 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022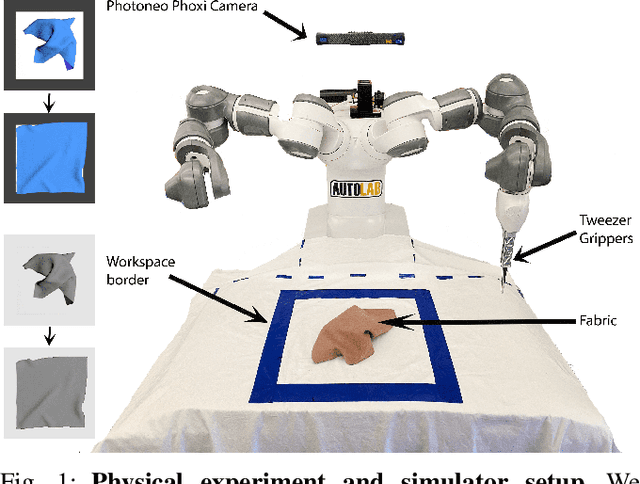
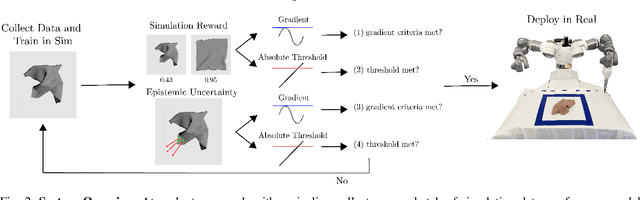

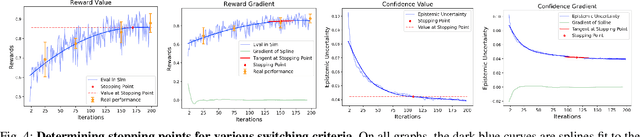
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.
Policy Gradient Bayesian Robust Optimization for Imitation Learning
Jun 21, 2021
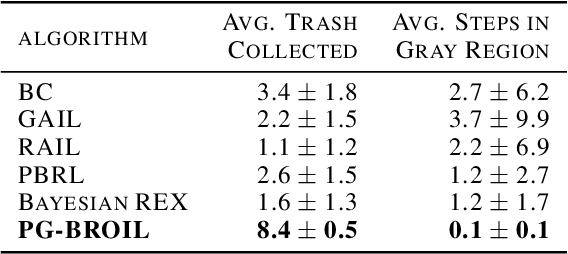
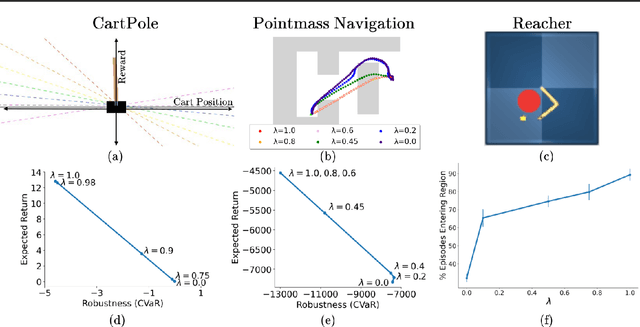
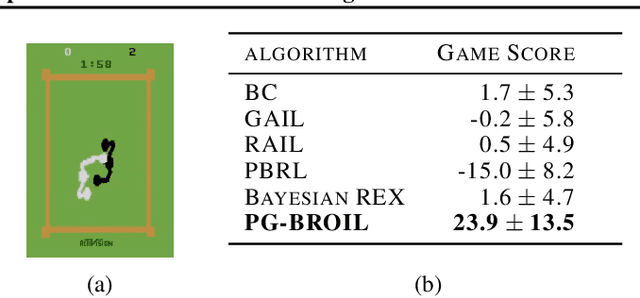
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.
BACKDOORL: Backdoor Attack against Competitive Reinforcement Learning
May 07, 2021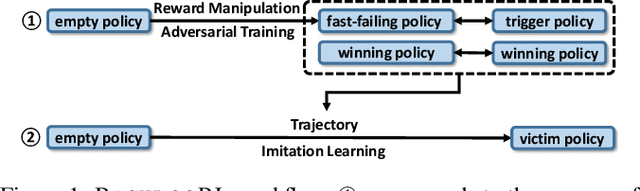



Recent research has confirmed the feasibility of backdoor attacks in deep reinforcement learning (RL) systems. However, the existing attacks require the ability to arbitrarily modify an agent's observation, constraining the application scope to simple RL systems such as Atari games. In this paper, we migrate backdoor attacks to more complex RL systems involving multiple agents and explore the possibility of triggering the backdoor without directly manipulating the agent's observation. As a proof of concept, we demonstrate that an adversary agent can trigger the backdoor of the victim agent with its own action in two-player competitive RL systems. We prototype and evaluate BACKDOORL in four competitive environments. The results show that when the backdoor is activated, the winning rate of the victim drops by 17% to 37% compared to when not activated.