 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Test-time Adaptation for End-to-end Speech Recognition on Noisy Speech
Paper and Code
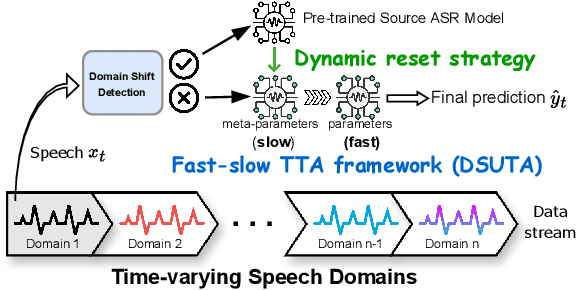
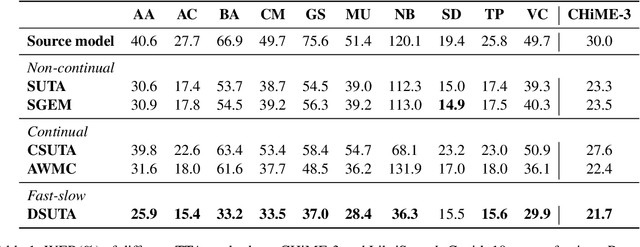
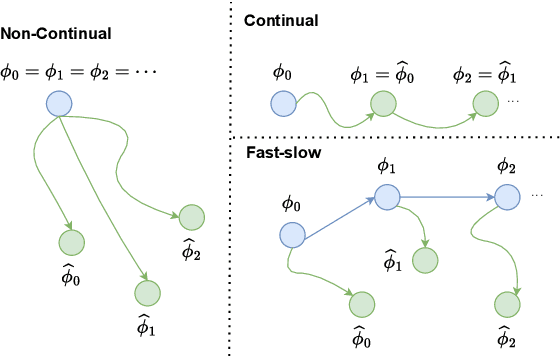
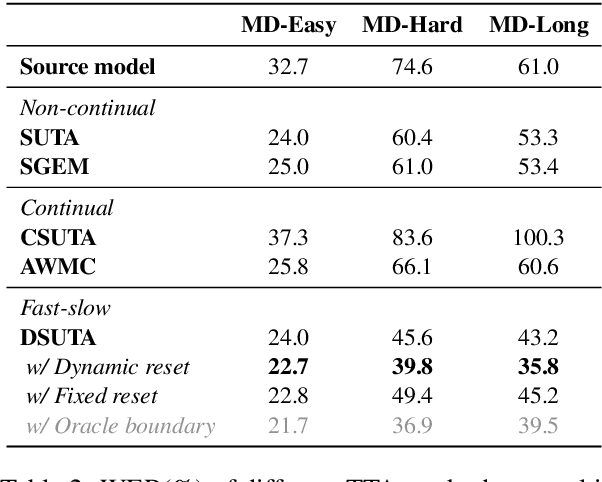
Deep learning-based end-to-end automatic speech recognition (ASR) has made significant strides but still struggles with performance on out-of-domain (OOD) samples due to domain shifts in real-world scenarios. Test-Time Adaptation (TTA) methods address this issue by adapting models using test samples at inference time. However, current ASR TTA methods have largely focused on non-continual TTA, which limits cross-sample knowledge learning compared to continual TTA. In this work, we propose a Fast-slow TTA framework for ASR, which leverages the advantage of continual and non-continual TTA. Within this framework, we introduce Dynamic SUTA (DSUTA), an entropy-minimization-based continual TTA method for ASR. To enhance DSUTA's robustness on time-varying data, we propose a dynamic reset strategy that automatically detects domain shifts and resets the model, making it more effective at handling multi-domain data. Our method demonstrates superior performance on various noisy ASR datasets, outperforming both non-continual and continual TTA baselines while maintaining robustness to domain changes without requiring domain boundary information.