 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Spurious Correlation from Neural Network Interpretations
Dec 03, 2024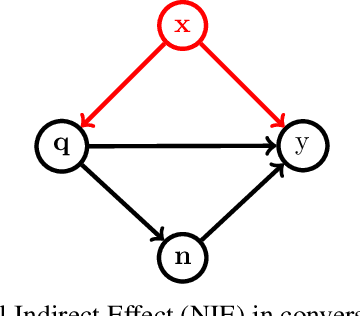
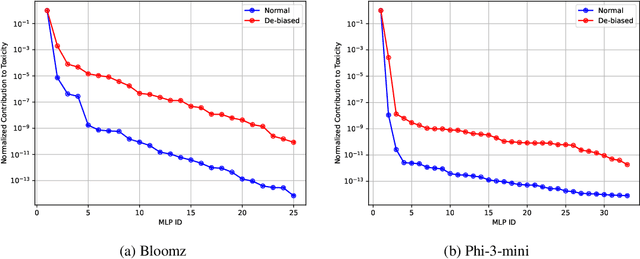
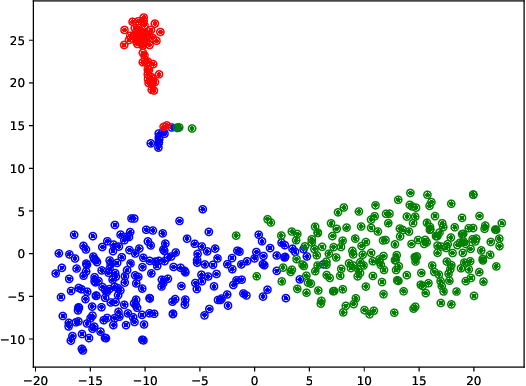
The existing algorithms for identification of neurons responsible for undesired and harmful behaviors do not consider the effects of confounders such as topic of the conversation. In this work, we show that confounders can create spurious correlations and propose a new causal mediation approach that controls the impact of the topic. In experiments with two large language models, we study the localization hypothesis and show that adjusting for the effect of conversation topic, toxicity becomes less localized.
Fast Training Dataset Attribution via In-Context Learning
Aug 14, 2024We investigate the use of in-context learning and prompt engineering to estimate the contributions of training data in the outputs of instruction-tuned large language models (LLMs). We propose two novel approaches: (1) a similarity-based approach that measures the difference between LLM outputs with and without provided context, and (2) a mixture distribution model approach that frames the problem of identifying contribution scores as a matrix factorization task. Our empirical comparison demonstrates that the mixture model approach is more robust to retrieval noise in in-context learning, providing a more reliable estimation of data contributions.