 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference on Local Variable Importance Measures for Heterogeneous Treatment Effects
Oct 21, 2025We provide an inferential framework to assess variable importance for heterogeneous treatment effects. This assessment is especially useful in high-risk domains such as medicine, where decision makers hesitate to rely on black-box treatment recommendation algorithms. The variable importance measures we consider are local in that they may differ across individuals, while the inference is global in that it tests whether a given variable is important for any individual. Our approach builds on recent developments in semiparametric theory for function-valued parameters, and is valid even when statistical machine learning algorithms are employed to quantify treatment effect heterogeneity. We demonstrate the applicability of our method to infectious disease prevention strategies.
Coreset selection for the Sinkhorn divergence and generic smooth divergences
Apr 28, 2025
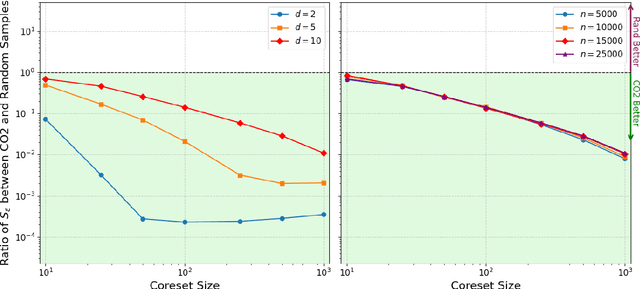
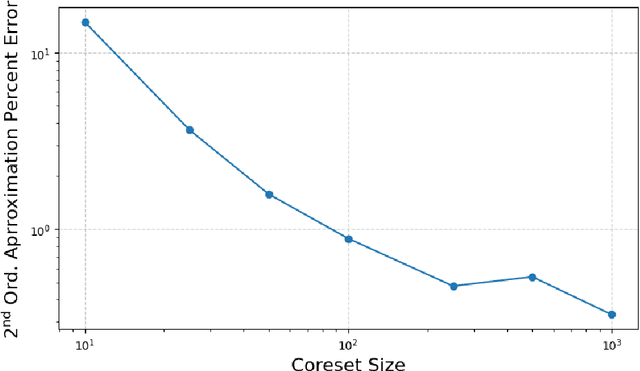

We introduce CO2, an efficient algorithm to produce convexly-weighted coresets with respect to generic smooth divergences. By employing a functional Taylor expansion, we show a local equivalence between sufficiently regular losses and their second order approximations, reducing the coreset selection problem to maximum mean discrepancy minimization. We apply CO2 to the Sinkhorn divergence, providing a novel sampling procedure that requires logarithmically many data points to match the approximation guarantees of random sampling. To show this, we additionally verify several new regularity properties for entropically regularized optimal transport of independent interest. Our approach leads to a new perspective linking coreset selection and kernel quadrature to classical statistical methods such as moment and score matching. We showcase this method with a practical application of subsampling image data, and highlight key directions to explore for improved algorithmic efficiency and theoretical guarantees.
Stabilized Inverse Probability Weighting via Isotonic Calibration
Nov 10, 2024Inverse weighting with an estimated propensity score is widely used by estimation methods in causal inference to adjust for confounding bias. However, directly inverting propensity score estimates can lead to instability, bias, and excessive variability due to large inverse weights, especially when treatment overlap is limited. In this work, we propose a post-hoc calibration algorithm for inverse propensity weights that generates well-calibrated, stabilized weights from user-supplied, cross-fitted propensity score estimates. Our approach employs a variant of isotonic regression with a loss function specifically tailored to the inverse propensity weights. Through theoretical analysis and empirical studies, we demonstrate that isotonic calibration improves the performance of doubly robust estimators of the average treatment effect.
Automatic doubly robust inference for linear functionals via calibrated debiased machine learning
Nov 05, 2024In causal inference, many estimands of interest can be expressed as a linear functional of the outcome regression function; this includes, for example, average causal effects of static, dynamic and stochastic interventions. For learning such estimands, in this work, we propose novel debiased machine learning estimators that are doubly robust asymptotically linear, thus providing not only doubly robust consistency but also facilitating doubly robust inference (e.g., confidence intervals and hypothesis tests). To do so, we first establish a key link between calibration, a machine learning technique typically used in prediction and classification tasks, and the conditions needed to achieve doubly robust asymptotic linearity. We then introduce calibrated debiased machine learning (C-DML), a unified framework for doubly robust inference, and propose a specific C-DML estimator that integrates cross-fitting, isotonic calibration, and debiased machine learning estimation. A C-DML estimator maintains asymptotic linearity when either the outcome regression or the Riesz representer of the linear functional is estimated sufficiently well, allowing the other to be estimated at arbitrarily slow rates or even inconsistently. We propose a simple bootstrap-assisted approach for constructing doubly robust confidence intervals. Our theoretical and empirical results support the use of C-DML to mitigate bias arising from the inconsistent or slow estimation of nuisance functions.
Simplifying Debiased Inference via Automatic Differentiation and Probabilistic Programming
May 14, 2024We introduce an algorithm that simplifies the construction of efficient estimators, making them accessible to a broader audience. 'Dimple' takes as input computer code representing a parameter of interest and outputs an efficient estimator. Unlike standard approaches, it does not require users to derive a functional derivative known as the efficient influence function. Dimple avoids this task by applying automatic differentiation to the statistical functional of interest. Doing so requires expressing this functional as a composition of primitives satisfying a novel differentiability condition. Dimple also uses this composition to determine the nuisances it must estimate. In software, primitives can be implemented independently of one another and reused across different estimation problems. We provide a proof-of-concept Python implementation and showcase through examples how it allows users to go from parameter specification to efficient estimation with just a few lines of code.
Combining T-learning and DR-learning: a framework for oracle-efficient estimation of causal contrasts
Feb 03, 2024We introduce efficient plug-in (EP) learning, a novel framework for the estimation of heterogeneous causal contrasts, such as the conditional average treatment effect and conditional relative risk. The EP-learning framework enjoys the same oracle-efficiency as Neyman-orthogonal learning strategies, such as DR-learning and R-learning, while addressing some of their primary drawbacks, including that (i) their practical applicability can be hindered by loss function non-convexity; and (ii) they may suffer from poor performance and instability due to inverse probability weighting and pseudo-outcomes that violate bounds. To avoid these drawbacks, EP-learner constructs an efficient plug-in estimator of the population risk function for the causal contrast, thereby inheriting the stability and robustness properties of plug-in estimation strategies like T-learning. Under reasonable conditions, EP-learners based on empirical risk minimization are oracle-efficient, exhibiting asymptotic equivalence to the minimizer of an oracle-efficient one-step debiased estimator of the population risk function. In simulation experiments, we illustrate that EP-learners of the conditional average treatment effect and conditional relative risk outperform state-of-the-art competitors, including T-learner, R-learner, and DR-learner. Open-source implementations of the proposed methods are available in our R package hte3.
Adaptive debiased machine learning using data-driven model selection techniques
Jul 24, 2023Debiased machine learning estimators for nonparametric inference of smooth functionals of the data-generating distribution can suffer from excessive variability and instability. For this reason, practitioners may resort to simpler models based on parametric or semiparametric assumptions. However, such simplifying assumptions may fail to hold, and estimates may then be biased due to model misspecification. To address this problem, we propose Adaptive Debiased Machine Learning (ADML), a nonparametric framework that combines data-driven model selection and debiased machine learning techniques to construct asymptotically linear, adaptive, and superefficient estimators for pathwise differentiable functionals. By learning model structure directly from data, ADML avoids the bias introduced by model misspecification and remains free from the restrictions of parametric and semiparametric models. While they may exhibit irregular behavior for the target parameter in a nonparametric statistical model, we demonstrate that ADML estimators provides regular and locally uniformly valid inference for a projection-based oracle parameter. Importantly, this oracle parameter agrees with the original target parameter for distributions within an unknown but correctly specified oracle statistical submodel that is learned from the data. This finding implies that there is no penalty, in a local asymptotic sense, for conducting data-driven model selection compared to having prior knowledge of the oracle submodel and oracle parameter. To demonstrate the practical applicability of our theory, we provide a broad class of ADML estimators for estimating the average treatment effect in adaptive partially linear regression models.
One-Step Estimation of Differentiable Hilbert-Valued Parameters
Apr 01, 2023We present estimators for smooth Hilbert-valued parameters, where smoothness is characterized by a pathwise differentiability condition. When the parameter space is a reproducing kernel Hilbert space, we provide a means to obtain efficient, root-n rate estimators and corresponding confidence sets. These estimators correspond to generalizations of cross-fitted one-step estimators based on Hilbert-valued efficient influence functions. We give theoretical guarantees even when arbitrary estimators of nuisance functions are used, including those based on machine learning techniques. We show that these results naturally extend to Hilbert spaces that lack a reproducing kernel, as long as the parameter has an efficient influence function. However, we also uncover the unfortunate fact that, when there is no reproducing kernel, many interesting parameters fail to have an efficient influence function, even though they are pathwise differentiable. To handle these cases, we propose a regularized one-step estimator and associated confidence sets. We also show that pathwise differentiability, which is a central requirement of our approach, holds in many cases. Specifically, we provide multiple examples of pathwise differentiable parameters and develop corresponding estimators and confidence sets. Among these examples, four are particularly relevant to ongoing research by the causal inference community: the counterfactual density function, dose-response function, conditional average treatment effect function, and counterfactual kernel mean embedding.
Causal isotonic calibration for heterogeneous treatment effects
Feb 27, 2023



We propose causal isotonic calibration, a novel nonparametric method for calibrating predictors of heterogeneous treatment effects. In addition, we introduce a novel data-efficient variant of calibration that avoids the need for hold-out calibration sets, which we refer to as cross-calibration. Causal isotonic cross-calibration takes cross-fitted predictors and outputs a single calibrated predictor obtained using all available data. We establish under weak conditions that causal isotonic calibration and cross-calibration both achieve fast doubly-robust calibration rates so long as either the propensity score or outcome regression is estimated well in an appropriate sense. The proposed causal isotonic calibrator can be wrapped around any black-box learning algorithm to provide strong distribution-free calibration guarantees while preserving predictive performance.
Leveraging vague prior information in general models via iteratively constructed Gamma-minimax estimators
Dec 10, 2020

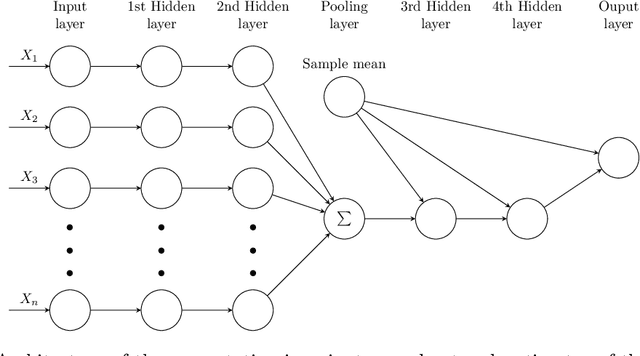
Gamma-minimax estimation is an approach to incorporate prior information into an estimation procedure when it is implausible to specify one particular prior distribution. In this approach, we aim for an estimator that minimizes the worst-case Bayes risk over a set $\Gamma$ of prior distributions. Traditionally, Gamma-minimax estimation is defined for parametric models. In this paper, we define Gamma-minimaxity for general models and propose iterative algorithms with convergence guarantees to compute Gamma-minimax estimators for a general model space and a set of prior distributions constrained by generalized moments. We also propose encoding the space of candidate estimators by neural networks to enable flexible estimation. We illustrate our method in two settings, namely entropy estimation and a problem that arises in biodiversity studies.