 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precision Characterization of Communication Disorders using Models of Perceived Pragmatic Similarity
Sep 13, 2024



The diagnosis and treatment of individuals with communication disorders offers many opportunities for the application of speech technology, but research so far has not adequately considered: the diversity of conditions, the role of pragmatic deficits, and the challenges of limited data. This paper explores how a general-purpose model of perceived pragmatic similarity may overcome these limitations. It explains how it might support several use cases for clinicians and clients, and presents evidence that a simple model can provide value, and in particular can capture utterance aspects that are relevant to diagnoses of autism and specific language impairment.
Which Prosodic Features Matter Most for Pragmatics?
Aug 23, 2024



We investigate which prosodic features matter most in conveying prosodic functions. We use the problem of predicting human perceptions of pragmatic similarity among utterance pairs to evaluate the utility of prosodic features of different types. We find, for example, that duration-related features are more important than pitch-related features, and that utterance-initial features are more important than utterance-final features. Further, failure analysis indicates that modeling using pitch features only often fails to handle important pragmatic functions, and suggests that several generally-neglected acoustic and prosodic features are pragmatically significant, including nasality and vibrato. These findings can guide future basic research in prosody, and suggest how to improve speech synthesis evaluation, among other applications.
Topics in the Study of the Pragmatic Functions of Phonetic Reduction in Dialog
May 02, 2024



Reduced articulatory precision is common in speech, but for dialog its acoustic properties and pragmatic functions have been little studied. We here try to remedy this gap. This technical report contains content that was omitted from the journal article (Ward et al. 2024, submitted). Specifically, we here report 1) lessons learned about annotating for perceived reduction, 2) the finding that, unlike in read speech, the correlates of reduction in dialog include high pitch, wide pitch range, and intensity, and 3) a baseline model for predicting reduction in dialog, using simple acoustic/prosodic features, that achieves correlations with human perceptions of 0.24 for English, and 0.17 for Spanish. We also provide examples of additional possible pragmatic functions of reduction in English, and various discussion, observations and speculations
A Collection of Pragmatic-Similarity Judgments over Spoken Dialog Utterances
Mar 21, 2024Automatic measures of similarity between utterances are invaluable for training speech synthesizers, evaluating machine translation, and assessing learner productions. While there exist measures for semantic similarity and prosodic similarity, there are as yet none for pragmatic similarity. To enable the training of such measures, we developed the first collection of human judgments of pragmatic similarity between utterance pairs. Each pair consisting of an utterance extracted from a recorded dialog and a re-enactment of that utterance. Re-enactments were done under various conditions designed to create a variety of degrees of similarity. Each pair was rated on a continuous scale by 6 to 9 judges. The average inter-judge correlation was as high as 0.72 for English and 0.66 for Spanish. We make this data available at https://github.com/divettemarco/PragSim .
Towards cross-language prosody transfer for dialog
Jul 09, 2023



Speech-to-speech translation systems today do not adequately support use for dialog purposes. In particular, nuances of speaker intent and stance can be lost due to improper prosody transfer. We present an exploration of what needs to be done to overcome this. First, we developed a data collection protocol in which bilingual speakers re-enact utterances from an earlier conversation in their other language, and used this to collect an English-Spanish corpus, so far comprising 1871 matched utterance pairs. Second, we developed a simple prosodic dissimilarity metric based on Euclidean distance over a broad set of prosodic features. We then used these to investigate cross-language prosodic differences, measure the likely utility of three simple baseline models, and identify phenomena which will require more powerful modeling. Our findings should inform future research on cross-language prosody and the design of speech-to-speech translation systems capable of effective prosody transfer.
Dialogs Re-enacted Across Languages
Nov 18, 2022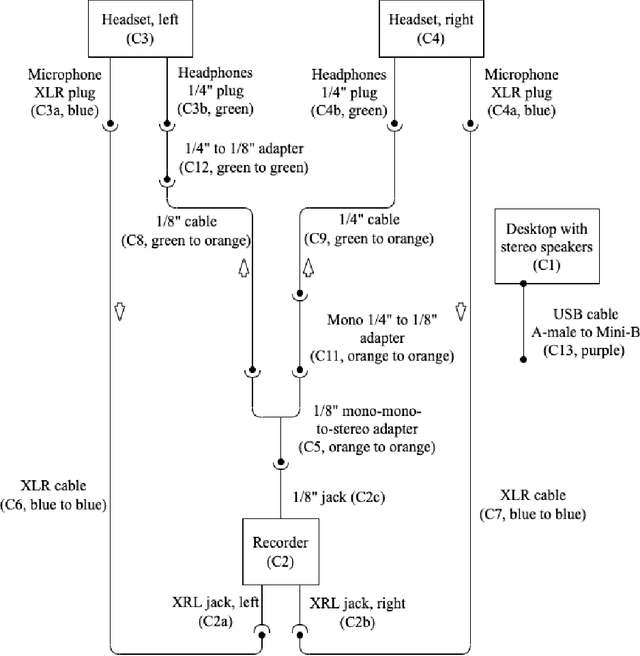
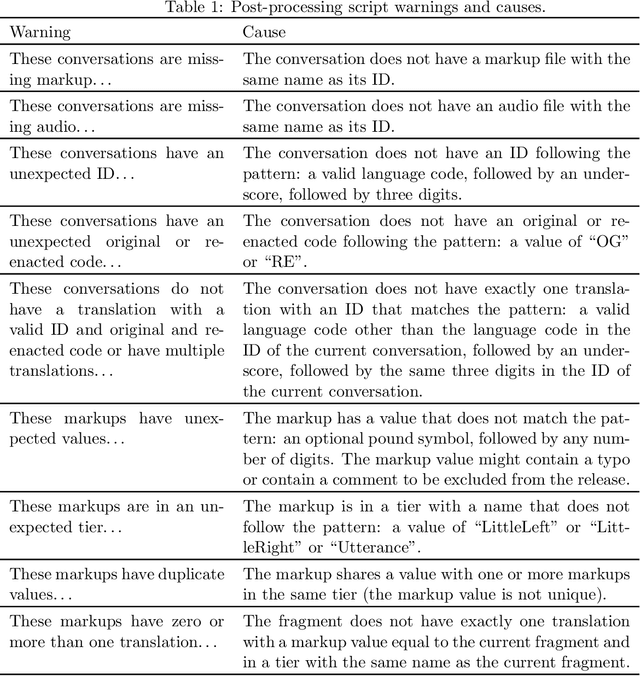

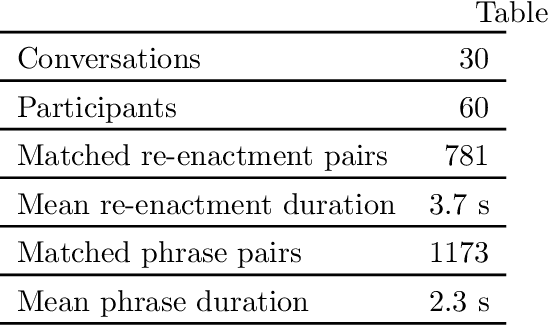
To support machine learning of cross-language prosodic mappings and other ways to improve speech-to-speech translation, we present a protocol for collecting closely matched pairs of utterances across languages, a description of the resulting data collection, and some observations and musings. This report is intended for 1) people using the corpus, 2) people extending the corpus, and 3) people designing similar collections of bilingual dialog data.
On the Utility of Self-supervised Models for Prosody-related Tasks
Oct 13, 2022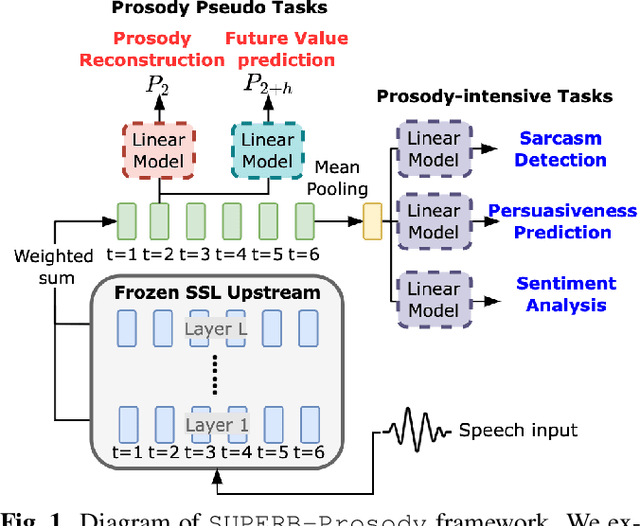
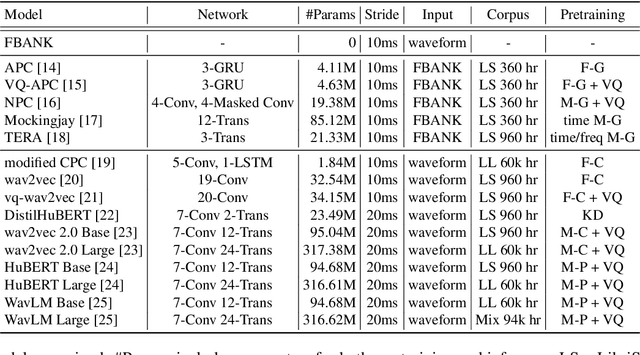
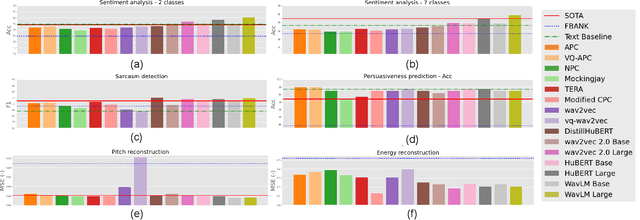
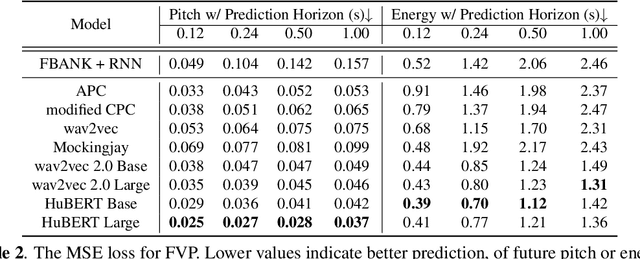
Self-Supervised Learning (SSL) from speech data has produced models that have achieved remarkable performance in many tasks, and that are known to implicitly represent many aspects of information latently present in speech signals. However, relatively little is known about the suitability of such models for prosody-related tasks or the extent to which they encode prosodic information. We present a new evaluation framework, SUPERB-prosody, consisting of three prosody-related downstream tasks and two pseudo tasks. We find that 13 of the 15 SSL models outperformed the baseline on all the prosody-related tasks. We also show good performance on two pseudo tasks: prosody reconstruction and future prosody prediction. We further analyze the layerwise contributions of the SSL models. Overall we conclude that SSL speech models are highly effective for prosody-related tasks.