 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Security Control Production With Generative AI
Nov 06, 2024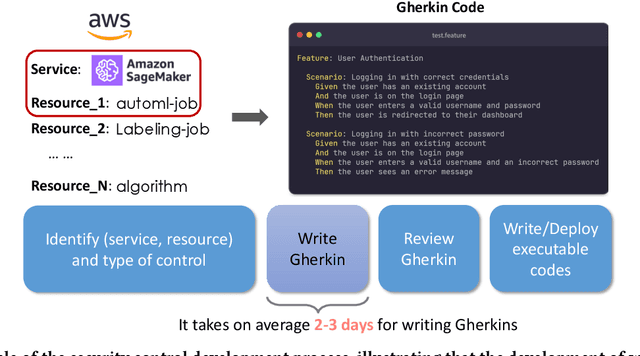

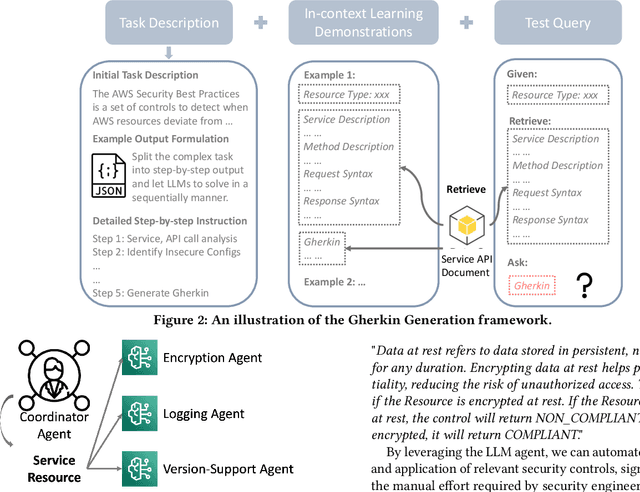
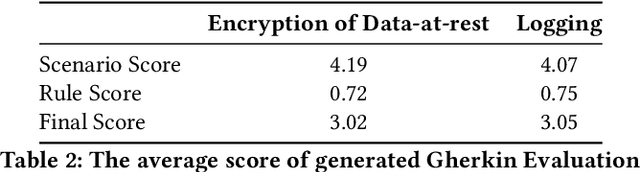
Security controls are mechanisms or policies designed for cloud based services to reduce risk, protect information, and ensure compliance with security regulations. The development of security controls is traditionally a labor-intensive and time-consuming process. This paper explores the use of Generative AI to accelerate the generation of security controls. We specifically focus on generating Gherkin codes which are the domain-specific language used to define the behavior of security controls in a structured and understandable format. By leveraging large language models and in-context learning, we propose a structured framework that reduces the time required for developing security controls from 2-3 days to less than one minute. Our approach integrates detailed task descriptions, step-by-step instructions, and retrieval-augmented generation to enhance the accuracy and efficiency of the generated Gherkin code. Initial evaluations on AWS cloud services demonstrate promising results, indicating that GenAI can effectively streamline the security control development process, thus providing a robust and dynamic safeguard for cloud-based infrastructures.
HLogformer: A Hierarchical Transformer for Representing Log Data
Aug 29, 2024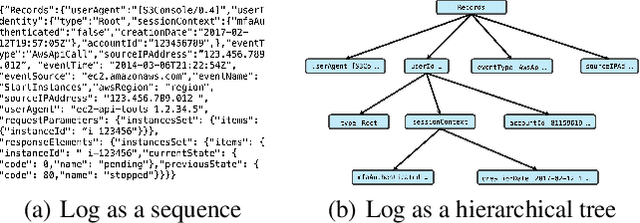
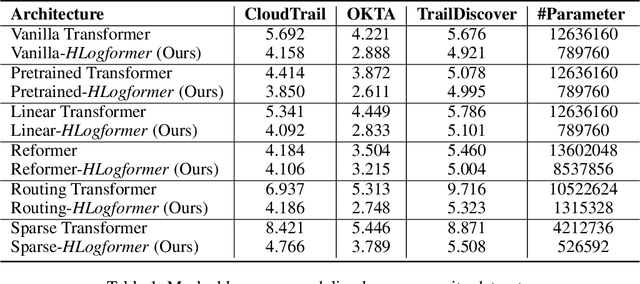
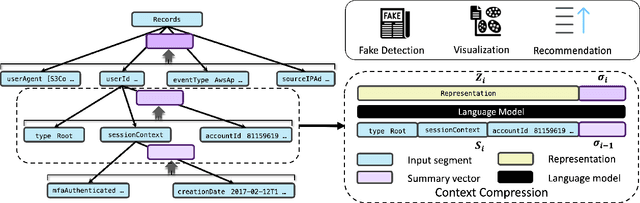
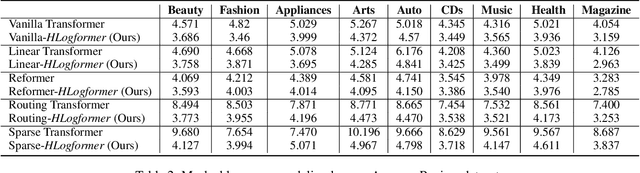
Transformers have gained widespread acclaim for their versatility in handling diverse data structures, yet their application to log data remains underexplored. Log data, characterized by its hierarchical, dictionary-like structure, poses unique challenges when processed using conventional transformer models. Traditional methods often rely on manually crafted templates for parsing logs, a process that is labor-intensive and lacks generalizability. Additionally, the linear treatment of log sequences by standard transformers neglects the rich, nested relationships within log entries, leading to suboptimal representations and excessive memory usage. To address these issues, we introduce HLogformer, a novel hierarchical transformer framework specifically designed for log data. HLogformer leverages the hierarchical structure of log entries to significantly reduce memory costs and enhance representation learning. Unlike traditional models that treat log data as flat sequences, our framework processes log entries in a manner that respects their inherent hierarchical organization. This approach ensures comprehensive encoding of both fine-grained details and broader contextual relationships. Our contributions are threefold: First, HLogformer is the first framework to design a dynamic hierarchical transformer tailored for dictionary-like log data. Second, it dramatically reduces memory costs associated with processing extensive log sequences. Third, comprehensive experiments demonstrate that HLogformer more effectively encodes hierarchical contextual information, proving to be highly effective for downstream tasks such as synthetic anomaly detection and product recommendation.
Low-cost Relevance Generation and Evaluation Metrics for Entity Resolution in AI
May 20, 2022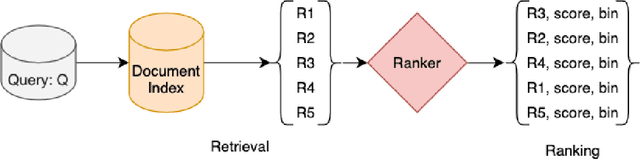


Entity Resolution (ER) in voice assistants is a prime component during run time that resolves entities in users request to real world entities. ER involves two major functionalities 1. Relevance generation and 2. Ranking. In this paper we propose a low cost relevance generation framework by generating features using customer implicit and explicit feedback signals. The generated relevance datasets can serve as test sets to measure ER performance. We also introduce a set of metrics that accurately measures the performance of ER systems in various dimensions. They provide great interpretability to deep dive and identifying root cause of ER issues, whether the problem is in relevance generation or ranking.
Streaming Kernel Principal Component Analysis
Dec 16, 2015
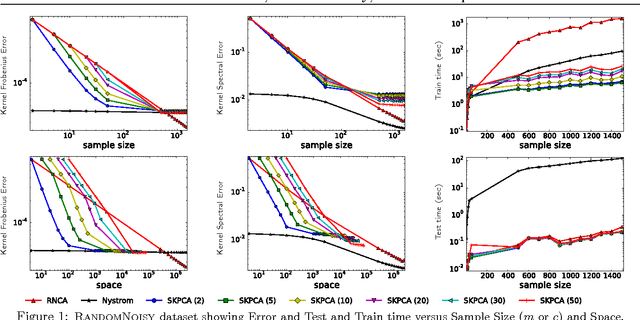
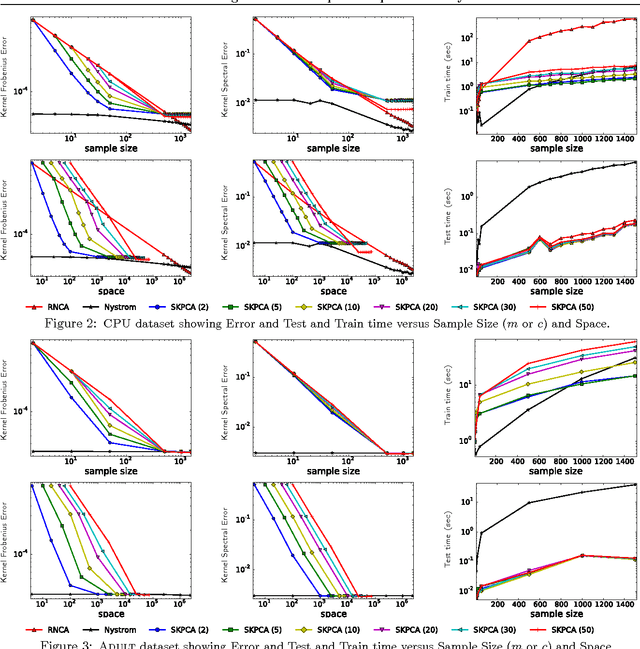
Kernel principal component analysis (KPCA) provides a concise set of basis vectors which capture non-linear structures within large data sets, and is a central tool in data analysis and learning. To allow for non-linear relations, typically a full $n \times n$ kernel matrix is constructed over $n$ data points, but this requires too much space and time for large values of $n$. Techniques such as the Nystr\"om method and random feature maps can help towards this goal, but they do not explicitly maintain the basis vectors in a stream and take more space than desired. We propose a new approach for streaming KPCA which maintains a small set of basis elements in a stream, requiring space only logarithmic in $n$, and also improves the dependence on the error parameter. Our technique combines together random feature maps with recent advances in matrix sketching, it has guaranteed spectral norm error bounds with respect to the original kernel matrix, and it compares favorably in practice to state-of-the-art approaches.