 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Delusional Hedge Algorithm as a Model of Human Learning from Diverse Opinions
Feb 21, 2024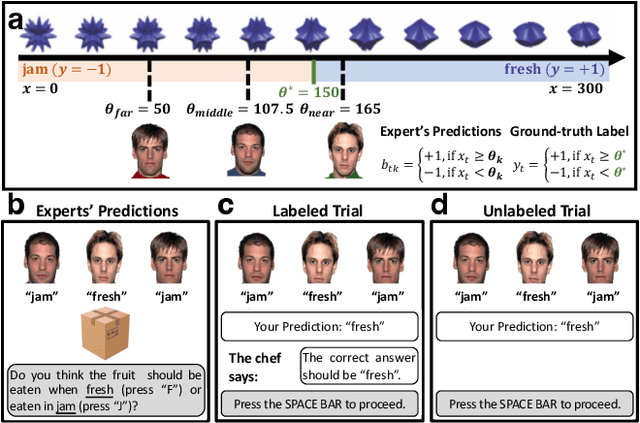
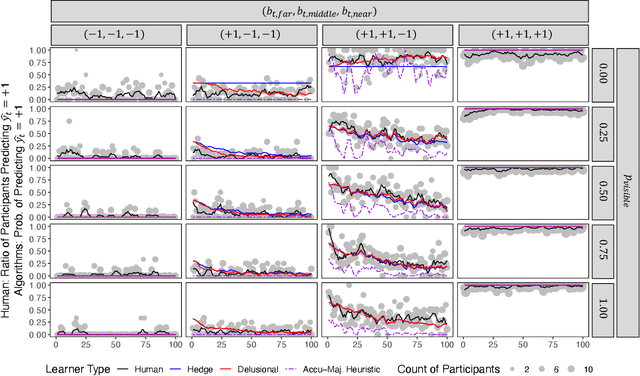

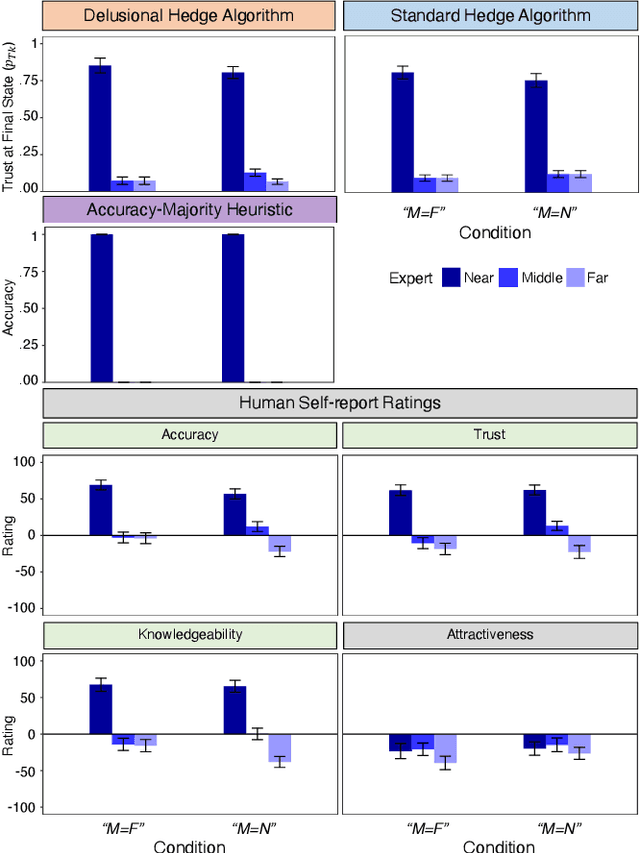
Whereas cognitive models of learning often assume direct experience with both the features of an event and with a true label or outcome, much of everyday learning arises from hearing the opinions of others, without direct access to either the experience or the ground truth outcome. We consider how people can learn which opinions to trust in such scenarios by extending the hedge algorithm: a classic solution for learning from diverse information sources. We first introduce a semi-supervised variant we call the delusional hedge capable of learning from both supervised and unsupervised experiences. In two experiments, we examine the alignment between human judgments and predictions from the standard hedge, the delusional hedge, and a heuristic baseline model. Results indicate that humans effectively incorporate both labeled and unlabeled information in a manner consistent with the delusional hedge algorithm -- suggesting that human learners not only gauge the accuracy of information sources but also their consistency with other reliable sources. The findings advance our understanding of human learning from diverse opinions, with implications for the development of algorithms that better capture how people learn to weigh conflicting information sources.
Policy Gradient Bayesian Robust Optimization for Imitation Learning
Jun 21, 2021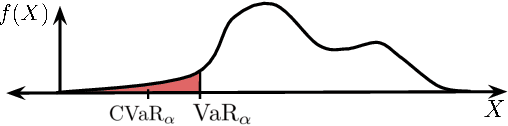
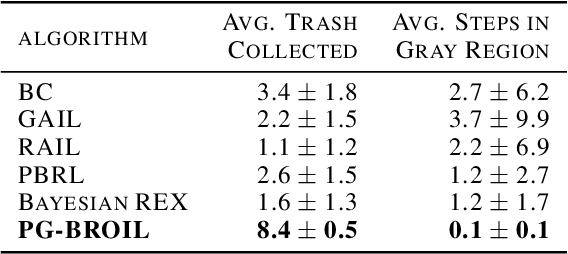
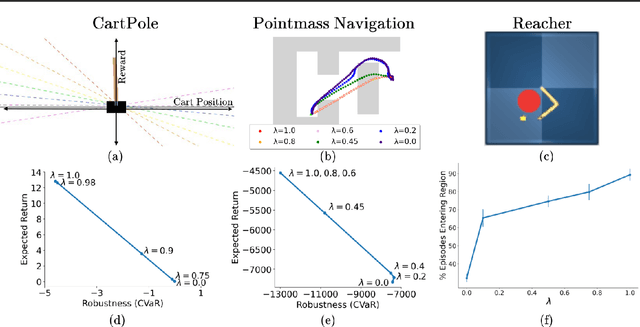
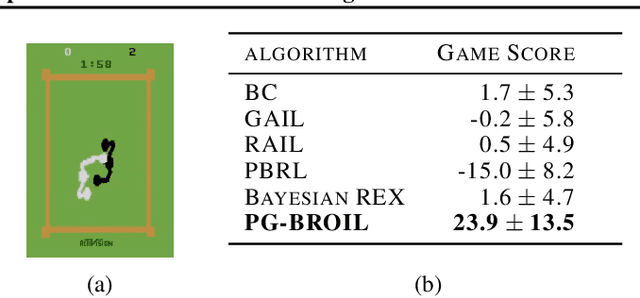
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.
Corruption-Robust Offline Reinforcement Learning
Jun 11, 2021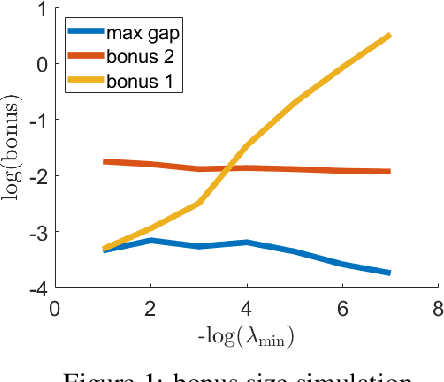
We study the adversarial robustness in offline reinforcement learning. Given a batch dataset consisting of tuples $(s, a, r, s')$, an adversary is allowed to arbitrarily modify $\epsilon$ fraction of the tuples. From the corrupted dataset the learner aims to robustly identify a near-optimal policy. We first show that a worst-case $\Omega(d\epsilon)$ optimality gap is unavoidable in linear MDP of dimension $d$, even if the adversary only corrupts the reward element in a tuple. This contrasts with dimension-free results in robust supervised learning and best-known lower-bound in the online RL setting with corruption. Next, we propose robust variants of the Least-Square Value Iteration (LSVI) algorithm utilizing robust supervised learning oracles, which achieve near-matching performances in cases both with and without full data coverage. The algorithm requires the knowledge of $\epsilon$ to design the pessimism bonus in the no-coverage case. Surprisingly, in this case, the knowledge of $\epsilon$ is necessary, as we show that being adaptive to unknown $\epsilon$ is impossible.This again contrasts with recent results on corruption-robust online RL and implies that robust offline RL is a strictly harder problem.