 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Paper and Code
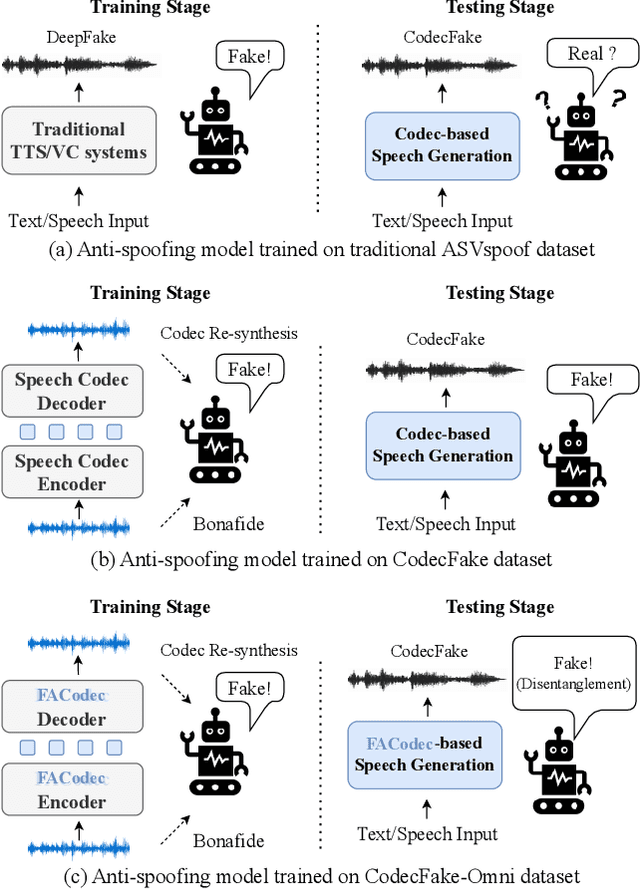
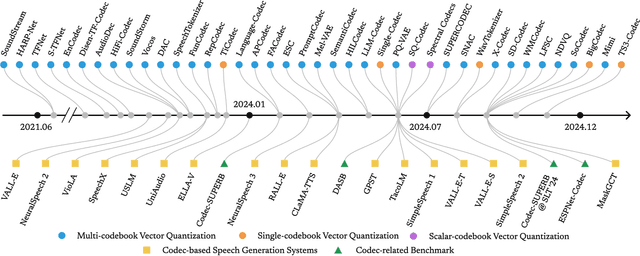

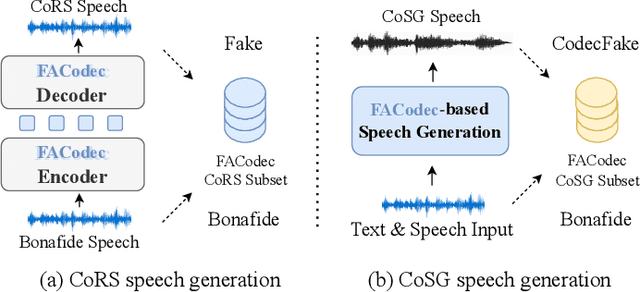
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.