 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Treatment Effect Estimation in Semi-Supervised and High Dimensional Settings
Paper and Code
Jan 24, 2022
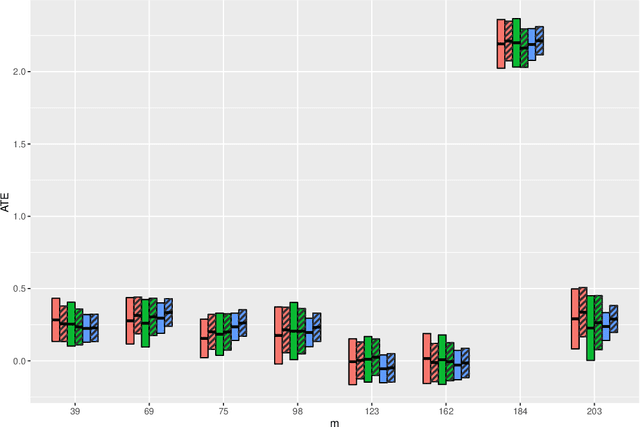
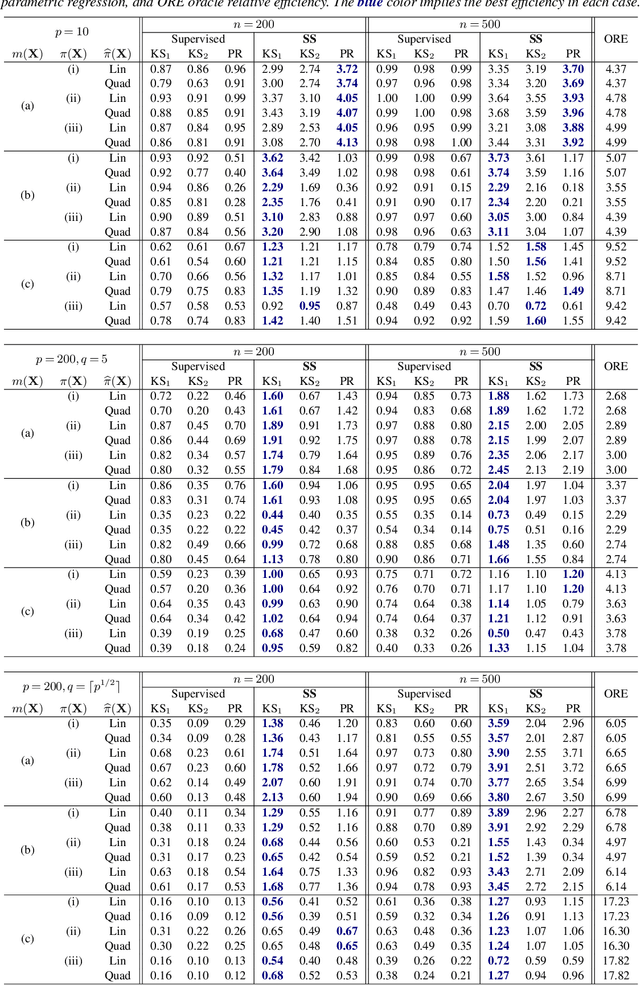
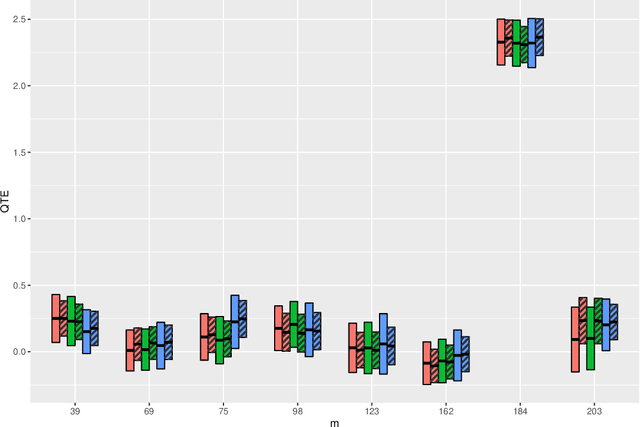
In this article, we aim to provide a general and complete understanding of semi-supervised (SS) causal inference for treatment effects. Specifically, we consider two such estimands: (a) the average treatment effect and (b) the quantile treatment effect, as prototype cases, in an SS setting, characterized by two available data sets: (i) a labeled data set of size $n$, providing observations for a response and a set of high dimensional covariates, as well as a binary treatment indicator; and (ii) an unlabeled data set of size $N$, much larger than $n$, but without the response observed. Using these two data sets, we develop a family of SS estimators which are ensured to be: (1) more robust and (2) more efficient than their supervised counterparts based on the labeled data set only. Beyond the 'standard' double robustness results (in terms of consistency) that can be achieved by supervised methods as well, we further establish root-n consistency and asymptotic normality of our SS estimators whenever the propensity score in the model is correctly specified, without requiring specific forms of the nuisance functions involved. Such an improvement of robustness arises from the use of the massive unlabeled data, so it is generally not attainable in a purely supervised setting. In addition, our estimators are shown to be semi-parametrically efficient as long as all the nuisance functions are correctly specified. Moreover, as an illustration of the nuisance estimators, we consider inverse-probability-weighting type kernel smoothing estimators involving unknown covariate transformation mechanisms, and establish in high dimensional scenarios novel results on their uniform convergence rates, which should be of independent interest. Numerical results on both simulated and real data validate the advantage of our methods over their supervised counterparts with respect to both robustness and efficiency.