 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColumn2Vec: Structural Understanding via Distributed Representations of Database Schemas
Mar 20, 2019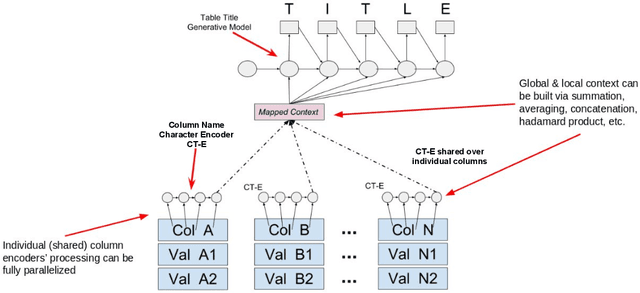
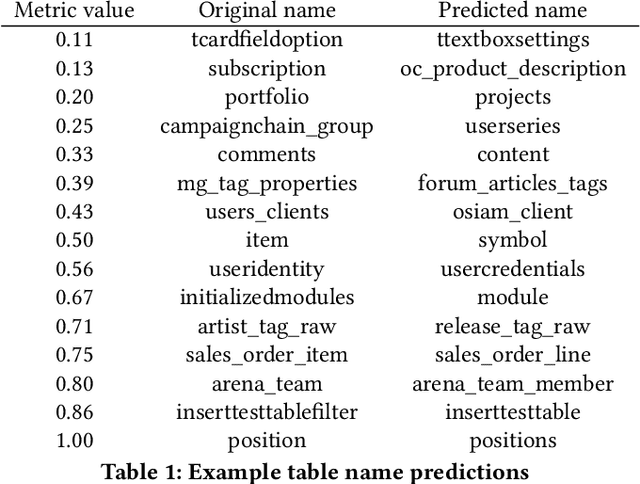
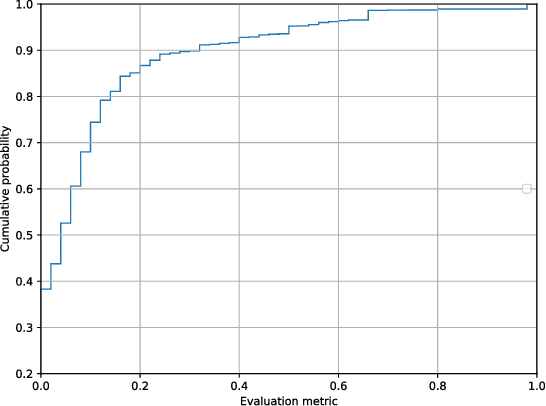
We present Column2Vec, a distributed representation of database columns based on column metadata. Our distributed representation has several applications. Using known names for groups of columns (i.e., a table name), we train a model to generate an appropriate name for columns in an unnamed table. We demonstrate the viability of our approach using schema information collected from open source applications on GitHub.
Learning a Hierarchical Latent-Variable Model of 3D Shapes
Aug 04, 2018

We propose the Variational Shape Learner (VSL), a generative model that learns the underlying structure of voxelized 3D shapes in an unsupervised fashion. Through the use of skip-connections, our model can successfully learn and infer a latent, hierarchical representation of objects. Furthermore, realistic 3D objects can be easily generated by sampling the VSL's latent probabilistic manifold. We show that our generative model can be trained end-to-end from 2D images to perform single image 3D model retrieval. Experiments show, both quantitatively and qualitatively, the improved generalization of our proposed model over a range of tasks, performing better or comparable to various state-of-the-art alternatives.
Using Neural Generative Models to Release Synthetic Twitter Corpora with Reduced Stylometric Identifiability of Users
May 30, 2018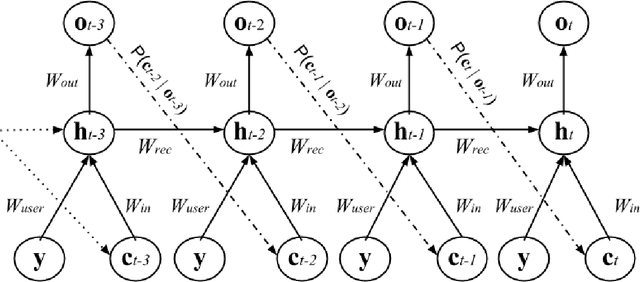
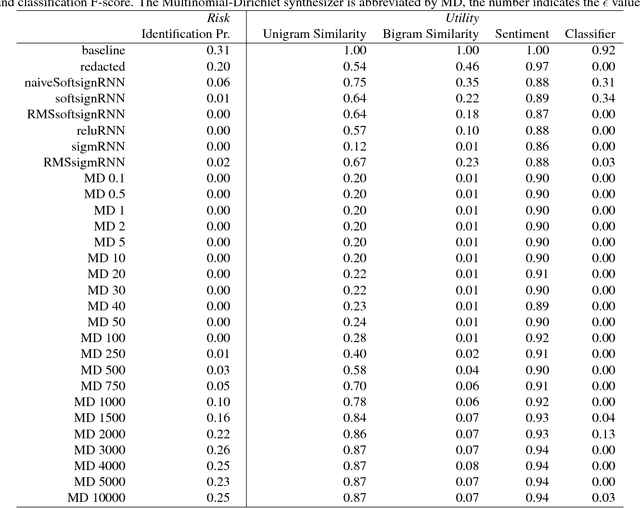
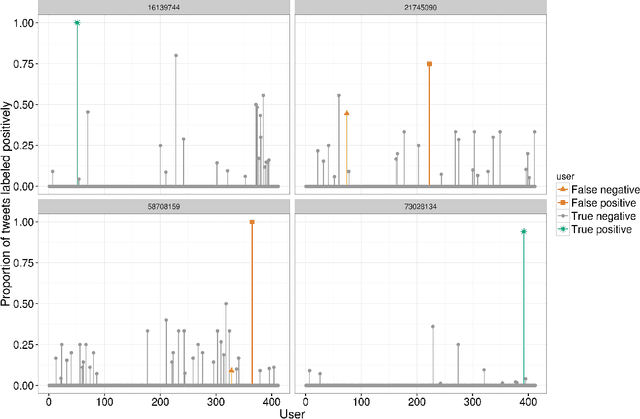
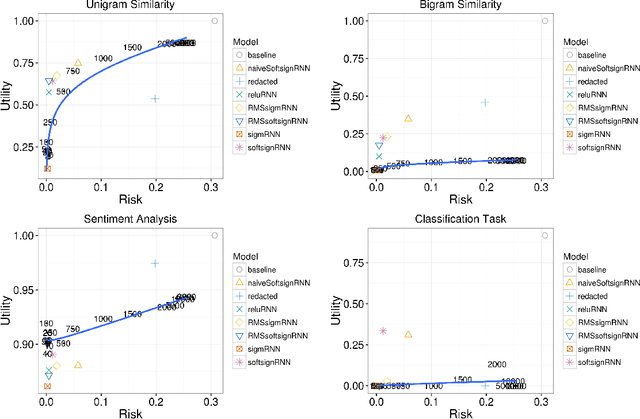
We present a method for generating synthetic versions of Twitter data using neural generative models. The goal is protecting individuals in the source data from stylometric re-identification attacks while still releasing data that carries research value. Specifically, we generate tweet corpora that maintain user-level word distributions by augmenting the neural language models with user-specific components. We compare our approach to two standard text data protection methods: redaction and iterative translation. We evaluate the three methods on measures of risk and utility. We define risk following the stylometric models of re-identification, and we define utility based on two general word distribution measures and two common text analysis research tasks. We find that neural models are able to significantly lower risk over previous methods with little cost to utility. We also demonstrate that the neural models allow data providers to actively control the risk-utility trade-off through model tuning parameters. This work presents promising results for a new tool addressing the problem of privacy for free text and sharing social media data in a way that respects privacy and is ethically responsible.
A Comparison of Rule Extraction for Different Recurrent Neural Network Models and Grammatical Complexity
Jan 16, 2018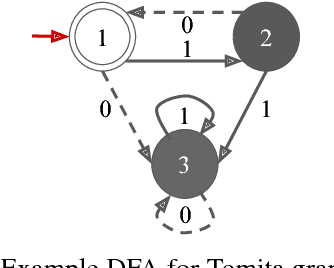
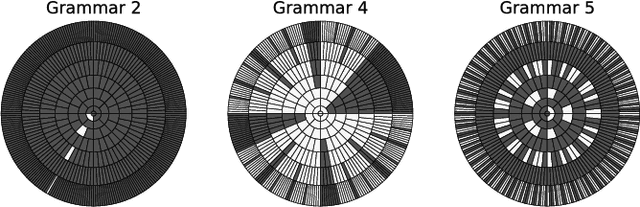
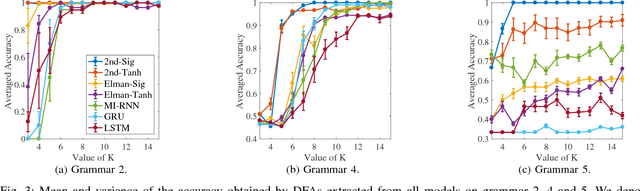
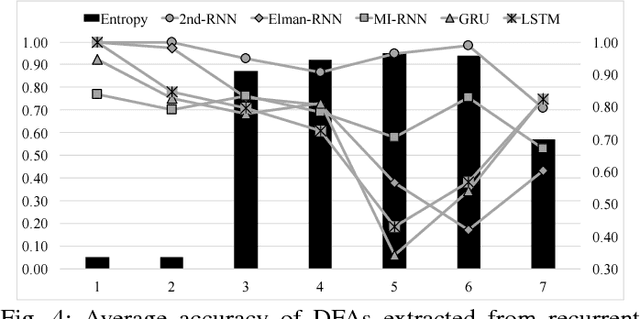
It has been shown that rules can be extracted from highly non-linear, recursive models such as recurrent neural networks (RNNs). The RNN models mostly investigated include both Elman networks and second-order recurrent networks. Recently, new types of RNNs have demonstrated superior power in handling many machine learning tasks, especially when structural data is involved such as language modeling. Here, we empirically evaluate different recurrent models on the task of learning deterministic finite automata (DFA), the seven Tomita grammars. We are interested in the capability of recurrent models with different architectures in learning and expressing regular grammars, which can be the building blocks for many applications dealing with structural data. Our experiments show that a second-order RNN provides the best and stablest performance of extracting DFA over all Tomita grammars and that other RNN models are greatly influenced by different Tomita grammars. To better understand these results, we provide a theoretical analysis of the "complexity" of different grammars, by introducing the entropy and the averaged edit distance of regular grammars defined in this paper. Through our analysis, we categorize all Tomita grammars into different classes, which explains the inconsistency in the performance of extraction observed across all RNN models.
Learning to Adapt by Minimizing Discrepancy
Nov 30, 2017

We explore whether useful temporal neural generative models can be learned from sequential data without back-propagation through time. We investigate the viability of a more neurocognitively-grounded approach in the context of unsupervised generative modeling of sequences. Specifically, we build on the concept of predictive coding, which has gained influence in cognitive science, in a neural framework. To do so we develop a novel architecture, the Temporal Neural Coding Network, and its learning algorithm, Discrepancy Reduction. The underlying directed generative model is fully recurrent, meaning that it employs structural feedback connections and temporal feedback connections, yielding information propagation cycles that create local learning signals. This facilitates a unified bottom-up and top-down approach for information transfer inside the architecture. Our proposed algorithm shows promise on the bouncing balls generative modeling problem. Further experiments could be conducted to explore the strengths and weaknesses of our approach.
An Empirical Evaluation of Rule Extraction from Recurrent Neural Networks
Nov 28, 2017Rule extraction from black-box models is critical in domains that require model validation before implementation, as can be the case in credit scoring and medical diagnosis. Though already a challenging problem in statistical learning in general, the difficulty is even greater when highly non-linear, recursive models, such as recurrent neural networks (RNNs), are fit to data. Here, we study the extraction of rules from second order recurrent neural networks trained to recognize the Tomita grammars. We show that production rules can be stably extracted from trained RNNs and that in certain cases the rules outperform the trained RNNs.
Piecewise Latent Variables for Neural Variational Text Processing
Sep 23, 2017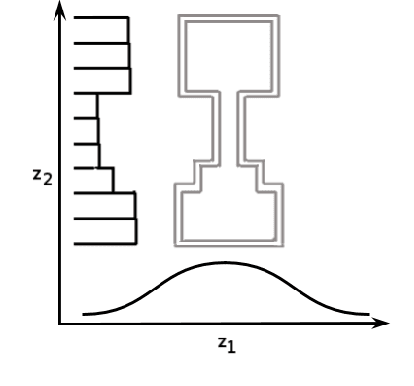


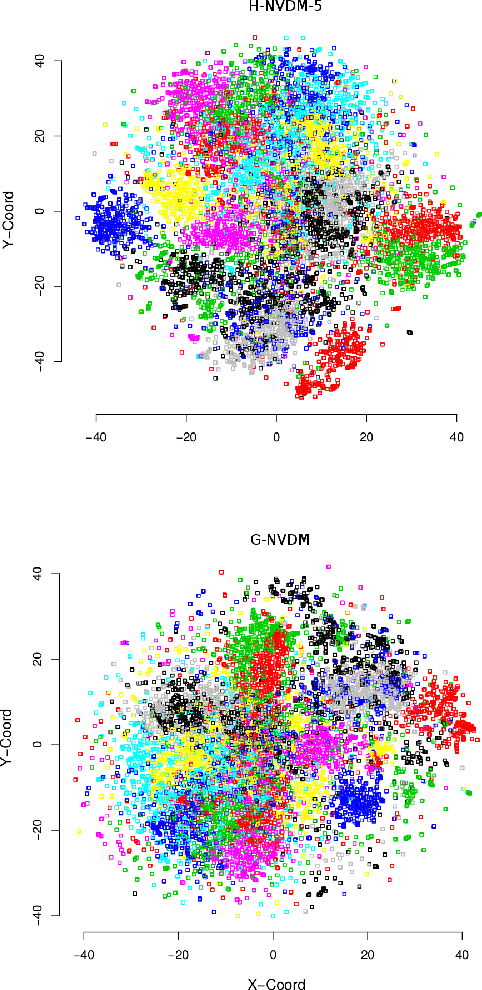
Advances in neural variational inference have facilitated the learning of powerful directed graphical models with continuous latent variables, such as variational autoencoders. The hope is that such models will learn to represent rich, multi-modal latent factors in real-world data, such as natural language text. However, current models often assume simplistic priors on the latent variables - such as the uni-modal Gaussian distribution - which are incapable of representing complex latent factors efficiently. To overcome this restriction, we propose the simple, but highly flexible, piecewise constant distribution. This distribution has the capacity to represent an exponential number of modes of a latent target distribution, while remaining mathematically tractable. Our results demonstrate that incorporating this new latent distribution into different models yields substantial improvements in natural language processing tasks such as document modeling and natural language generation for dialogue.
Learning Adversary-Resistant Deep Neural Networks
Aug 19, 2017
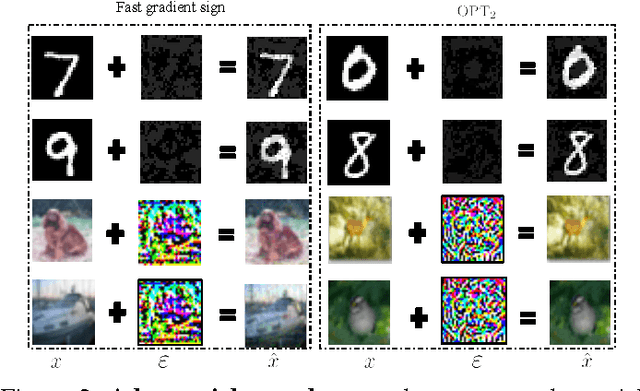
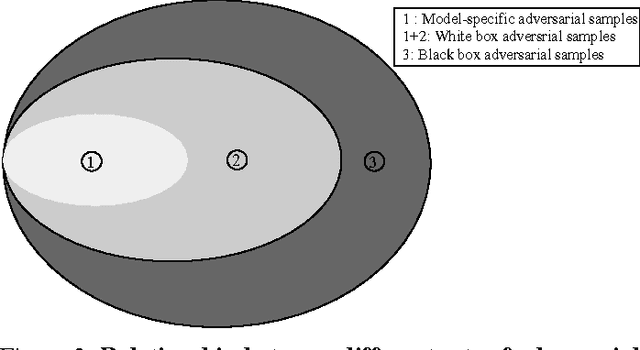
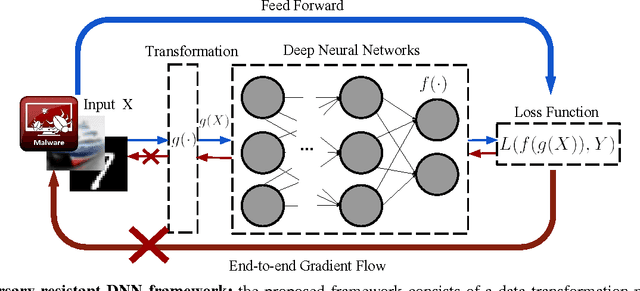
Deep neural networks (DNNs) have proven to be quite effective in a vast array of machine learning tasks, with recent examples in cyber security and autonomous vehicles. Despite the superior performance of DNNs in these applications, it has been recently shown that these models are susceptible to a particular type of attack that exploits a fundamental flaw in their design. This attack consists of generating particular synthetic examples referred to as adversarial samples. These samples are constructed by slightly manipulating real data-points in order to "fool" the original DNN model, forcing it to mis-classify previously correctly classified samples with high confidence. Addressing this flaw in the model is essential if DNNs are to be used in critical applications such as those in cyber security. Previous work has provided various learning algorithms to enhance the robustness of DNN models, and they all fall into the tactic of "security through obscurity". This means security can be guaranteed only if one can obscure the learning algorithms from adversaries. Once the learning technique is disclosed, DNNs protected by these defense mechanisms are still susceptible to adversarial samples. In this work, we investigate this issue shared across previous research work and propose a generic approach to escalate a DNN's resistance to adversarial samples. More specifically, our approach integrates a data transformation module with a DNN, making it robust even if we reveal the underlying learning algorithm. To demonstrate the generality of our proposed approach and its potential for handling cyber security applications, we evaluate our method and several other existing solutions on datasets publicly available. Our results indicate that our approach typically provides superior classification performance and resistance in comparison with state-of-art solutions.
Learning Simpler Language Models with the Differential State Framework
Jul 16, 2017Learning useful information across long time lags is a critical and difficult problem for temporal neural models in tasks such as language modeling. Existing architectures that address the issue are often complex and costly to train. The Differential State Framework (DSF) is a simple and high-performing design that unifies previously introduced gated neural models. DSF models maintain longer-term memory by learning to interpolate between a fast-changing data-driven representation and a slowly changing, implicitly stable state. This requires hardly any more parameters than a classical, simple recurrent network. Within the DSF framework, a new architecture is presented, the Delta-RNN. In language modeling at the word and character levels, the Delta-RNN outperforms popular complex architectures, such as the Long Short Term Memory (LSTM) and the Gated Recurrent Unit (GRU), and, when regularized, performs comparably to several state-of-the-art baselines. At the subword level, the Delta-RNN's performance is comparable to that of complex gated architectures.
Adversary Resistant Deep Neural Networks with an Application to Malware Detection
Apr 27, 2017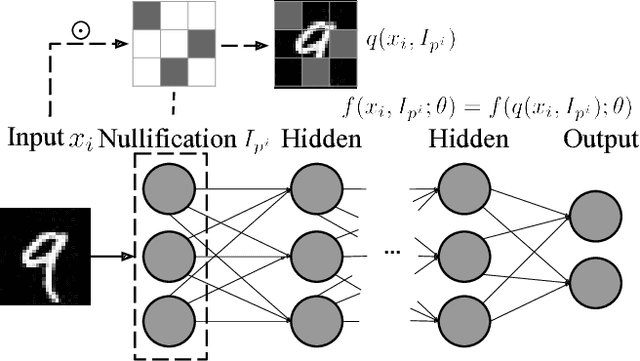

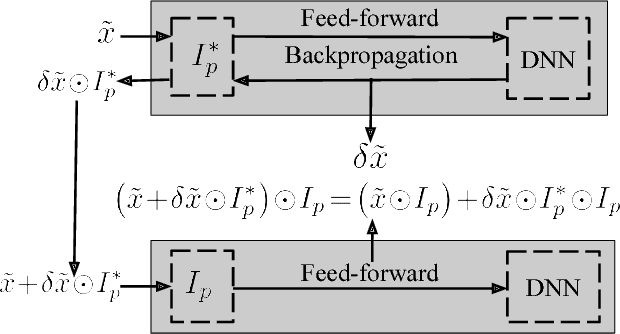
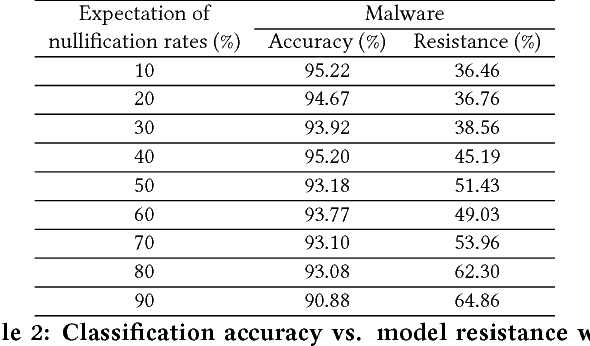
Beyond its highly publicized victories in Go, there have been numerous successful applications of deep learning in information retrieval, computer vision and speech recognition. In cybersecurity, an increasing number of companies have become excited about the potential of deep learning, and have started to use it for various security incidents, the most popular being malware detection. These companies assert that deep learning (DL) could help turn the tide in the battle against malware infections. However, deep neural networks (DNNs) are vulnerable to adversarial samples, a flaw that plagues most if not all statistical learning models. Recent research has demonstrated that those with malicious intent can easily circumvent deep learning-powered malware detection by exploiting this flaw. In order to address this problem, previous work has developed various defense mechanisms that either augmenting training data or enhance model's complexity. However, after a thorough analysis of the fundamental flaw in DNNs, we discover that the effectiveness of current defenses is limited and, more importantly, cannot provide theoretical guarantees as to their robustness against adversarial sampled-based attacks. As such, we propose a new adversary resistant technique that obstructs attackers from constructing impactful adversarial samples by randomly nullifying features within samples. In this work, we evaluate our proposed technique against a real world dataset with 14,679 malware variants and 17,399 benign programs. We theoretically validate the robustness of our technique, and empirically show that our technique significantly boosts DNN robustness to adversarial samples while maintaining high accuracy in classification. To demonstrate the general applicability of our proposed method, we also conduct experiments using the MNIST and CIFAR-10 datasets, generally used in image recognition research.