 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Strong Transfer Baseline for RGB-D Fusion in Vision Transformers
Paper and Code
Oct 03, 2022

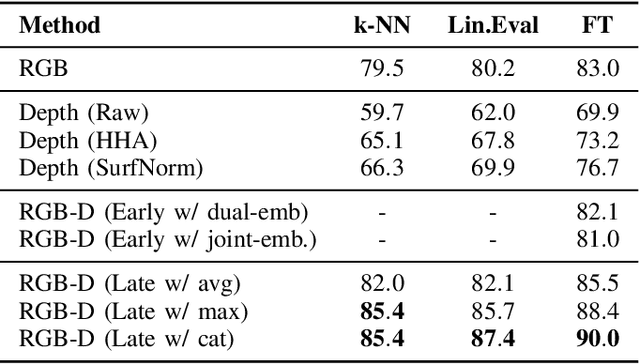
The Vision Transformer (ViT) architecture has recently established its place in the computer vision literature, with multiple architectures for recognition of image data or other visual modalities. However, training ViTs for RGB-D object recognition remains an understudied topic, viewed in recent literature only through the lens of multi-task pretraining in multiple modalities. Such approaches are often computationally intensive and have not yet been applied for challenging object-level classification tasks. In this work, we propose a simple yet strong recipe for transferring pretrained ViTs in RGB-D domains for single-view 3D object recognition, focusing on fusing RGB and depth representations encoded jointly by the ViT. Compared to previous works in multimodal Transformers, the key challenge here is to use the atested flexibility of ViTs to capture cross-modal interactions at the downstream and not the pretraining stage. We explore which depth representation is better in terms of resulting accuracy and compare two methods for injecting RGB-D fusion within the ViT architecture (i.e., early vs. late fusion). Our results in the Washington RGB-D Objects dataset demonstrates that in such RGB $\rightarrow$ RGB-D scenarios, late fusion techniques work better than most popularly employed early fusion. With our transfer baseline, adapted ViTs score up to 95.1\% top-1 accuracy in Washington, achieving new state-of-the-art results in this benchmark. We additionally evaluate our approach with an open-ended lifelong learning protocol, where we show that our adapted RGB-D encoder leads to features that outperform unimodal encoders, even without explicit fine-tuning. We further integrate our method with a robot framework and demonstrate how it can serve as a perception utility in an interactive robot learning scenario, both in simulation and with a real robot.