenced by different Tomita grammars. To better understand these results, we provide a theoretical analysis of the "complexity" of different grammars, by introducing the entropy and the averaged edit distance of regular grammars defined in this paper. Through our analysis, we categorize all Tomita grammars into different classes, which explains the inconsistency in the performance of extraction observed across all RNN models.