 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDFNet: Unsupervised Disparity Fusion with Adversarial Networks
Paper and Code

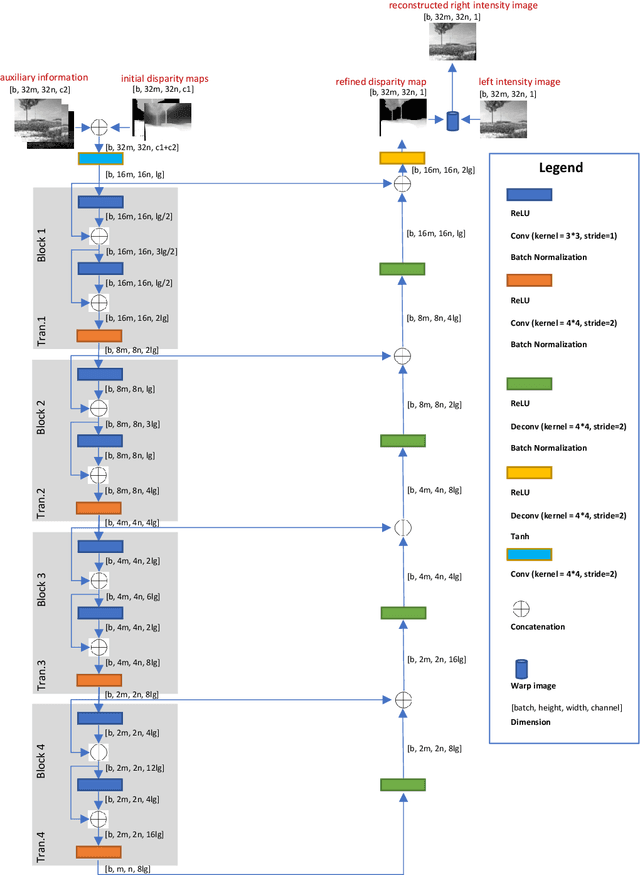
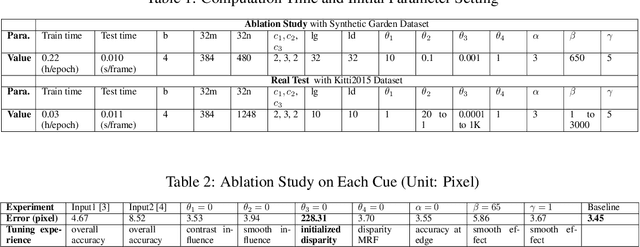

Existing disparity fusion methods based on deep learning achieve state-of-the-art performance, but they require ground truth disparity data to train. As far as I know, this is the first time an unsupervised disparity fusion not using ground truth disparity data has been proposed. In this paper, a mathematical model for disparity fusion is proposed to guide an adversarial network to train effectively without ground truth disparity data. The initial disparity maps are inputted from the left view along with auxiliary information (gradient, left & right intensity image) into the refiner and the refiner is trained to output the refined disparity map registered on the left view. The refined left disparity map and left intensity image are used to reconstruct a fake right intensity image. Finally, the fake and real right intensity images (from the right stereo vision camera) are fed into the discriminator. In the model, the refiner is trained to output a refined disparity value close to the weighted sum of the disparity inputs for global initialisation. Then, three refinement principles are adopted to refine the results further. (1) The reconstructed intensity error between the fake and real right intensity image is minimised. (2) The similarities between the fake and real right image in different receptive fields are maximised. (3) The refined disparity map is smoothed based on the corresponding intensity image. The adversarial networks' architectures are effective for the fusion task. The fusion time using the proposed network is small. The network can achieve 90 fps using Nvidia Geforce GTX 1080Ti on the Kitti2015 dataset when the input resolution is 1242 * 375 (Width * Height) without downsampling and cropping. The accuracy of this work is equal to (or better than) the state-of-the-art supervised methods.