 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards cross-language prosody transfer for dialog
Jul 09, 2023



Speech-to-speech translation systems today do not adequately support use for dialog purposes. In particular, nuances of speaker intent and stance can be lost due to improper prosody transfer. We present an exploration of what needs to be done to overcome this. First, we developed a data collection protocol in which bilingual speakers re-enact utterances from an earlier conversation in their other language, and used this to collect an English-Spanish corpus, so far comprising 1871 matched utterance pairs. Second, we developed a simple prosodic dissimilarity metric based on Euclidean distance over a broad set of prosodic features. We then used these to investigate cross-language prosodic differences, measure the likely utility of three simple baseline models, and identify phenomena which will require more powerful modeling. Our findings should inform future research on cross-language prosody and the design of speech-to-speech translation systems capable of effective prosody transfer.
Dialogs Re-enacted Across Languages
Nov 18, 2022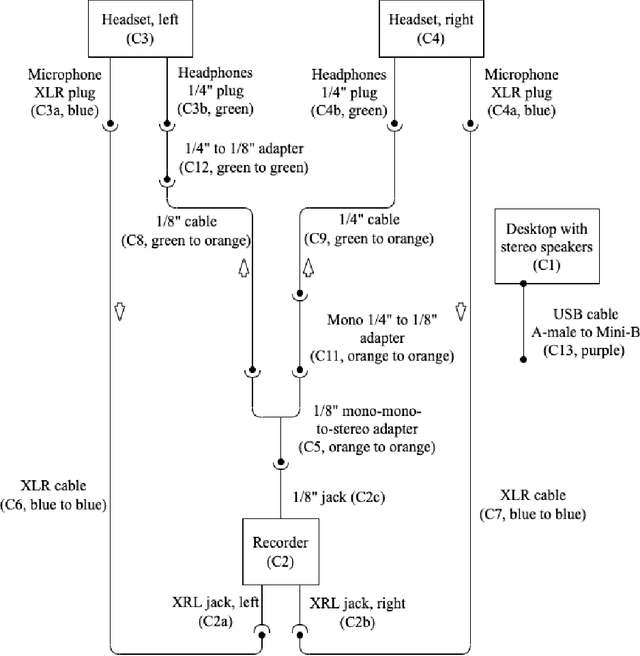
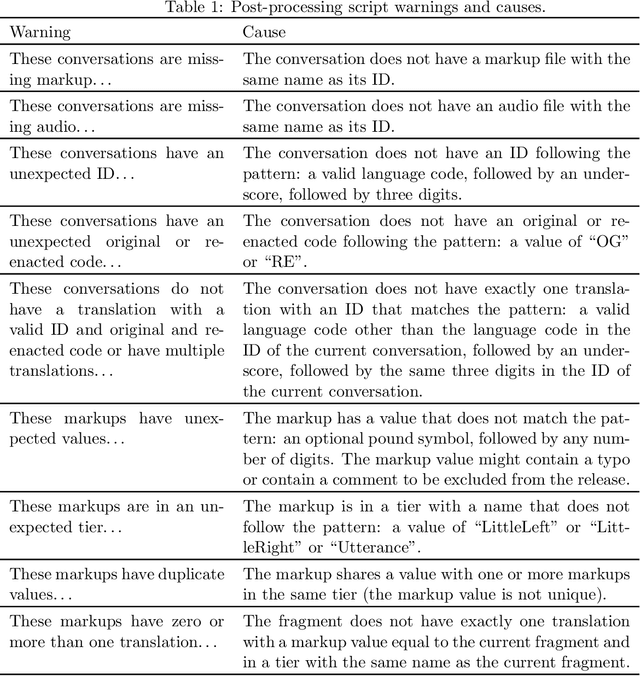

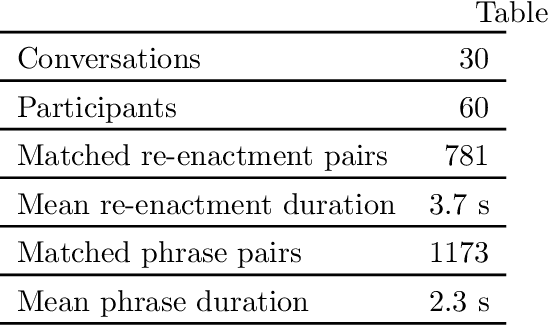
To support machine learning of cross-language prosodic mappings and other ways to improve speech-to-speech translation, we present a protocol for collecting closely matched pairs of utterances across languages, a description of the resulting data collection, and some observations and musings. This report is intended for 1) people using the corpus, 2) people extending the corpus, and 3) people designing similar collections of bilingual dialog data.