Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscussion of Kallus and Mo, Qi, and Liu : New Objectives for Policy Learning
Paper and Code
Oct 09, 2020
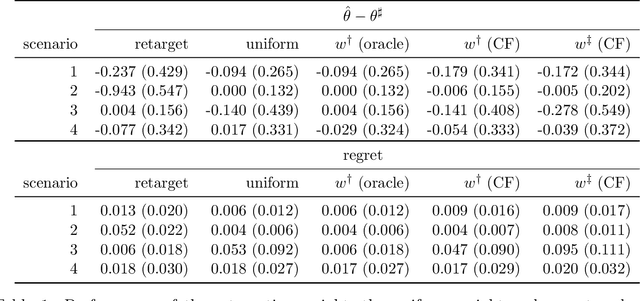
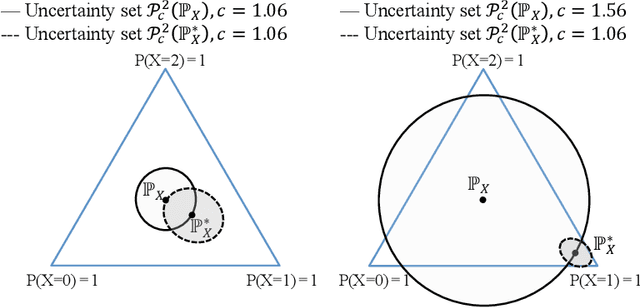

We discuss the thought-provoking new objective functions for policy learning that were proposed in "More efficient policy learning via optimal retargeting" by Nathan Kallus and "Learning optimal distributionally robust individualized treatment rules" by Weibin Mo, Zhengling Qi, and Yufeng Liu. We show that it is important to take the curvature of the value function into account when working within the retargeting framework, and we introduce two ways to do so. We also describe more efficient approaches for leveraging calibration data when learning distributionally robust policies.
* Submitted to the Journal of the American Statistical Association as
an invited discussion
View paper on