 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Feature Aggregation or: How Policies Learn to Stop Worrying about Robustness and Attend to Task-Relevant Visual Cues
Nov 13, 2025The adoption of pre-trained visual representations (PVRs), leveraging features from large-scale vision models, has become a popular paradigm for training visuomotor policies. However, these powerful representations can encode a broad range of task-irrelevant scene information, making the resulting trained policies vulnerable to out-of-domain visual changes and distractors. In this work we address visuomotor policy feature pooling as a solution to the observed lack of robustness in perturbed scenes. We achieve this via Attentive Feature Aggregation (AFA), a lightweight, trainable pooling mechanism that learns to naturally attend to task-relevant visual cues, ignoring even semantically rich scene distractors. Through extensive experiments in both simulation and the real world, we demonstrate that policies trained with AFA significantly outperform standard pooling approaches in the presence of visual perturbations, without requiring expensive dataset augmentation or fine-tuning of the PVR. Our findings show that ignoring extraneous visual information is a crucial step towards deploying robust and generalisable visuomotor policies. Project Page: tsagkas.github.io/afa
Fast Flow-based Visuomotor Policies via Conditional Optimal Transport Couplings
May 02, 2025Diffusion and flow matching policies have recently demonstrated remarkable performance in robotic applications by accurately capturing multimodal robot trajectory distributions. However, their computationally expensive inference, due to the numerical integration of an ODE or SDE, limits their applicability as real-time controllers for robots. We introduce a methodology that utilizes conditional Optimal Transport couplings between noise and samples to enforce straight solutions in the flow ODE for robot action generation tasks. We show that naively coupling noise and samples fails in conditional tasks and propose incorporating condition variables into the coupling process to improve few-step performance. The proposed few-step policy achieves a 4% higher success rate with a 10x speed-up compared to Diffusion Policy on a diverse set of simulation tasks. Moreover, it produces high-quality and diverse action trajectories within 1-2 steps on a set of real-world robot tasks. Our method also retains the same training complexity as Diffusion Policy and vanilla Flow Matching, in contrast to distillation-based approaches.
When Pre-trained Visual Representations Fall Short: Limitations in Visuo-Motor Robot Learning
Feb 05, 2025The integration of pre-trained visual representations (PVRs) into visuo-motor robot learning has emerged as a promising alternative to training visual encoders from scratch. However, PVRs face critical challenges in the context of policy learning, including temporal entanglement and an inability to generalise even in the presence of minor scene perturbations. These limitations hinder performance in tasks requiring temporal awareness and robustness to scene changes. This work identifies these shortcomings and proposes solutions to address them. First, we augment PVR features with temporal perception and a sense of task completion, effectively disentangling them in time. Second, we introduce a module that learns to selectively attend to task-relevant local features, enhancing robustness when evaluated on out-of-distribution scenes. Our experiments demonstrate significant performance improvements, particularly in PVRs trained with masking objectives, and validate the effectiveness of our enhancements in addressing PVR-specific limitations.
Learning Precise Affordances from Egocentric Videos for Robotic Manipulation
Aug 19, 2024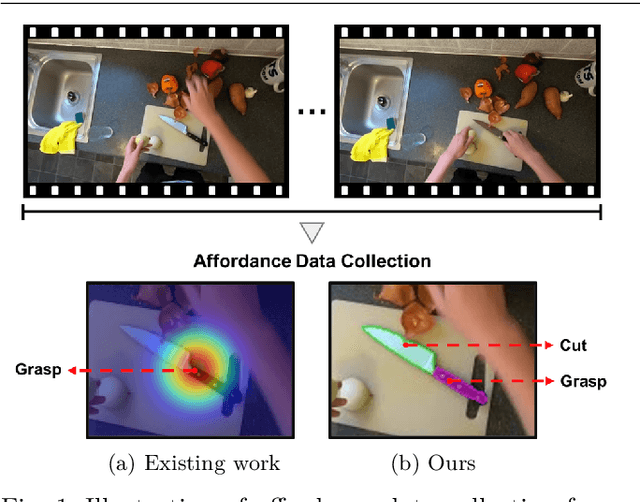

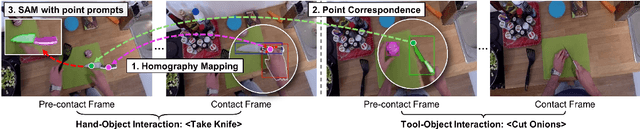
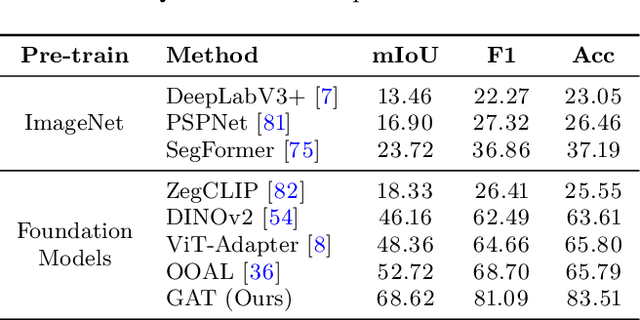
Affordance, defined as the potential actions that an object offers, is crucial for robotic manipulation tasks. A deep understanding of affordance can lead to more intelligent AI systems. For example, such knowledge directs an agent to grasp a knife by the handle for cutting and by the blade when passing it to someone. In this paper, we present a streamlined affordance learning system that encompasses data collection, effective model training, and robot deployment. First, we collect training data from egocentric videos in an automatic manner. Different from previous methods that focus only on the object graspable affordance and represent it as coarse heatmaps, we cover both graspable (e.g., object handles) and functional affordances (e.g., knife blades, hammer heads) and extract data with precise segmentation masks. We then propose an effective model, termed Geometry-guided Affordance Transformer (GKT), to train on the collected data. GKT integrates an innovative Depth Feature Injector (DFI) to incorporate 3D shape and geometric priors, enhancing the model's understanding of affordances. To enable affordance-oriented manipulation, we further introduce Aff-Grasp, a framework that combines GKT with a grasp generation model. For comprehensive evaluation, we create an affordance evaluation dataset with pixel-wise annotations, and design real-world tasks for robot experiments. The results show that GKT surpasses the state-of-the-art by 15.9% in mIoU, and Aff-Grasp achieves high success rates of 95.5% in affordance prediction and 77.1% in successful grasping among 179 trials, including evaluations with seen, unseen objects, and cluttered scenes.
Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors
Mar 21, 2024Precise manipulation that is generalizable across scenes and objects remains a persistent challenge in robotics. Current approaches for this task heavily depend on having a significant number of training instances to handle objects with pronounced visual and/or geometric part ambiguities. Our work explores the grounding of fine-grained part descriptors for precise manipulation in a zero-shot setting by utilizing web-trained text-to-image diffusion-based generative models. We tackle the problem by framing it as a dense semantic part correspondence task. Our model returns a gripper pose for manipulating a specific part, using as reference a user-defined click from a source image of a visually different instance of the same object. We require no manual grasping demonstrations as we leverage the intrinsic object geometry and features. Practical experiments in a real-world tabletop scenario validate the efficacy of our approach, demonstrating its potential for advancing semantic-aware robotics manipulation. Web page: https://tsagkas.github.io/click2grasp
VL-Fields: Towards Language-Grounded Neural Implicit Spatial Representations
May 25, 2023

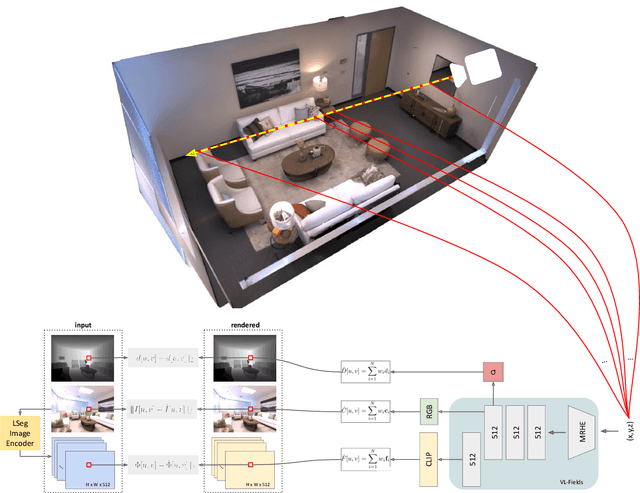
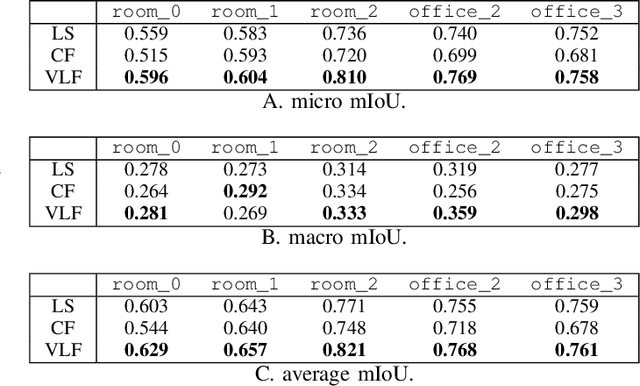
We present Visual-Language Fields (VL-Fields), a neural implicit spatial representation that enables open-vocabulary semantic queries. Our model encodes and fuses the geometry of a scene with vision-language trained latent features by distilling information from a language-driven segmentation model. VL-Fields is trained without requiring any prior knowledge of the scene object classes, which makes it a promising representation for the field of robotics. Our model outperformed the similar CLIP-Fields model in the task of semantic segmentation by almost 10%.
Inference and Learning for Generative Capsule Models
Sep 07, 2022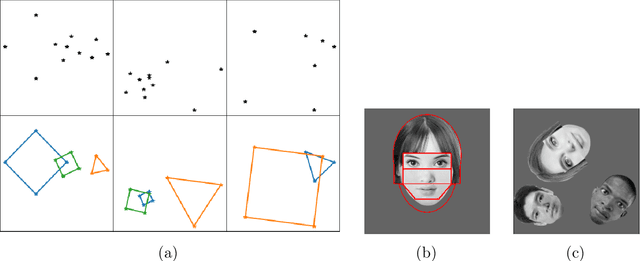
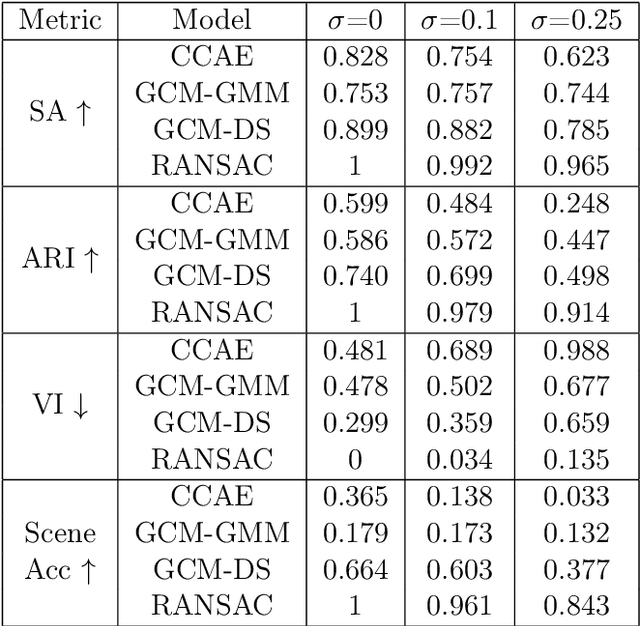

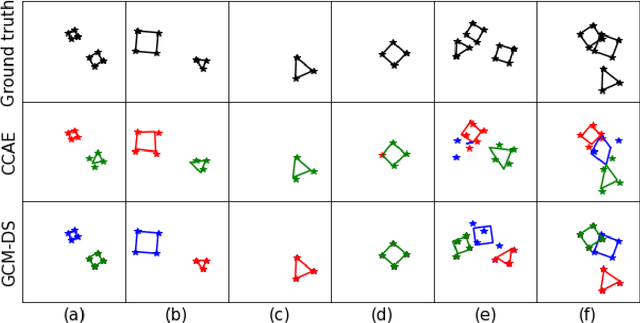
Capsule networks (see e.g. Hinton et al., 2018) aim to encode knowledge of and reason about the relationship between an object and its parts. In this paper we specify a generative model for such data, and derive a variational algorithm for inferring the transformation of each model object in a scene, and the assignments of observed parts to the objects. We derive a learning algorithm for the object models, based on variational expectation maximization (Jordan et al., 1999). We also study an alternative inference algorithm based on the RANSAC method of Fischler and Bolles (1981). We apply these inference methods to (i) data generated from multiple geometric objects like squares and triangles ("constellations"), and (ii) data from a parts-based model of faces. Recent work by Kosiorek et al. (2019) has used amortized inference via stacked capsule autoencoders (SCAEs) to tackle this problem -- our results show that we significantly outperform them where we can make comparisons (on the constellations data).