 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Neural Generative Models to Release Synthetic Twitter Corpora with Reduced Stylometric Identifiability of Users
Paper and Code
May 30, 2018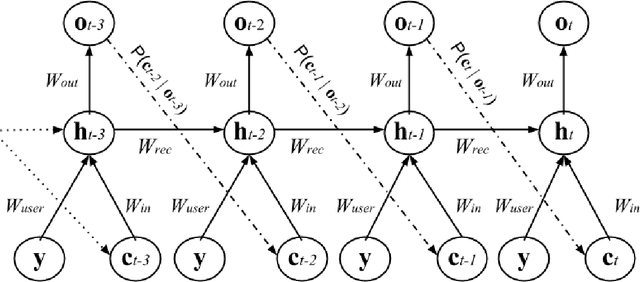
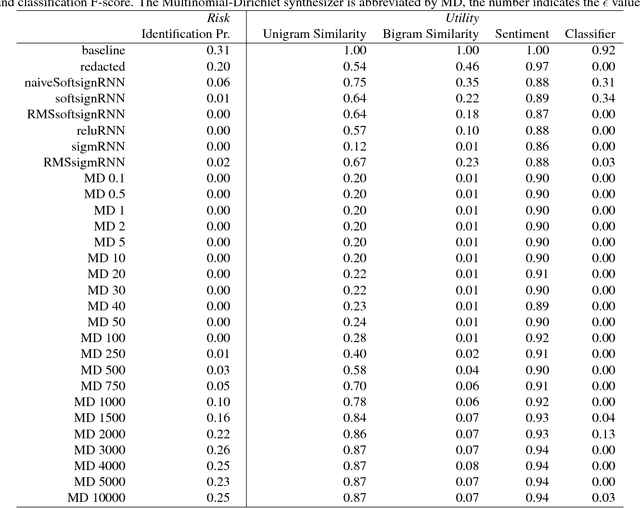
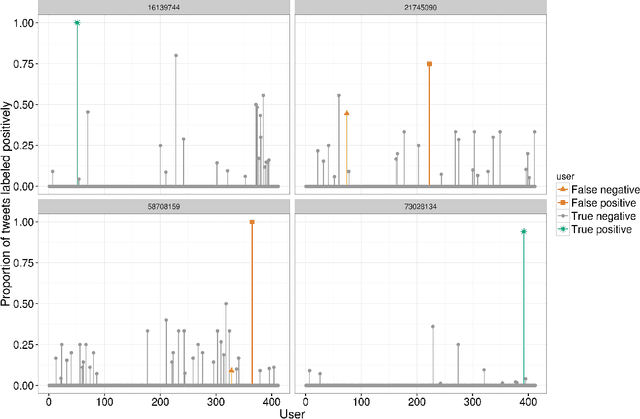
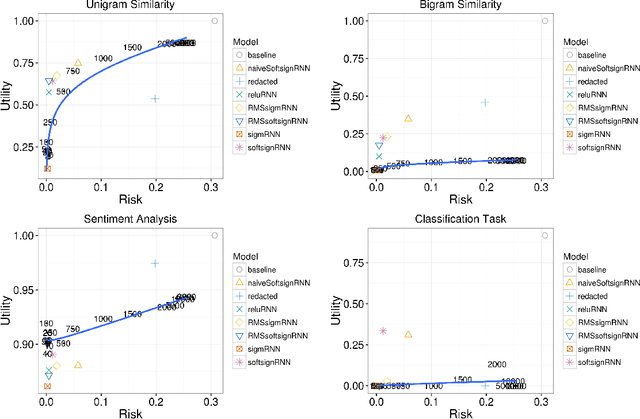
We present a method for generating synthetic versions of Twitter data using neural generative models. The goal is protecting individuals in the source data from stylometric re-identification attacks while still releasing data that carries research value. Specifically, we generate tweet corpora that maintain user-level word distributions by augmenting the neural language models with user-specific components. We compare our approach to two standard text data protection methods: redaction and iterative translation. We evaluate the three methods on measures of risk and utility. We define risk following the stylometric models of re-identification, and we define utility based on two general word distribution measures and two common text analysis research tasks. We find that neural models are able to significantly lower risk over previous methods with little cost to utility. We also demonstrate that the neural models allow data providers to actively control the risk-utility trade-off through model tuning parameters. This work presents promising results for a new tool addressing the problem of privacy for free text and sharing social media data in a way that respects privacy and is ethically responsible.