 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoteChat: A Dataset of Synthetic Doctor-Patient Conversations Conditioned on Clinical Notes
Oct 24, 2023



The detailed clinical records drafted by doctors after each patient's visit are crucial for medical practitioners and researchers. Automating the creation of these notes with language models can reduce the workload of doctors. However, training such models can be difficult due to the limited public availability of conversations between patients and doctors. In this paper, we introduce NoteChat, a cooperative multi-agent framework leveraging Large Language Models (LLMs) for generating synthetic doctor-patient conversations conditioned on clinical notes. NoteChat consists of Planning, Roleplay, and Polish modules. We provide a comprehensive automatic and human evaluation of NoteChat, comparing it with state-of-the-art models, including OpenAI's ChatGPT and GPT-4. Results demonstrate that NoteChat facilitates high-quality synthetic doctor-patient conversations, underscoring the untapped potential of LLMs in healthcare. This work represents the first instance of multiple LLMs cooperating to complete a doctor-patient conversation conditioned on clinical notes, offering promising avenues for the intersection of AI and healthcare
Early Prediction of Alzheimers Disease Leveraging Symptom Occurrences from Longitudinal Electronic Health Records of US Military Veterans
Jul 23, 2023



Early prediction of Alzheimer's disease (AD) is crucial for timely intervention and treatment. This study aims to use machine learning approaches to analyze longitudinal electronic health records (EHRs) of patients with AD and identify signs and symptoms that can predict AD onset earlier. We used a case-control design with longitudinal EHRs from the U.S. Department of Veterans Affairs Veterans Health Administration (VHA) from 2004 to 2021. Cases were VHA patients with AD diagnosed after 1/1/2016 based on ICD-10-CM codes, matched 1:9 with controls by age, sex and clinical utilization with replacement. We used a panel of AD-related keywords and their occurrences over time in a patient's longitudinal EHRs as predictors for AD prediction with four machine learning models. We performed subgroup analyses by age, sex, and race/ethnicity, and validated the model in a hold-out and "unseen" VHA stations group. Model discrimination, calibration, and other relevant metrics were reported for predictions up to ten years before ICD-based diagnosis. The study population included 16,701 cases and 39,097 matched controls. The average number of AD-related keywords (e.g., "concentration", "speaking") per year increased rapidly for cases as diagnosis approached, from around 10 to over 40, while remaining flat at 10 for controls. The best model achieved high discriminative accuracy (ROCAUC 0.997) for predictions using data from at least ten years before ICD-based diagnoses. The model was well-calibrated (Hosmer-Lemeshow goodness-of-fit p-value = 0.99) and consistent across subgroups of age, sex and race/ethnicity, except for patients younger than 65 (ROCAUC 0.746). Machine learning models using AD-related keywords identified from EHR notes can predict future AD diagnoses, suggesting its potential use for identifying AD risk using EHR notes, offering an affordable way for early screening on large population.
MetaMT,a MetaLearning Method Leveraging Multiple Domain Data for Low Resource Machine Translation
Dec 11, 2019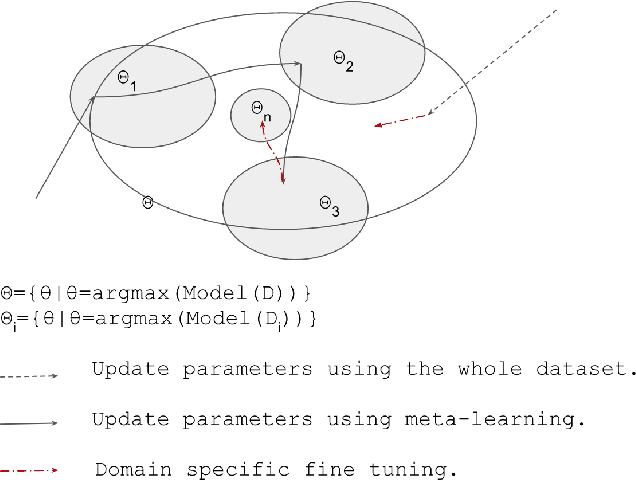

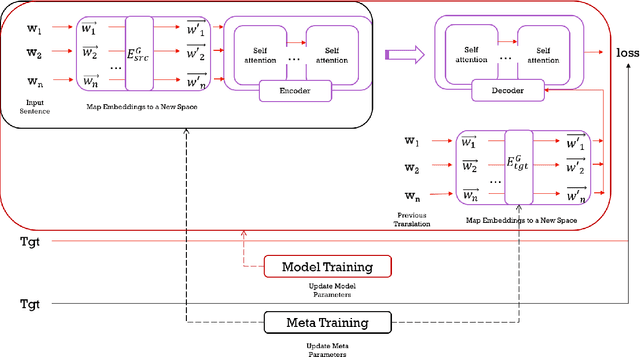

Manipulating training data leads to robust neural models for MT.
Time-dependent Hierarchical Dirichlet Model for Timeline Generation
Mar 14, 2017
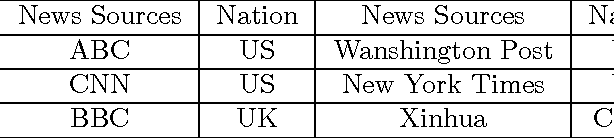
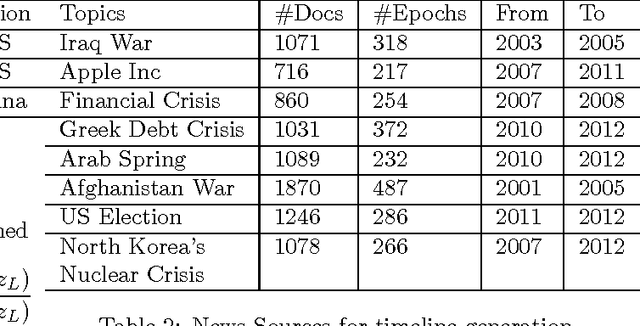
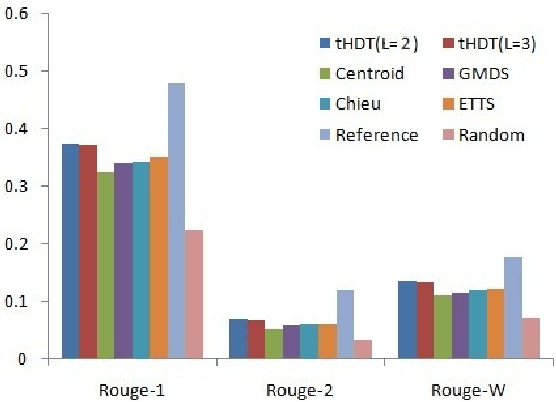
Timeline Generation aims at summarizing news from different epochs and telling readers how an event evolves. It is a new challenge that combines salience ranking with novelty detection. For long-term public events, the main topic usually includes various aspects across different epochs and each aspect has its own evolving pattern. Existing approaches neglect such hierarchical topic structure involved in the news corpus in timeline generation. In this paper, we develop a novel time-dependent Hierarchical Dirichlet Model (HDM) for timeline generation. Our model can aptly detect different levels of topic information across corpus and such structure is further used for sentence selection. Based on the topic mined fro HDM, sentences are selected by considering different aspects such as relevance, coherence and coverage. We develop experimental systems to evaluate 8 long-term events that public concern. Performance comparison between different systems demonstrates the effectiveness of our model in terms of ROUGE metrics.