 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-VAE: Learning Motion Transformations to Generate Multimodal Human Dynamics
Aug 14, 2018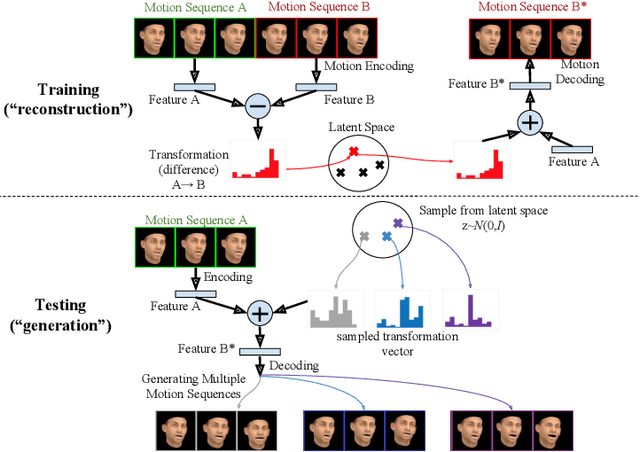
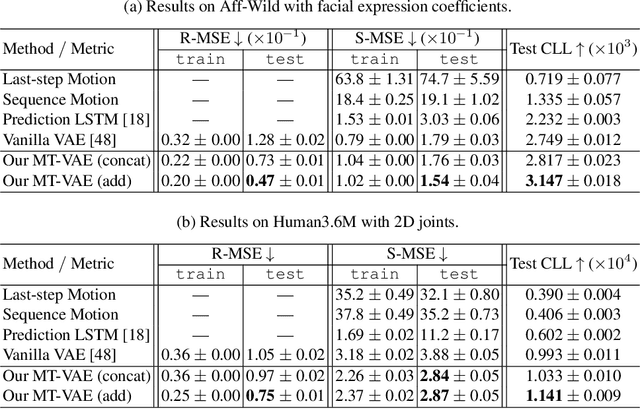
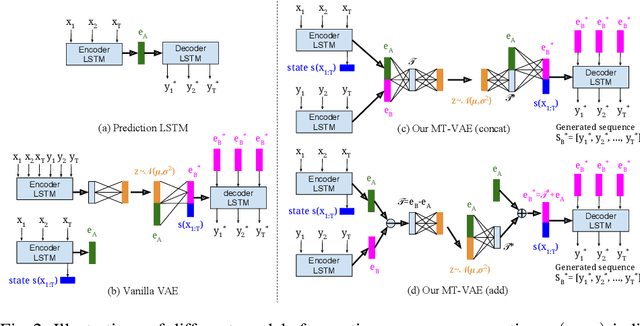

Long-term human motion can be represented as a series of motion modes---motion sequences that capture short-term temporal dynamics---with transitions between them. We leverage this structure and present a novel Motion Transformation Variational Auto-Encoders (MT-VAE) for learning motion sequence generation. Our model jointly learns a feature embedding for motion modes (that the motion sequence can be reconstructed from) and a feature transformation that represents the transition of one motion mode to the next motion mode. Our model is able to generate multiple diverse and plausible motion sequences in the future from the same input. We apply our approach to both facial and full body motion, and demonstrate applications like analogy-based motion transfer and video synthesis.
Domain2Vec: Deep Domain Generalization
Jul 09, 2018

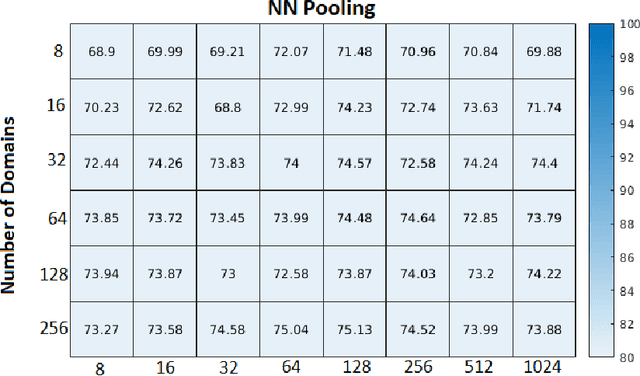
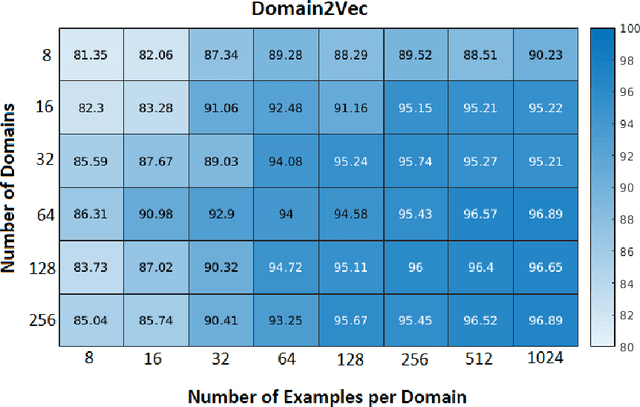
We address the problem of domain generalization where a decision function is learned from the data of several related domains, and the goal is to apply it on an unseen domain successfully. It is assumed that there is plenty of labeled data available in source domains (also called as training domain), but no labeled data is available for the unseen domain (also called a target domain or test domain). We propose a novel neural network architecture, Domain2Vec (D2V) that learns domain-specific embedding and then uses this embedding to generalize the learning across related domains. The proposed algorithm, D2V extends the idea of distribution regression and kernelized domain generalization to the neural networks setting. We propose a neural network architecture to learn domain-specific embedding and then use this embedding along with the data point specific features to label it. We show the effectiveness of the architecture by accurately estimating domain to domain similarity. We evaluate our algorithm against standard domain generalization datasets for image classification and outperform other state of the art algorithms.