 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Multiply Robust Risk Estimation under General Forms of Dataset Shift
Jun 29, 2023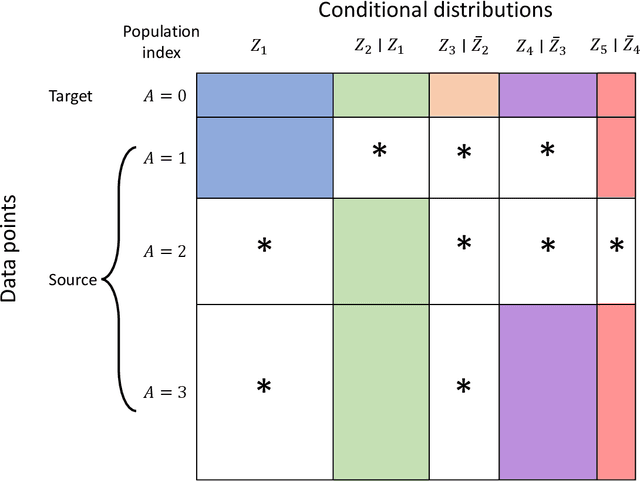

Statistical machine learning methods often face the challenge of limited data available from the population of interest. One remedy is to leverage data from auxiliary source populations, which share some conditional distributions or are linked in other ways with the target domain. Techniques leveraging such \emph{dataset shift} conditions are known as \emph{domain adaptation} or \emph{transfer learning}. Despite extensive literature on dataset shift, limited works address how to efficiently use the auxiliary populations to improve the accuracy of risk evaluation for a given machine learning task in the target population. In this paper, we study the general problem of efficiently estimating target population risk under various dataset shift conditions, leveraging semiparametric efficiency theory. We consider a general class of dataset shift conditions, which includes three popular conditions -- covariate, label and concept shift -- as special cases. We allow for partially non-overlapping support between the source and target populations. We develop efficient and multiply robust estimators along with a straightforward specification test of these dataset shift conditions. We also derive efficiency bounds for two other dataset shift conditions, posterior drift and location-scale shift. Simulation studies support the efficiency gains due to leveraging plausible dataset shift conditions.
Distribution-free Prediction Sets Adaptive to Unknown Covariate Shift
Mar 11, 2022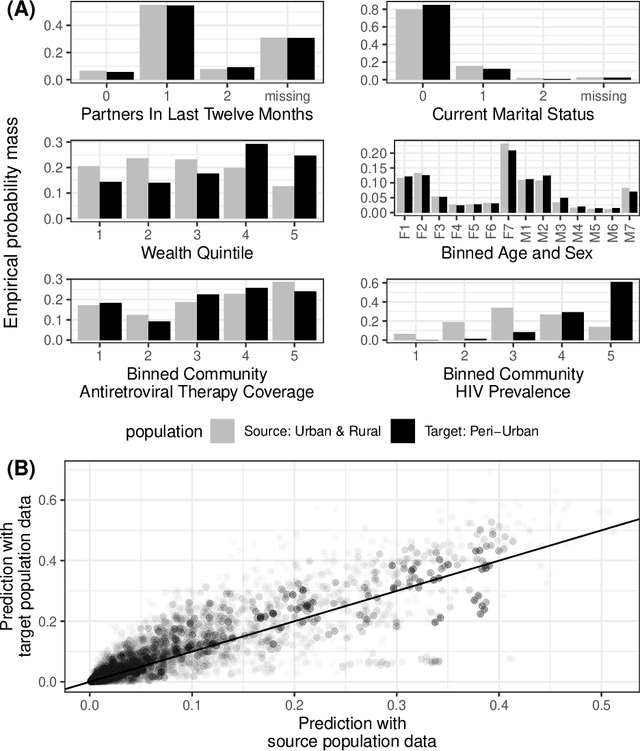
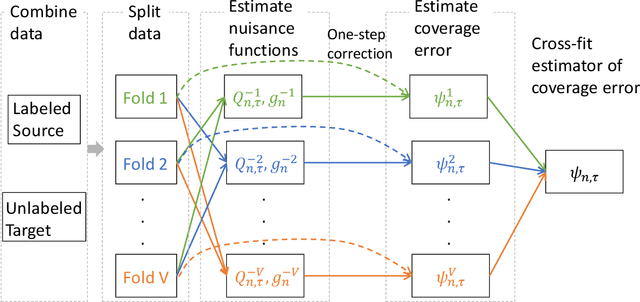


Predicting sets of outcomes -- instead of unique outcomes -- is a promising solution to uncertainty quantification in statistical learning. Despite a rich literature on constructing prediction sets with statistical guarantees, adapting to unknown covariate shift -- a prevalent issue in practice -- poses a serious challenge and has yet to be solved. In the framework of semiparametric statistics, we can view the covariate shift as a nuisance parameter. In this paper, we propose a novel flexible distribution-free method, PredSet-1Step, to construct prediction sets that can efficiently adapt to unknown covariate shift. PredSet-1Step relies on a one-step correction of the plug-in estimator of coverage error. We theoretically show that our methods are asymptotically probably approximately correct (PAC), having low coverage error with high confidence for large samples. PredSet-1Step may also be used to construct asymptotically risk-controlling prediction sets. We illustrate that our method has good coverage in a number of experiments and by analyzing a data set concerning HIV risk prediction in a South African cohort study. In experiments without covariate shift, PredSet-1Step performs similarly to inductive conformal prediction, which has finite-sample PAC properties. Thus, PredSet-1Step may be used in the common scenario if the user suspects -- but may not be certain -- that covariate shift is present, and does not know the form of the shift. Our theory hinges on a new bound for the convergence rate of Wald confidence interval coverage for general asymptotically linear estimators. This is a technical tool of independent interest.
Leveraging vague prior information in general models via iteratively constructed Gamma-minimax estimators
Dec 10, 2020

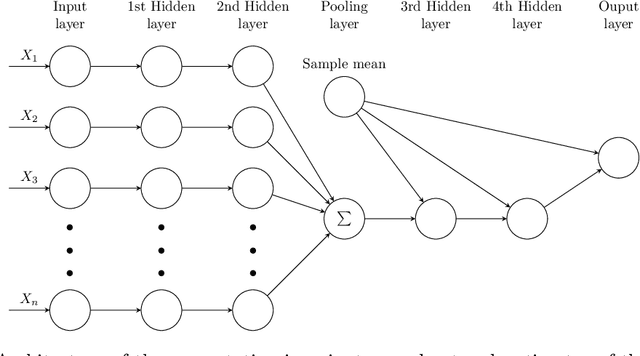
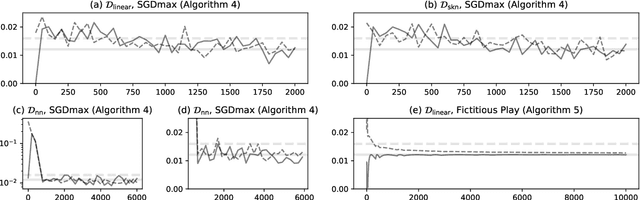
Gamma-minimax estimation is an approach to incorporate prior information into an estimation procedure when it is implausible to specify one particular prior distribution. In this approach, we aim for an estimator that minimizes the worst-case Bayes risk over a set $\Gamma$ of prior distributions. Traditionally, Gamma-minimax estimation is defined for parametric models. In this paper, we define Gamma-minimaxity for general models and propose iterative algorithms with convergence guarantees to compute Gamma-minimax estimators for a general model space and a set of prior distributions constrained by generalized moments. We also propose encoding the space of candidate estimators by neural networks to enable flexible estimation. We illustrate our method in two settings, namely entropy estimation and a problem that arises in biodiversity studies.