 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Coding Agents via Entropy-Enhanced Multi-Turn Preference Optimization
Sep 15, 2025Software engineering presents complex, multi-step challenges for Large Language Models (LLMs), requiring reasoning over large codebases and coordinated tool use. The difficulty of these tasks is exemplified by benchmarks like SWE-bench, where current LLMs still struggle to resolve real-world issues. A promising approach to enhance performance is test-time scaling (TTS), but its gains are heavily dependent on the diversity of model outputs. While standard alignment methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are effective at aligning model outputs with human preferences, this process can come at the cost of reduced diversity, limiting the effectiveness of TTS. Additionally, existing preference optimization algorithms are typically designed for single-turn tasks and do not fully address the complexities of multi-turn reasoning and tool integration required for interactive coding agents. To bridge this gap, we introduce \sys, an entropy-enhanced framework that adapts existing preference optimization algorithms to the multi-turn, tool-assisted setting. \sys augments the preference objective to explicitly preserve policy entropy and generalizes learning to optimize over multi-turn interactions rather than single-turn responses. We validate \sys by fine-tuning a diverse suite of models from different families and sizes (up to 106B parameters). To maximize performance gains from TTS, we further propose a hybrid best-trajectory selection scheme combining a learned verifier model with model free approaches. On the \swebench leaderboard, our approach establishes new state-of-the-art results among open-weight models. A 30B parameter model trained with \sys ranks 1st on \lite and 4th on \verified on the open-weight leaderboard, surpassed only by models with over 10x more parameters(\eg$>$350B).
A Survey on Explainable Deep Reinforcement Learning
Feb 08, 2025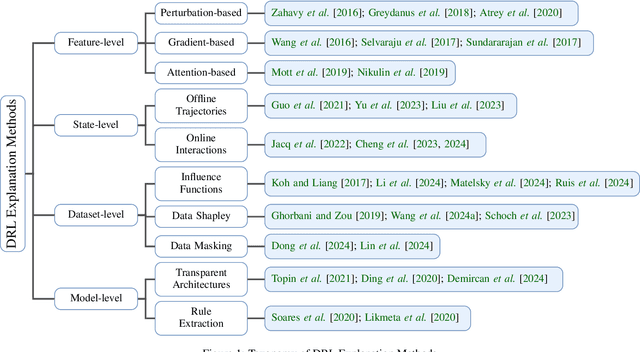

Deep Reinforcement Learning (DRL) has achieved remarkable success in sequential decision-making tasks across diverse domains, yet its reliance on black-box neural architectures hinders interpretability, trust, and deployment in high-stakes applications. Explainable Deep Reinforcement Learning (XRL) addresses these challenges by enhancing transparency through feature-level, state-level, dataset-level, and model-level explanation techniques. This survey provides a comprehensive review of XRL methods, evaluates their qualitative and quantitative assessment frameworks, and explores their role in policy refinement, adversarial robustness, and security. Additionally, we examine the integration of reinforcement learning with Large Language Models (LLMs), particularly through Reinforcement Learning from Human Feedback (RLHF), which optimizes AI alignment with human preferences. We conclude by highlighting open research challenges and future directions to advance the development of interpretable, reliable, and accountable DRL systems.
Soft-Label Integration for Robust Toxicity Classification
Oct 18, 2024



Toxicity classification in textual content remains a significant problem. Data with labels from a single annotator fall short of capturing the diversity of human perspectives. Therefore, there is a growing need to incorporate crowdsourced annotations for training an effective toxicity classifier. Additionally, the standard approach to training a classifier using empirical risk minimization (ERM) may fail to address the potential shifts between the training set and testing set due to exploiting spurious correlations. This work introduces a novel bi-level optimization framework that integrates crowdsourced annotations with the soft-labeling technique and optimizes the soft-label weights by Group Distributionally Robust Optimization (GroupDRO) to enhance the robustness against out-of-distribution (OOD) risk. We theoretically prove the convergence of our bi-level optimization algorithm. Experimental results demonstrate that our approach outperforms existing baseline methods in terms of both average and worst-group accuracy, confirming its effectiveness in leveraging crowdsourced annotations to achieve more effective and robust toxicity classification.
UTF:Undertrained Tokens as Fingerprints A Novel Approach to LLM Identification
Oct 16, 2024



Fingerprinting large language models (LLMs) is essential for verifying model ownership, ensuring authenticity, and preventing misuse. Traditional fingerprinting methods often require significant computational overhead or white-box verification access. In this paper, we introduce UTF, a novel and efficient approach to fingerprinting LLMs by leveraging under-trained tokens. Under-trained tokens are tokens that the model has not fully learned during its training phase. By utilizing these tokens, we perform supervised fine-tuning to embed specific input-output pairs into the model. This process allows the LLM to produce predetermined outputs when presented with certain inputs, effectively embedding a unique fingerprint. Our method has minimal overhead and impact on model's performance, and does not require white-box access to target model's ownership identification. Compared to existing fingerprinting methods, UTF is also more effective and robust to fine-tuning and random guess.
BlockFound: Customized blockchain foundation model for anomaly detection
Oct 14, 2024



We propose BlockFound, a customized foundation model for anomaly blockchain transaction detection. Unlike existing methods that rely on rule-based systems or directly apply off-the-shelf large language models, BlockFound introduces a series of customized designs to model the unique data structure of blockchain transactions. First, a blockchain transaction is multi-modal, containing blockchain-specific tokens, texts, and numbers. We design a modularized tokenizer to handle these multi-modal inputs, balancing the information across different modalities. Second, we design a customized mask language learning mechanism for pretraining with RoPE embedding and FlashAttention for handling longer sequences. After training the foundation model, we further design a novel detection method for anomaly detection. Extensive evaluations on Ethereum and Solana transactions demonstrate BlockFound's exceptional capability in anomaly detection while maintaining a low false positive rate. Remarkably, BlockFound is the only method that successfully detects anomalous transactions on Solana with high accuracy, whereas all other approaches achieved very low or zero detection recall scores. This work not only provides new foundation models for blockchain but also sets a new benchmark for applying LLMs in blockchain data.
Enhancing Jailbreak Attack Against Large Language Models through Silent Tokens
May 31, 2024Along with the remarkable successes of Language language models, recent research also started to explore the security threats of LLMs, including jailbreaking attacks. Attackers carefully craft jailbreaking prompts such that a target LLM will respond to the harmful question. Existing jailbreaking attacks require either human experts or leveraging complicated algorithms to craft jailbreaking prompts. In this paper, we introduce BOOST, a simple attack that leverages only the eos tokens. We demonstrate that rather than constructing complicated jailbreaking prompts, the attacker can simply append a few eos tokens to the end of a harmful question. It will bypass the safety alignment of LLMs and lead to successful jailbreaking attacks. We further apply BOOST to four representative jailbreak methods and show that the attack success rates of these methods can be significantly enhanced by simply adding eos tokens to the prompt. To understand this simple but novel phenomenon, we conduct empirical analyses. Our analysis reveals that adding eos tokens makes the target LLM believe the input is much less harmful, and eos tokens have low attention values and do not affect LLM's understanding of the harmful questions, leading the model to actually respond to the questions. Our findings uncover how fragile an LLM is against jailbreak attacks, motivating the development of strong safety alignment approaches.
RICE: Breaking Through the Training Bottlenecks of Reinforcement Learning with Explanation
May 05, 2024



Deep reinforcement learning (DRL) is playing an increasingly important role in real-world applications. However, obtaining an optimally performing DRL agent for complex tasks, especially with sparse rewards, remains a significant challenge. The training of a DRL agent can be often trapped in a bottleneck without further progress. In this paper, we propose RICE, an innovative refining scheme for reinforcement learning that incorporates explanation methods to break through the training bottlenecks. The high-level idea of RICE is to construct a new initial state distribution that combines both the default initial states and critical states identified through explanation methods, thereby encouraging the agent to explore from the mixed initial states. Through careful design, we can theoretically guarantee that our refining scheme has a tighter sub-optimality bound. We evaluate RICE in various popular RL environments and real-world applications. The results demonstrate that RICE significantly outperforms existing refining schemes in enhancing agent performance.
Assessing Prompt Injection Risks in 200+ Custom GPTs
Nov 20, 2023



In the rapidly evolving landscape of artificial intelligence, ChatGPT has been widely used in various applications. The new feature: customization of ChatGPT models by users to cater to specific needs has opened new frontiers in AI utility. However, this study reveals a significant security vulnerability inherent in these user-customized GPTs: prompt injection attacks. Through comprehensive testing of over 200 user-designed GPT models via adversarial prompts, we demonstrate that these systems are susceptible to prompt injections. Through prompt injection, an adversary can not only extract the customized system prompts but also access the uploaded files. This paper provides a first-hand analysis of the prompt injection, alongside the evaluation of the possible mitigation of such attacks. Our findings underscore the urgent need for robust security frameworks in the design and deployment of customizable GPT models. The intent of this paper is to raise awareness and prompt action in the AI community, ensuring that the benefits of GPT customization do not come at the cost of compromised security and privacy.
GPTFUZZER : Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Sep 19, 2023Large language models (LLMs) have recently experienced tremendous popularity and are widely used from casual conversations to AI-driven programming. However, despite their considerable success, LLMs are not entirely reliable and can give detailed guidance on how to conduct harmful or illegal activities. While safety measures can reduce the risk of such outputs, adversarial "jailbreak" attacks can still exploit LLMs to produce harmful content. These jailbreak templates are typically manually crafted, making large-scale testing challenging. In this paper, we introduce \fuzzer, a novel black-box jailbreak fuzzing framework inspired by AFL fuzzing framework. Instead of manual engineering, \fuzzer automates the generation of jailbreak templates for red-teaming LLMs. At its core, \fuzzer starts with human-written templates as seeds, then mutates them using mutate operators to produce new templates. We detail three key components of \fuzzer: a seed selection strategy for balancing efficiency and variability, metamorphic relations for creating semantically equivalent or similar sentences, and a judgment model to assess the success of a jailbreak attack. We tested \fuzzer on various commercial and open-source LLMs, such as ChatGPT, LLaMa-2, and Claude2, under diverse attack scenarios. Our results indicate that \fuzzer consistently produces jailbreak templates with a high success rate, even in settings where all human-crafted templates fail. Notably, even starting with suboptimal seed templates, \fuzzer maintains over 90\% attack success rate against ChatGPT and Llama-2 models. We believe \fuzzer will aid researchers and practitioners in assessing LLM robustness and will spur further research into LLM safety.
BACKDOORL: Backdoor Attack against Competitive Reinforcement Learning
May 07, 2021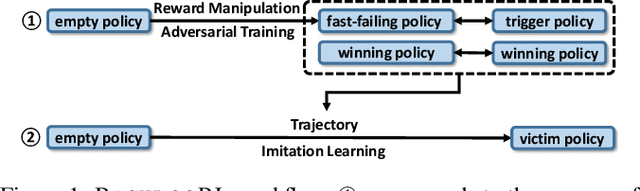



Recent research has confirmed the feasibility of backdoor attacks in deep reinforcement learning (RL) systems. However, the existing attacks require the ability to arbitrarily modify an agent's observation, constraining the application scope to simple RL systems such as Atari games. In this paper, we migrate backdoor attacks to more complex RL systems involving multiple agents and explore the possibility of triggering the backdoor without directly manipulating the agent's observation. As a proof of concept, we demonstrate that an adversary agent can trigger the backdoor of the victim agent with its own action in two-player competitive RL systems. We prototype and evaluate BACKDOORL in four competitive environments. The results show that when the backdoor is activated, the winning rate of the victim drops by 17% to 37% compared to when not activated.