Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogs Re-enacted Across Languages
Paper and Code
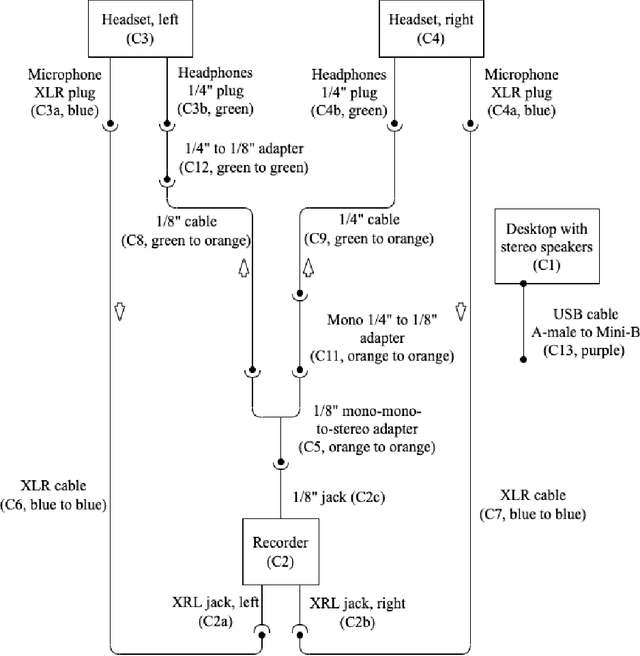
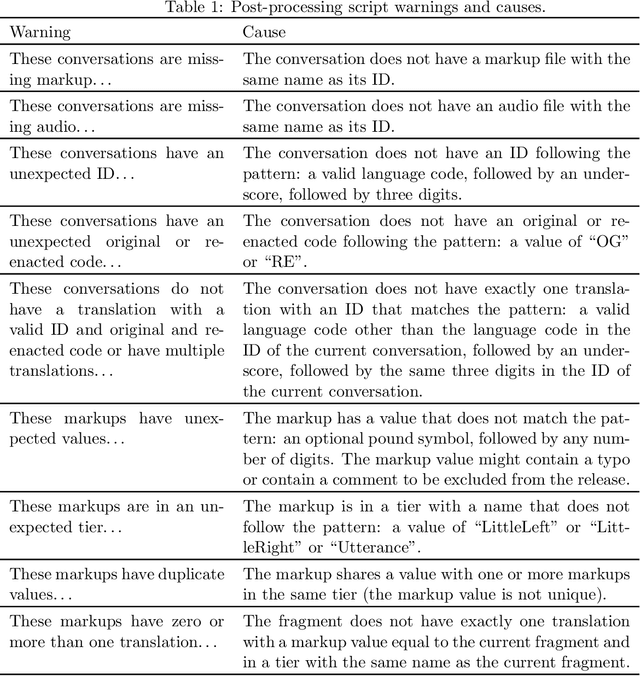

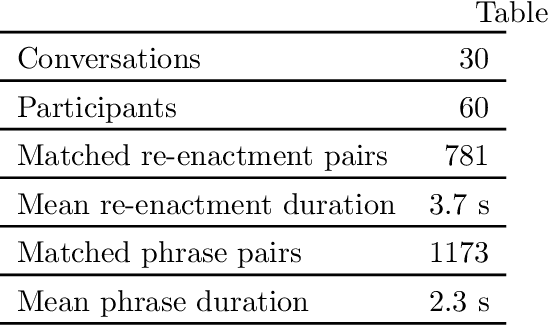
To support machine learning of cross-language prosodic mappings and other ways to improve speech-to-speech translation, we present a protocol for collecting closely matched pairs of utterances across languages, a description of the resulting data collection, and some observations and musings. This report is intended for 1) people using the corpus, 2) people extending the corpus, and 3) people designing similar collections of bilingual dialog data.
View paper on