 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Cross-Lingual Multi-Task Models at Qualtrics
Nov 29, 2022

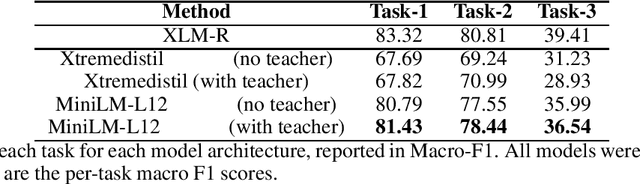
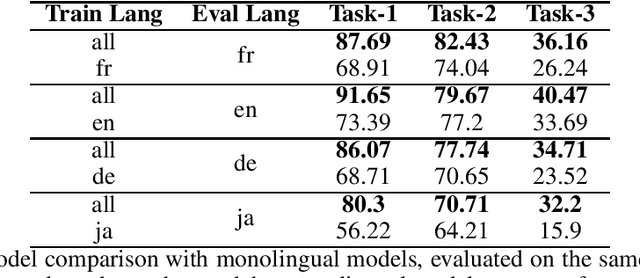
Experience management is an emerging business area where organizations focus on understanding the feedback of customers and employees in order to improve their end-to-end experiences. This results in a unique set of machine learning problems to help understand how people feel, discover issues they care about, and find which actions need to be taken on data that are different in content and distribution from traditional NLP domains. In this paper, we present a case study of building text analysis applications that perform multiple classification tasks efficiently in 12 languages in the nascent business area of experience management. In order to scale up modern ML methods on experience data, we leverage cross lingual and multi-task modeling techniques to consolidate our models into a single deployment to avoid overhead. We also make use of model compression and model distillation to reduce overall inference latency and hardware cost to the level acceptable for business needs while maintaining model prediction quality. Our findings show that multi-task modeling improves task performance for a subset of experience management tasks in both XLM-R and mBert architectures. Among the compressed architectures we explored, we found that MiniLM achieved the best compression/performance tradeoff. Our case study demonstrates a speedup of up to 15.61x with 2.60% average task degradation (or 3.29x speedup with 1.71% degradation) and estimated savings of 44% over using the original full-size model. These results demonstrate a successful scaling up of text classification for the challenging new area of ML for experience management.
Streaming Kernel Principal Component Analysis
Dec 16, 2015
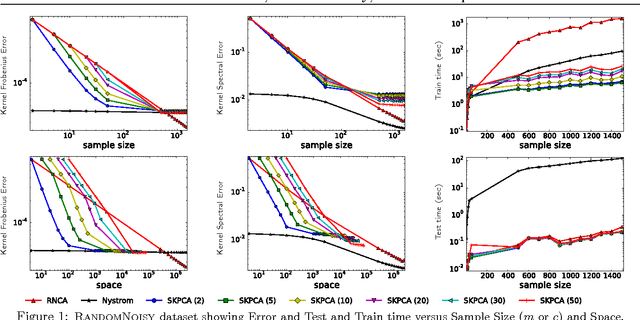
Kernel principal component analysis (KPCA) provides a concise set of basis vectors which capture non-linear structures within large data sets, and is a central tool in data analysis and learning. To allow for non-linear relations, typically a full $n \times n$ kernel matrix is constructed over $n$ data points, but this requires too much space and time for large values of $n$. Techniques such as the Nystr\"om method and random feature maps can help towards this goal, but they do not explicitly maintain the basis vectors in a stream and take more space than desired. We propose a new approach for streaming KPCA which maintains a small set of basis elements in a stream, requiring space only logarithmic in $n$, and also improves the dependence on the error parameter. Our technique combines together random feature maps with recent advances in matrix sketching, it has guaranteed spectral norm error bounds with respect to the original kernel matrix, and it compares favorably in practice to state-of-the-art approaches.