 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Imitation Learning Under Measurement Error and Distribution Shift
Jan 29, 2026We study offline imitation learning (IL) when part of the decision-relevant state is observed only through noisy measurements and the distribution may change between training and deployment. Such settings induce spurious state-action correlations, so standard behavioral cloning (BC) -- whether conditioning on raw measurements or ignoring them -- can converge to systematically biased policies under distribution shift. We propose a general framework for IL under measurement error, inspired by explicitly modeling the causal relationships among the variables, yielding a target that retains a causal interpretation and is robust to distribution shift. Building on ideas from proximal causal inference, we introduce \texttt{CausIL}, which treats noisy state observations as proxy variables, and we provide identification conditions under which the target policy is recoverable from demonstrations without rewards or interactive expert queries. We develop estimators for both discrete and continuous state spaces; for continuous settings, we use an adversarial procedure over RKHS function classes to learn the required parameters. We evaluate \texttt{CausIL} on semi-simulated longitudinal data from the PhysioNet/Computing in Cardiology Challenge 2019 cohort and demonstrate improved robustness to distribution shift compared to BC baselines.
Debiased Ill-Posed Regression
May 27, 2025In various statistical settings, the goal is to estimate a function which is restricted by the statistical model only through a conditional moment restriction. Prominent examples include the nonparametric instrumental variable framework for estimating the structural function of the outcome variable, and the proximal causal inference framework for estimating the bridge functions. A common strategy in the literature is to find the minimizer of the projected mean squared error. However, this approach can be sensitive to misspecification or slow convergence rate of the estimators of the involved nuisance components. In this work, we propose a debiased estimation strategy based on the influence function of a modification of the projected error and demonstrate its finite-sample convergence rate. Our proposed estimator possesses a second-order bias with respect to the involved nuisance functions and a desirable robustness property with respect to the misspecification of one of the nuisance functions. The proposed estimator involves a hyper-parameter, for which the optimal value depends on potentially unknown features of the underlying data-generating process. Hence, we further propose a hyper-parameter selection approach based on cross-validation and derive an error bound for the resulting estimator. This analysis highlights the potential rate loss due to hyper-parameter selection and underscore the importance and advantages of incorporating debiasing in this setting. We also study the application of our approach to the estimation of regular parameters in a specific parameter class, which are linear functionals of the solutions to the conditional moment restrictions and provide sufficient conditions for achieving root-n consistency using our debiased estimator.
Causal Discovery in Linear Models with Unobserved Variables and Measurement Error
Jul 28, 2024The presence of unobserved common causes and the presence of measurement error are two of the most limiting challenges in the task of causal structure learning. Ignoring either of the two challenges can lead to detecting spurious causal links among variables of interest. In this paper, we study the problem of causal discovery in systems where these two challenges can be present simultaneously. We consider linear models which include four types of variables: variables that are directly observed, variables that are not directly observed but are measured with error, the corresponding measurements, and variables that are neither observed nor measured. We characterize the extent of identifiability of such model under separability condition (i.e., the matrix indicating the independent exogenous noise terms pertaining to the observed variables is identifiable) together with two versions of faithfulness assumptions and propose a notion of observational equivalence. We provide graphical characterization of the models that are equivalent and present a recovery algorithm that could return models equivalent to the ground truth.
Two-Stage Nuisance Function Estimation for Causal Mediation Analysis
Mar 31, 2024
When estimating the direct and indirect causal effects using the influence function-based estimator of the mediation functional, it is crucial to understand what aspects of the treatment, the mediator, and the outcome mean mechanisms should be focused on. Specifically, considering them as nuisance functions and attempting to fit these nuisance functions as accurate as possible is not necessarily the best approach to take. In this work, we propose a two-stage estimation strategy for the nuisance functions that estimates the nuisance functions based on the role they play in the structure of the bias of the influence function-based estimator of the mediation functional. We provide robustness analysis of the proposed method, as well as sufficient conditions for consistency and asymptotic normality of the estimator of the parameter of interest.
Identification and Estimation for Nonignorable Missing Data: A Data Fusion Approach
Nov 15, 2023



We consider the task of identifying and estimating a parameter of interest in settings where data is missing not at random (MNAR). In general, such parameters are not identified without strong assumptions on the missing data model. In this paper, we take an alternative approach and introduce a method inspired by data fusion, where information in an MNAR dataset is augmented by information in an auxiliary dataset subject to missingness at random (MAR). We show that even if the parameter of interest cannot be identified given either dataset alone, it can be identified given pooled data, under two complementary sets of assumptions. We derive an inverse probability weighted (IPW) estimator for identified parameters, and evaluate the performance of our estimation strategies via simulation studies.
Partial Identification of Causal Effects Using Proxy Variables
Apr 23, 2023



Proximal causal inference is a recently proposed framework for evaluating the causal effect of a treatment on an outcome variable in the presence of unmeasured confounding (Miao et al., 2018; Tchetgen Tchetgen et al., 2020). For nonparametric point identification of causal effects, the framework leverages a pair of so-called treatment and outcome confounding proxy variables, in order to identify a bridge function that matches the dependence of potential outcomes or treatment variables on the hidden factors to corresponding functions of observed proxies. Unique identification of a causal effect via a bridge function crucially requires that proxies are sufficiently relevant for hidden factors, a requirement that has previously been formalized as a completeness condition. However, completeness is well-known not to be empirically testable, and although a bridge function may be well-defined in a given setting, lack of completeness, sometimes manifested by availability of a single type of proxy, may severely limit prospects for identification of a bridge function and thus a causal effect; therefore, potentially restricting the application of the proximal causal framework. In this paper, we propose partial identification methods that do not require completeness and obviate the need for identification of a bridge function. That is, we establish that proxies of unobserved confounders can be leveraged to obtain bounds on the causal effect of the treatment on the outcome even if available information does not suffice to identify either a bridge function or a corresponding causal effect of interest. We further establish analogous partial identification results in related settings where identification hinges upon hidden mediators for which proxies are available, however such proxies are not sufficiently rich for point identification of a bridge function or a corresponding causal effect of interest.
Causal Discovery in Linear Latent Variable Models Subject to Measurement Error
Nov 08, 2022We focus on causal discovery in the presence of measurement error in linear systems where the mixing matrix, i.e., the matrix indicating the independent exogenous noise terms pertaining to the observed variables, is identified up to permutation and scaling of the columns. We demonstrate a somewhat surprising connection between this problem and causal discovery in the presence of unobserved parentless causes, in the sense that there is a mapping, given by the mixing matrix, between the underlying models to be inferred in these problems. Consequently, any identifiability result based on the mixing matrix for one model translates to an identifiability result for the other model. We characterize to what extent the causal models can be identified under a two-part faithfulness assumption. Under only the first part of the assumption (corresponding to the conventional definition of faithfulness), the structure can be learned up to the causal ordering among an ordered grouping of the variables but not all the edges across the groups can be identified. We further show that if both parts of the faithfulness assumption are imposed, the structure can be learned up to a more refined ordered grouping. As a result of this refinement, for the latent variable model with unobserved parentless causes, the structure can be identified. Based on our theoretical results, we propose causal structure learning methods for both models, and evaluate their performance on synthetic data.
A Unified Experiment Design Approach for Cyclic and Acyclic Causal Models
May 20, 2022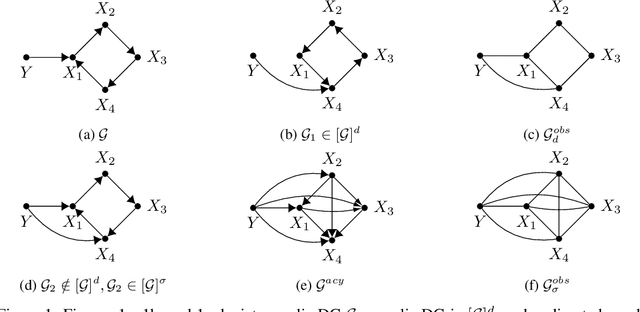

We study experiment design for the unique identification of the causal graph of a system where the graph may contain cycles. The presence of cycles in the structure introduces major challenges for experiment design. Unlike the case of acyclic graphs, learning the skeleton of the causal graph from observational distribution may not be possible. Furthermore, intervening on a variable does not necessarily lead to orienting all the edges incident to it. In this paper, we propose an experiment design approach that can learn both cyclic and acyclic graphs and hence, unifies the task of experiment design for both types of graphs. We provide a lower bound on the number of experiments required to guarantee the unique identification of the causal graph in the worst case, showing that the proposed approach is order-optimal in terms of the number of experiments up to an additive logarithmic term. Moreover, we extend our result to the setting where the size of each experiment is bounded by a constant. For this case, we show that our approach is optimal in terms of the size of the largest experiment required for the unique identification of the causal graph in the worst case.
Combining Experimental and Observational Data for Identification of Long-Term Causal Effects
Jan 26, 2022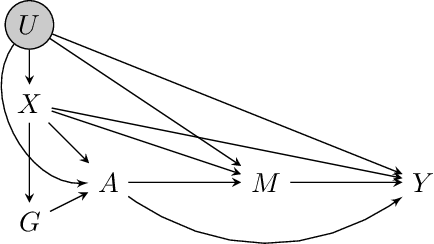
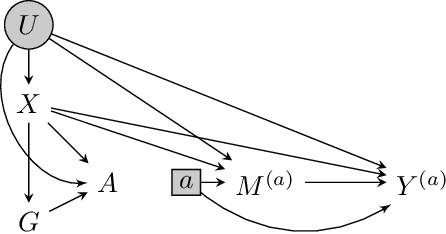
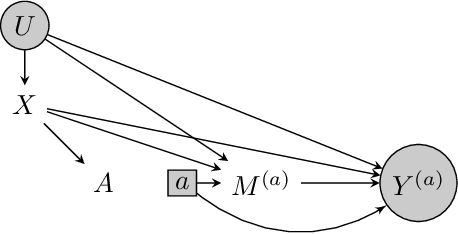
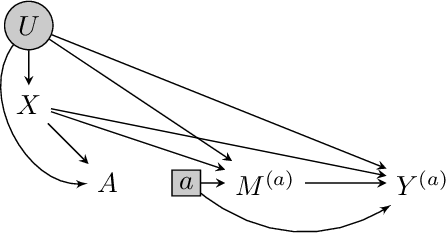
We consider the task of estimating the causal effect of a treatment variable on a long-term outcome variable using data from an observational domain and an experimental domain. The observational data is assumed to be confounded and hence without further assumptions, this dataset alone cannot be used for causal inference. Also, only a short-term version of the primary outcome variable of interest is observed in the experimental data, and hence, this dataset alone cannot be used for causal inference either. In a recent work, Athey et al. (2020) proposed a method for systematically combining such data for identifying the downstream causal effect in view. Their approach is based on the assumptions of internal and external validity of the experimental data, and an extra novel assumption called latent unconfoundedness. In this paper, we first review their proposed approach and discuss the latent unconfoundedness assumption. Then we propose two alternative approaches for data fusion for the purpose of estimating average treatment effect as well as the effect of treatment on the treated. Our first proposed approach is based on assuming equi-confounding bias for the short-term and long-term outcomes. Our second proposed approach is based on the proximal causal inference framework, in which we assume the existence of an extra variable in the system which is a proxy of the latent confounder of the treatment-outcome relation.
Proximal Causal Inference with Hidden Mediators: Front-Door and Related Mediation Problems
Nov 04, 2021

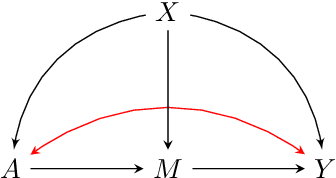
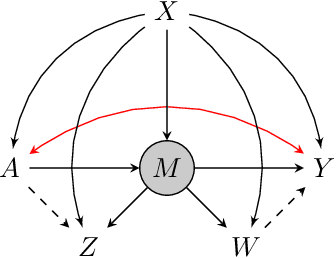
Proximal causal inference was recently proposed as a framework to identify causal effects from observational data in the presence of hidden confounders for which proxies are available. In this paper, we extend the proximal causal approach to settings where identification of causal effects hinges upon a set of mediators which unfortunately are not directly observed, however proxies of the hidden mediators are measured. Specifically, we establish (i) a new hidden front-door criterion which extends the classical front-door result to allow for hidden mediators for which proxies are available; (ii) We extend causal mediation analysis to identify direct and indirect causal effects under unconfoundedness conditions in a setting where the mediator in view is hidden, but error prone proxies of the latter are available. We view (i) and (ii) as important steps towards the practical application of front-door criteria and mediation analysis as mediators are almost always error prone and thus, the most one can hope for in practice is that our measurements are at best proxies of mediating mechanisms. Finally, we show that identification of certain causal effects remains possible even in settings where challenges in (i) and (ii) might co-exist.