 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Multiply Robust Risk Estimation under General Forms of Dataset Shift
Paper and Code
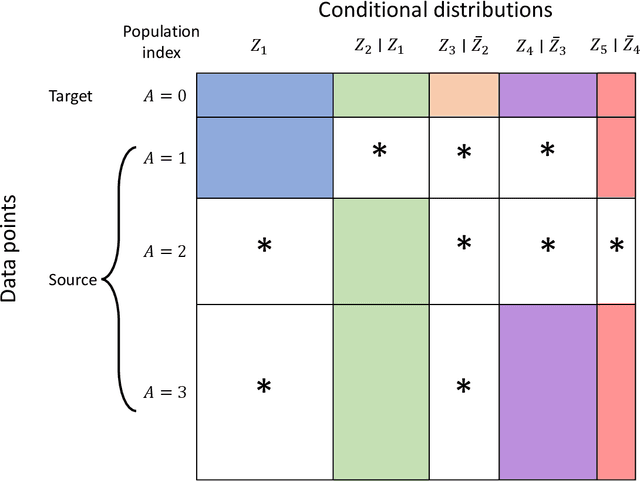

Statistical machine learning methods often face the challenge of limited data available from the population of interest. One remedy is to leverage data from auxiliary source populations, which share some conditional distributions or are linked in other ways with the target domain. Techniques leveraging such \emph{dataset shift} conditions are known as \emph{domain adaptation} or \emph{transfer learning}. Despite extensive literature on dataset shift, limited works address how to efficiently use the auxiliary populations to improve the accuracy of risk evaluation for a given machine learning task in the target population. In this paper, we study the general problem of efficiently estimating target population risk under various dataset shift conditions, leveraging semiparametric efficiency theory. We consider a general class of dataset shift conditions, which includes three popular conditions -- covariate, label and concept shift -- as special cases. We allow for partially non-overlapping support between the source and target populations. We develop efficient and multiply robust estimators along with a straightforward specification test of these dataset shift conditions. We also derive efficiency bounds for two other dataset shift conditions, posterior drift and location-scale shift. Simulation studies support the efficiency gains due to leveraging plausible dataset shift conditions.