 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Feature Distillation with Object-Centric Priors
Jun 26, 2024



Grounding natural language to the physical world is a ubiquitous topic with a wide range of applications in computer vision and robotics. Recently, 2D vision-language models such as CLIP have been widely popularized, due to their impressive capabilities for open-vocabulary grounding in 2D images. Recent works aim to elevate 2D CLIP features to 3D via feature distillation, but either learn neural fields that are scene-specific and hence lack generalization, or focus on indoor room scan data that require access to multiple camera views, which is not practical in robot manipulation scenarios. Additionally, related methods typically fuse features at pixel-level and assume that all camera views are equally informative. In this work, we show that this approach leads to sub-optimal 3D features, both in terms of grounding accuracy, as well as segmentation crispness. To alleviate this, we propose a multi-view feature fusion strategy that employs object-centric priors to eliminate uninformative views based on semantic information, and fuse features at object-level via instance segmentation masks. To distill our object-centric 3D features, we generate a large-scale synthetic multi-view dataset of cluttered tabletop scenes, spawning 15k scenes from over 3300 unique object instances, which we make publicly available. We show that our method reconstructs 3D CLIP features with improved grounding capacity and spatial consistency, while doing so from single-view RGB-D, thus departing from the assumption of multiple camera views at test time. Finally, we show that our approach can generalize to novel tabletop domains and be re-purposed for 3D instance segmentation without fine-tuning, and demonstrate its utility for language-guided robotic grasping in clutter
Lifelong Robot Library Learning: Bootstrapping Composable and Generalizable Skills for Embodied Control with Language Models
Jun 26, 2024



Large Language Models (LLMs) have emerged as a new paradigm for embodied reasoning and control, most recently by generating robot policy code that utilizes a custom library of vision and control primitive skills. However, prior arts fix their skills library and steer the LLM with carefully hand-crafted prompt engineering, limiting the agent to a stationary range of addressable tasks. In this work, we introduce LRLL, an LLM-based lifelong learning agent that continuously grows the robot skill library to tackle manipulation tasks of ever-growing complexity. LRLL achieves this with four novel contributions: 1) a soft memory module that allows dynamic storage and retrieval of past experiences to serve as context, 2) a self-guided exploration policy that proposes new tasks in simulation, 3) a skill abstractor that distills recent experiences into new library skills, and 4) a lifelong learning algorithm for enabling human users to bootstrap new skills with minimal online interaction. LRLL continuously transfers knowledge from the memory to the library, building composable, general and interpretable policies, while bypassing gradient-based optimization, thus relieving the learner from catastrophic forgetting. Empirical evaluation in a simulated tabletop environment shows that LRLL outperforms end-to-end and vanilla LLM approaches in the lifelong setup while learning skills that are transferable to the real world. Project material will become available at the webpage https://gtziafas.github.io/LRLL_project.
Towards Open-World Grasping with Large Vision-Language Models
Jun 26, 2024



The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Language-guided Robot Grasping: CLIP-based Referring Grasp Synthesis in Clutter
Nov 09, 2023
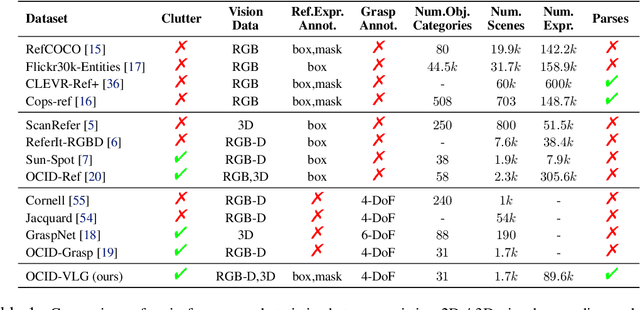
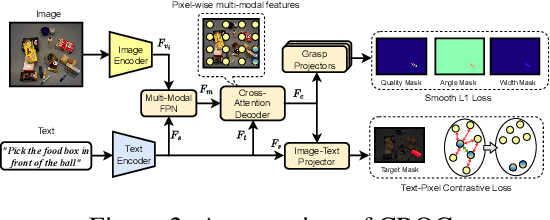
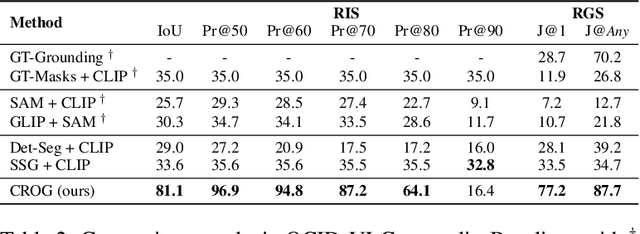
Robots operating in human-centric environments require the integration of visual grounding and grasping capabilities to effectively manipulate objects based on user instructions. This work focuses on the task of referring grasp synthesis, which predicts a grasp pose for an object referred through natural language in cluttered scenes. Existing approaches often employ multi-stage pipelines that first segment the referred object and then propose a suitable grasp, and are evaluated in private datasets or simulators that do not capture the complexity of natural indoor scenes. To address these limitations, we develop a challenging benchmark based on cluttered indoor scenes from OCID dataset, for which we generate referring expressions and connect them with 4-DoF grasp poses. Further, we propose a novel end-to-end model (CROG) that leverages the visual grounding capabilities of CLIP to learn grasp synthesis directly from image-text pairs. Our results show that vanilla integration of CLIP with pretrained models transfers poorly in our challenging benchmark, while CROG achieves significant improvements both in terms of grounding and grasping. Extensive robot experiments in both simulation and hardware demonstrate the effectiveness of our approach in challenging interactive object grasping scenarios that include clutter.
A Hybrid Compositional Reasoning Approach for Interactive Robot Manipulation
Oct 03, 2022



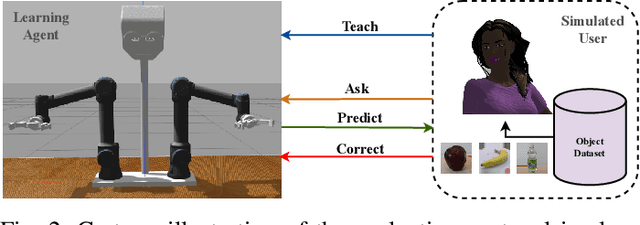
In this paper we present a neuro-symbolic (hybrid) compositional reasoning model for coupling language-guided visual reasoning with robot manipulation. A non-expert human user can prompt the robot agent using natural language, providing either a referring expression (REC), a question (VQA) or a grasp action instruction. The model can tackle all cases in a task-agnostic fashion through the utilization of a shared library of primitive skills. Each primitive handles an independent sub-task, such as reasoning about visual attributes, spatial relation comprehension, logic and enumeration, as well as arm control. A language parser maps the input query to an executable program composed of such primitives depending on the context. While some primitives are purely symbolic operations (e.g. counting), others are trainable neural functions (e.g. grounding words to images), therefore marrying the interpretability and systematic generalization benefits of discrete symbolic approaches with the scalability and representational power of deep networks. We generate a synthetic dataset of tabletop scenes to train our approach and perform several evaluation experiments for VQA in the synthetic and a real RGB-D dataset. Results show that the proposed method achieves very high accuracy while being transferable to novel content with few-shot visual fine-tuning. Finally, we integrate our method with a robot framework and demonstrate how it can serve as an interpretable solution for an interactive object picking task, both in simulation and with a real robot.
A Strong Transfer Baseline for RGB-D Fusion in Vision Transformers
Oct 03, 2022

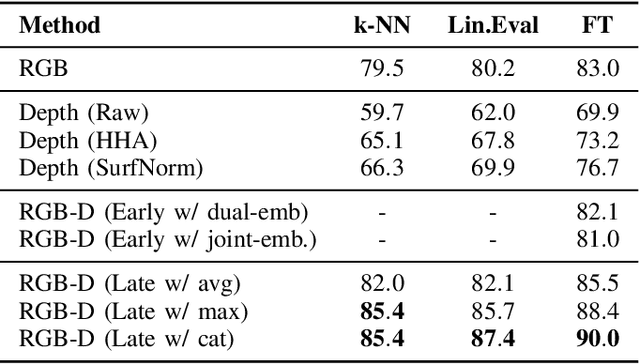
The Vision Transformer (ViT) architecture has recently established its place in the computer vision literature, with multiple architectures for recognition of image data or other visual modalities. However, training ViTs for RGB-D object recognition remains an understudied topic, viewed in recent literature only through the lens of multi-task pretraining in multiple modalities. Such approaches are often computationally intensive and have not yet been applied for challenging object-level classification tasks. In this work, we propose a simple yet strong recipe for transferring pretrained ViTs in RGB-D domains for single-view 3D object recognition, focusing on fusing RGB and depth representations encoded jointly by the ViT. Compared to previous works in multimodal Transformers, the key challenge here is to use the atested flexibility of ViTs to capture cross-modal interactions at the downstream and not the pretraining stage. We explore which depth representation is better in terms of resulting accuracy and compare two methods for injecting RGB-D fusion within the ViT architecture (i.e., early vs. late fusion). Our results in the Washington RGB-D Objects dataset demonstrates that in such RGB $\rightarrow$ RGB-D scenarios, late fusion techniques work better than most popularly employed early fusion. With our transfer baseline, adapted ViTs score up to 95.1\% top-1 accuracy in Washington, achieving new state-of-the-art results in this benchmark. We additionally evaluate our approach with an open-ended lifelong learning protocol, where we show that our adapted RGB-D encoder leads to features that outperform unimodal encoders, even without explicit fine-tuning. We further integrate our method with a robot framework and demonstrate how it can serve as a perception utility in an interactive robot learning scenario, both in simulation and with a real robot.
Sim-To-Real Transfer of Visual Grounding for Human-Aided Ambiguity Resolution
May 24, 2022



Service robots should be able to interact naturally with non-expert human users, not only to help them in various tasks but also to receive guidance in order to resolve ambiguities that might be present in the instruction. We consider the task of visual grounding, where the agent segments an object from a crowded scene given a natural language description. Modern holistic approaches to visual grounding usually ignore language structure and struggle to cover generic domains, therefore relying heavily on large datasets. Additionally, their transfer performance in RGB-D datasets suffers due to high visual discrepancy between the benchmark and the target domains. Modular approaches marry learning with domain modeling and exploit the compositional nature of language to decouple visual representation from language parsing, but either rely on external parsers or are trained in an end-to-end fashion due to the lack of strong supervision. In this work, we seek to tackle these limitations by introducing a fully decoupled modular framework for compositional visual grounding of entities, attributes, and spatial relations. We exploit rich scene graph annotations generated in a synthetic domain and train each module independently. Our approach is evaluated both in simulation and in two real RGB-D scene datasets. Experimental results show that the decoupled nature of our framework allows for easy integration with domain adaptation approaches for Sim-To-Real visual recognition, offering a data-efficient, robust, and interpretable solution to visual grounding in robotic applications.