 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Multiply Robust Risk Estimation under General Forms of Dataset Shift
Jun 29, 2023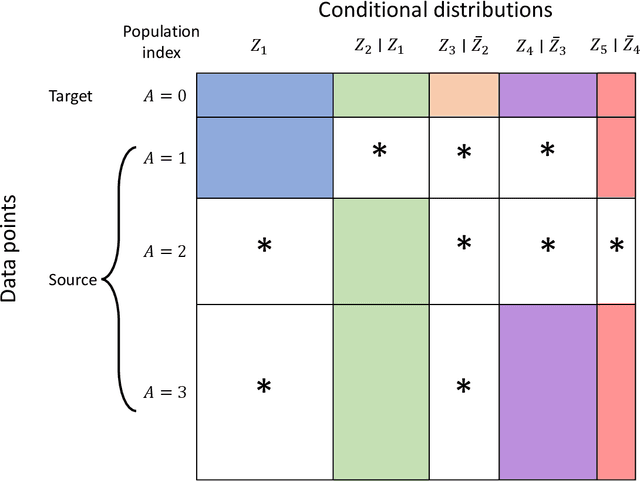

Statistical machine learning methods often face the challenge of limited data available from the population of interest. One remedy is to leverage data from auxiliary source populations, which share some conditional distributions or are linked in other ways with the target domain. Techniques leveraging such \emph{dataset shift} conditions are known as \emph{domain adaptation} or \emph{transfer learning}. Despite extensive literature on dataset shift, limited works address how to efficiently use the auxiliary populations to improve the accuracy of risk evaluation for a given machine learning task in the target population. In this paper, we study the general problem of efficiently estimating target population risk under various dataset shift conditions, leveraging semiparametric efficiency theory. We consider a general class of dataset shift conditions, which includes three popular conditions -- covariate, label and concept shift -- as special cases. We allow for partially non-overlapping support between the source and target populations. We develop efficient and multiply robust estimators along with a straightforward specification test of these dataset shift conditions. We also derive efficiency bounds for two other dataset shift conditions, posterior drift and location-scale shift. Simulation studies support the efficiency gains due to leveraging plausible dataset shift conditions.
Partial Identification of Causal Effects Using Proxy Variables
Apr 23, 2023



Proximal causal inference is a recently proposed framework for evaluating the causal effect of a treatment on an outcome variable in the presence of unmeasured confounding (Miao et al., 2018; Tchetgen Tchetgen et al., 2020). For nonparametric point identification of causal effects, the framework leverages a pair of so-called treatment and outcome confounding proxy variables, in order to identify a bridge function that matches the dependence of potential outcomes or treatment variables on the hidden factors to corresponding functions of observed proxies. Unique identification of a causal effect via a bridge function crucially requires that proxies are sufficiently relevant for hidden factors, a requirement that has previously been formalized as a completeness condition. However, completeness is well-known not to be empirically testable, and although a bridge function may be well-defined in a given setting, lack of completeness, sometimes manifested by availability of a single type of proxy, may severely limit prospects for identification of a bridge function and thus a causal effect; therefore, potentially restricting the application of the proximal causal framework. In this paper, we propose partial identification methods that do not require completeness and obviate the need for identification of a bridge function. That is, we establish that proxies of unobserved confounders can be leveraged to obtain bounds on the causal effect of the treatment on the outcome even if available information does not suffice to identify either a bridge function or a corresponding causal effect of interest. We further establish analogous partial identification results in related settings where identification hinges upon hidden mediators for which proxies are available, however such proxies are not sufficiently rich for point identification of a bridge function or a corresponding causal effect of interest.
Distribution-free Prediction Sets Adaptive to Unknown Covariate Shift
Mar 11, 2022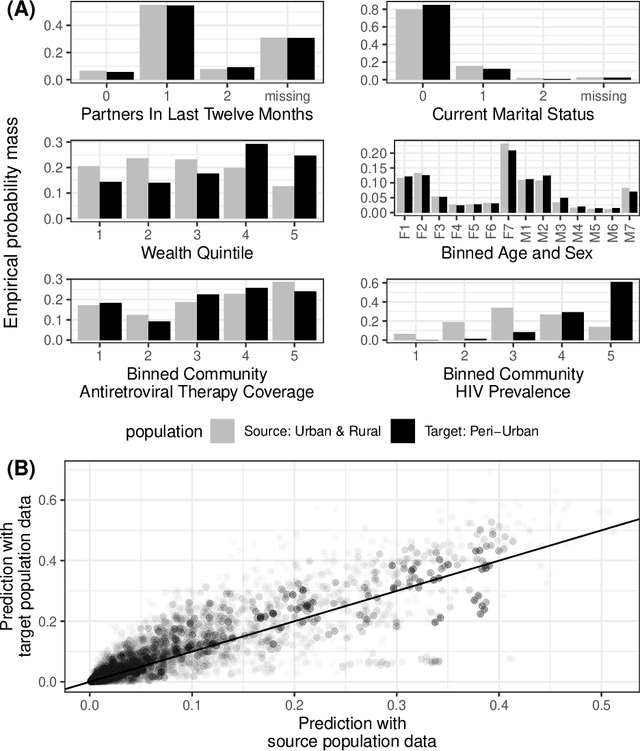
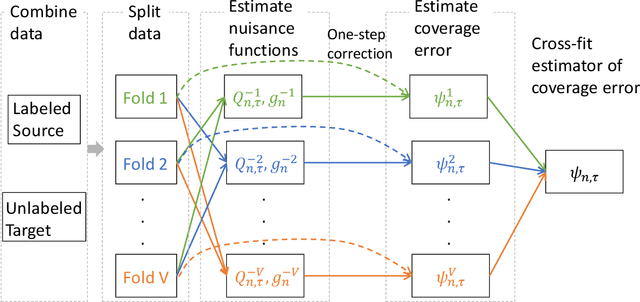


Predicting sets of outcomes -- instead of unique outcomes -- is a promising solution to uncertainty quantification in statistical learning. Despite a rich literature on constructing prediction sets with statistical guarantees, adapting to unknown covariate shift -- a prevalent issue in practice -- poses a serious challenge and has yet to be solved. In the framework of semiparametric statistics, we can view the covariate shift as a nuisance parameter. In this paper, we propose a novel flexible distribution-free method, PredSet-1Step, to construct prediction sets that can efficiently adapt to unknown covariate shift. PredSet-1Step relies on a one-step correction of the plug-in estimator of coverage error. We theoretically show that our methods are asymptotically probably approximately correct (PAC), having low coverage error with high confidence for large samples. PredSet-1Step may also be used to construct asymptotically risk-controlling prediction sets. We illustrate that our method has good coverage in a number of experiments and by analyzing a data set concerning HIV risk prediction in a South African cohort study. In experiments without covariate shift, PredSet-1Step performs similarly to inductive conformal prediction, which has finite-sample PAC properties. Thus, PredSet-1Step may be used in the common scenario if the user suspects -- but may not be certain -- that covariate shift is present, and does not know the form of the shift. Our theory hinges on a new bound for the convergence rate of Wald confidence interval coverage for general asymptotically linear estimators. This is a technical tool of independent interest.
Evaluating Causal Inference Methods
Feb 10, 2022

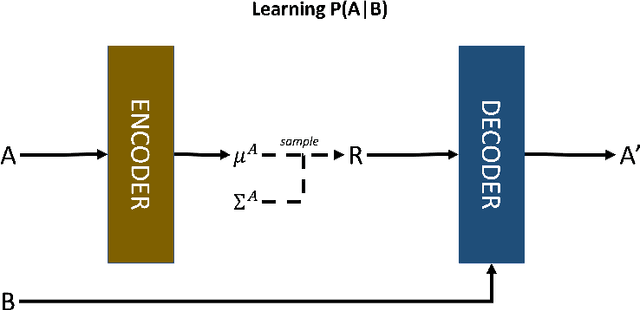
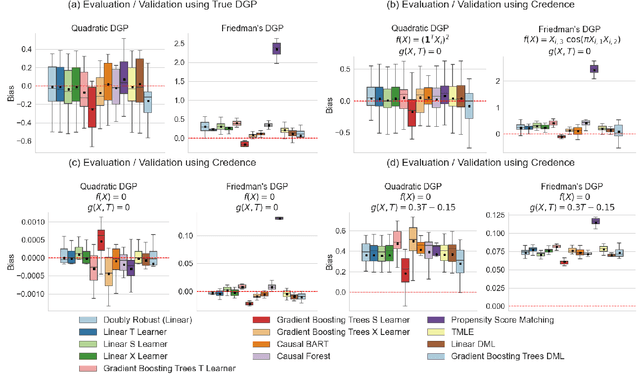
The fundamental challenge of drawing causal inference is that counterfactual outcomes are not fully observed for any unit. Furthermore, in observational studies, treatment assignment is likely to be confounded. Many statistical methods have emerged for causal inference under unconfoundedness conditions given pre-treatment covariates, including propensity score-based methods, prognostic score-based methods, and doubly robust methods. Unfortunately for applied researchers, there is no `one-size-fits-all' causal method that can perform optimally universally. In practice, causal methods are primarily evaluated quantitatively on handcrafted simulated data. Such data-generative procedures can be of limited value because they are typically stylized models of reality. They are simplified for tractability and lack the complexities of real-world data. For applied researchers, it is critical to understand how well a method performs for the data at hand. Our work introduces a deep generative model-based framework, Credence, to validate causal inference methods. The framework's novelty stems from its ability to generate synthetic data anchored at the empirical distribution for the observed sample, and therefore virtually indistinguishable from the latter. The approach allows the user to specify ground truth for the form and magnitude of causal effects and confounding bias as functions of covariates. Thus simulated data sets are used to evaluate the potential performance of various causal estimation methods when applied to data similar to the observed sample. We demonstrate Credence's ability to accurately assess the relative performance of causal estimation techniques in an extensive simulation study and two real-world data applications from Lalonde and Project STAR studies.
Combining Experimental and Observational Data for Identification of Long-Term Causal Effects
Jan 26, 2022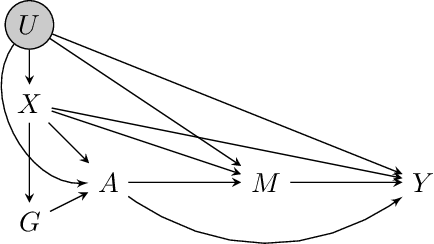
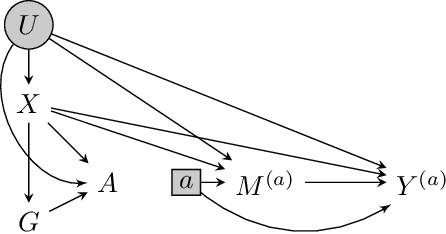
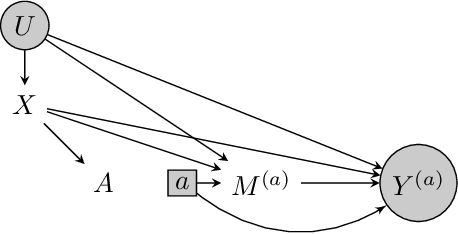
We consider the task of estimating the causal effect of a treatment variable on a long-term outcome variable using data from an observational domain and an experimental domain. The observational data is assumed to be confounded and hence without further assumptions, this dataset alone cannot be used for causal inference. Also, only a short-term version of the primary outcome variable of interest is observed in the experimental data, and hence, this dataset alone cannot be used for causal inference either. In a recent work, Athey et al. (2020) proposed a method for systematically combining such data for identifying the downstream causal effect in view. Their approach is based on the assumptions of internal and external validity of the experimental data, and an extra novel assumption called latent unconfoundedness. In this paper, we first review their proposed approach and discuss the latent unconfoundedness assumption. Then we propose two alternative approaches for data fusion for the purpose of estimating average treatment effect as well as the effect of treatment on the treated. Our first proposed approach is based on assuming equi-confounding bias for the short-term and long-term outcomes. Our second proposed approach is based on the proximal causal inference framework, in which we assume the existence of an extra variable in the system which is a proxy of the latent confounder of the treatment-outcome relation.
A General Framework for Treatment Effect Estimation in Semi-Supervised and High Dimensional Settings
Jan 24, 2022
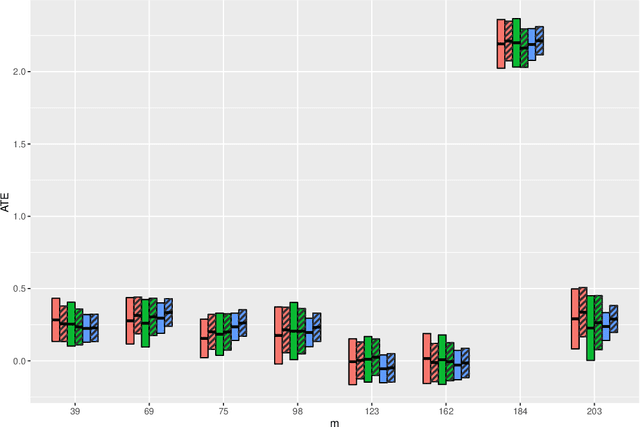
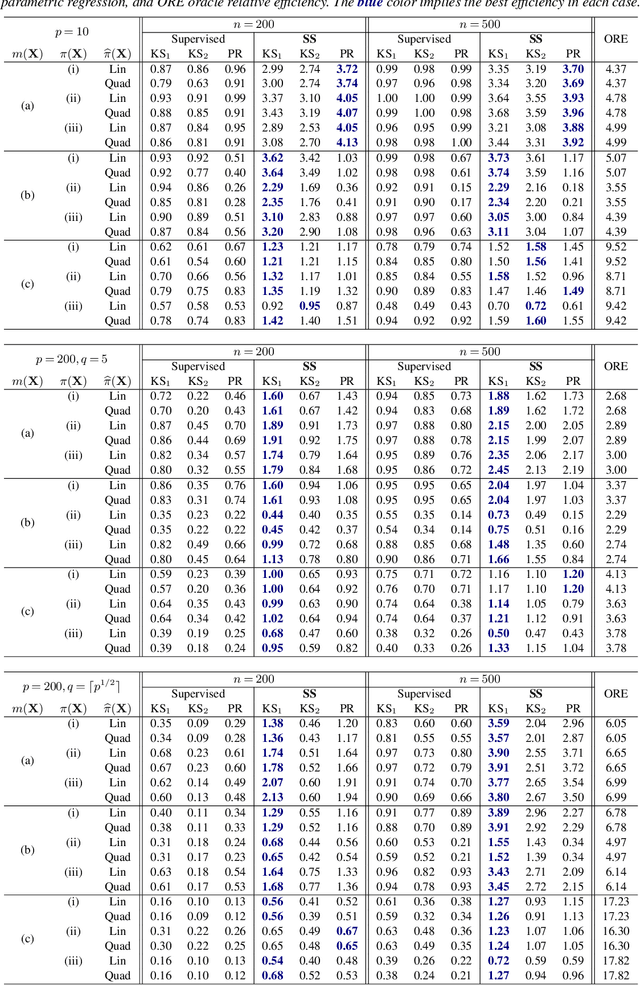
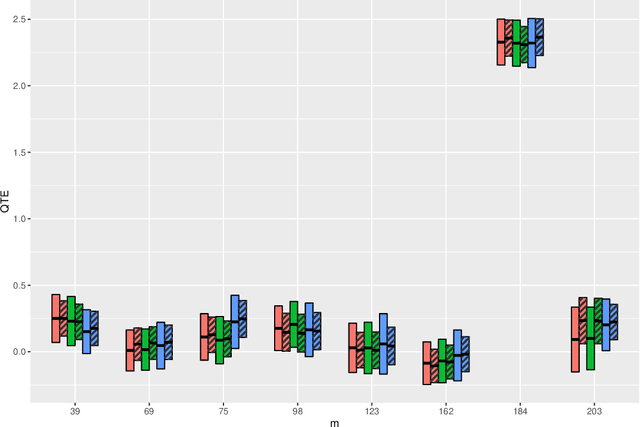
In this article, we aim to provide a general and complete understanding of semi-supervised (SS) causal inference for treatment effects. Specifically, we consider two such estimands: (a) the average treatment effect and (b) the quantile treatment effect, as prototype cases, in an SS setting, characterized by two available data sets: (i) a labeled data set of size $n$, providing observations for a response and a set of high dimensional covariates, as well as a binary treatment indicator; and (ii) an unlabeled data set of size $N$, much larger than $n$, but without the response observed. Using these two data sets, we develop a family of SS estimators which are ensured to be: (1) more robust and (2) more efficient than their supervised counterparts based on the labeled data set only. Beyond the 'standard' double robustness results (in terms of consistency) that can be achieved by supervised methods as well, we further establish root-n consistency and asymptotic normality of our SS estimators whenever the propensity score in the model is correctly specified, without requiring specific forms of the nuisance functions involved. Such an improvement of robustness arises from the use of the massive unlabeled data, so it is generally not attainable in a purely supervised setting. In addition, our estimators are shown to be semi-parametrically efficient as long as all the nuisance functions are correctly specified. Moreover, as an illustration of the nuisance estimators, we consider inverse-probability-weighting type kernel smoothing estimators involving unknown covariate transformation mechanisms, and establish in high dimensional scenarios novel results on their uniform convergence rates, which should be of independent interest. Numerical results on both simulated and real data validate the advantage of our methods over their supervised counterparts with respect to both robustness and efficiency.
Proximal Causal Inference with Hidden Mediators: Front-Door and Related Mediation Problems
Nov 04, 2021

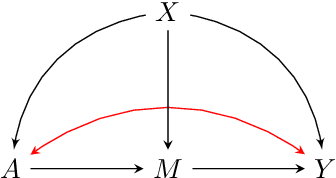
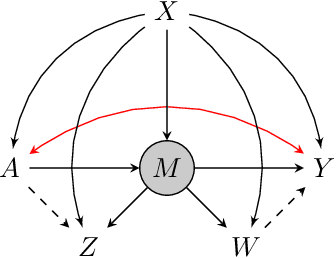
Proximal causal inference was recently proposed as a framework to identify causal effects from observational data in the presence of hidden confounders for which proxies are available. In this paper, we extend the proximal causal approach to settings where identification of causal effects hinges upon a set of mediators which unfortunately are not directly observed, however proxies of the hidden mediators are measured. Specifically, we establish (i) a new hidden front-door criterion which extends the classical front-door result to allow for hidden mediators for which proxies are available; (ii) We extend causal mediation analysis to identify direct and indirect causal effects under unconfoundedness conditions in a setting where the mediator in view is hidden, but error prone proxies of the latter are available. We view (i) and (ii) as important steps towards the practical application of front-door criteria and mediation analysis as mediators are almost always error prone and thus, the most one can hope for in practice is that our measurements are at best proxies of mediating mechanisms. Finally, we show that identification of certain causal effects remains possible even in settings where challenges in (i) and (ii) might co-exist.
End-to-End Balancing for Causal Continuous Treatment-Effect Estimation
Jul 27, 2021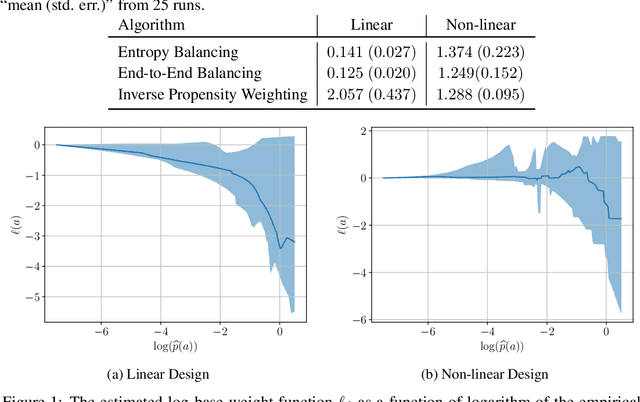
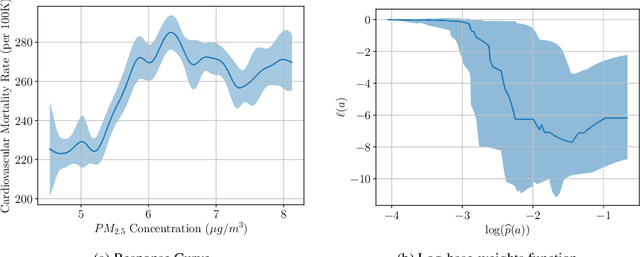
We study the problem of observational causal inference with continuous treatment. We focus on the challenge of estimating the causal response curve for infrequently-observed treatment values. We design a new algorithm based on the framework of entropy balancing which learns weights that directly maximize causal inference accuracy using end-to-end optimization. Our weights can be customized for different datasets and causal inference algorithms. We propose a new theory for consistency of entropy balancing for continuous treatments. Using synthetic and real-world data, we show that our proposed algorithm outperforms the entropy balancing in terms of causal inference accuracy.
Minimax Kernel Machine Learning for a Class of Doubly Robust Functionals
Apr 07, 2021

A moment function is called doubly robust if it is comprised of two nuisance functions and the estimator based on it is a consistent estimator of the target parameter even if one of the nuisance functions is misspecified. In this paper, we consider a class of doubly robust moment functions originally introduced in (Robins et al., 2008). We demonstrate that this moment function can be used to construct estimating equations for the nuisance functions. The main idea is to choose each nuisance function such that it minimizes the dependency of the expected value of the moment function to the other nuisance function. We implement this idea as a minimax optimization problem. We then provide conditions required for asymptotic linearity of the estimator of the parameter of interest, which are based on the convergence rate of the product of the errors of the nuisance functions, as well as the local ill-posedness of a conditional expectation operator. The convergence rates of the nuisance functions are analyzed using the modern techniques in statistical learning theory based on the Rademacher complexity of the function spaces. We specifically focus on the case that the function spaces are reproducing kernel Hilbert spaces, which enables us to use its spectral properties to analyze the convergence rates. As an application of the proposed methodology, we consider the parameter of average causal effect both in presence and absence of latent confounders. For the case of presence of latent confounders, we use the recently proposed proximal causal inference framework of (Miao et al., 2018; Tchetgen Tchetgen et al., 2020), and hence our results lead to a robust non-parametric estimator for average causal effect in this framework.
A semiparametric instrumental variable approach to optimal treatment regimes under endogeneity
Nov 21, 2019
There is a fast-growing literature on estimating optimal treatment regimes based on randomized trials or observational studies under a key identifying condition of no unmeasured confounding. Because confounding by unmeasured factors cannot generally be ruled out with certainty in observational studies or randomized trials subject to noncompliance, we propose a general instrumental variable approach to learning optimal treatment regimes under endogeneity. Specifically, we provide sufficient conditions for the identification of both value function $E[Y_{\cD(L)}]$ for a given regime $\cD$ and optimal regime $\arg \max_{\cD} E[Y_{\cD(L)}]$ with the aid of a binary instrumental variable, when no unmeasured confounding fails to hold. We establish consistency of the proposed weighted estimators. We also extend the proposed method to identify and estimate the optimal treatment regime among those who would comply to the assigned treatment under monotonicity. In this latter case, we establish the somewhat surprising result that the complier optimal regime can be consistently estimated without directly collecting compliance information and therefore without the complier average treatment effect itself being identified. Furthermore, we propose novel semiparametric locally efficient and multiply robust estimators. Our approach is illustrated via extensive simulation studies and a data application on the effect of child rearing on labor participation.